Download to read offline
















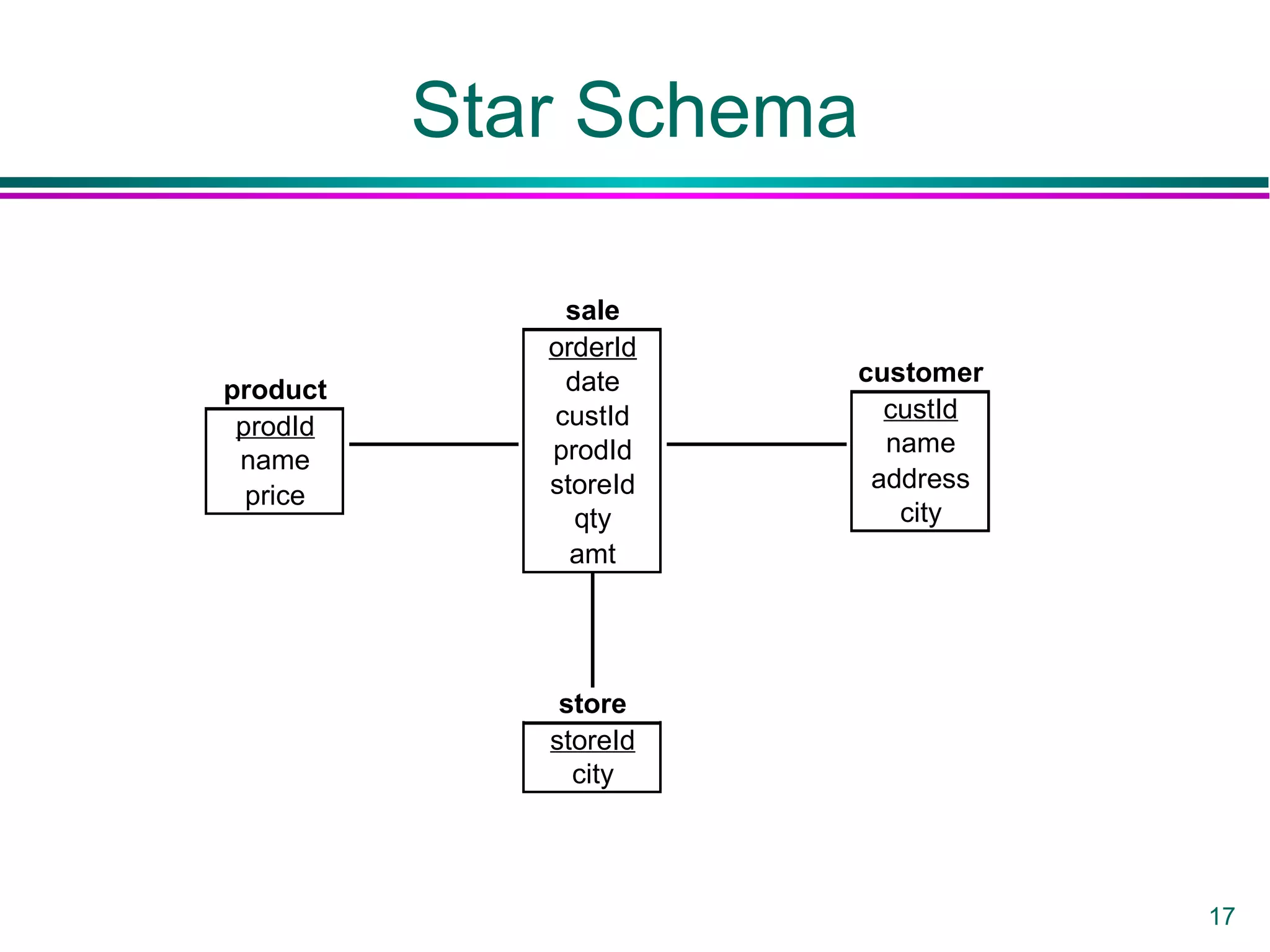

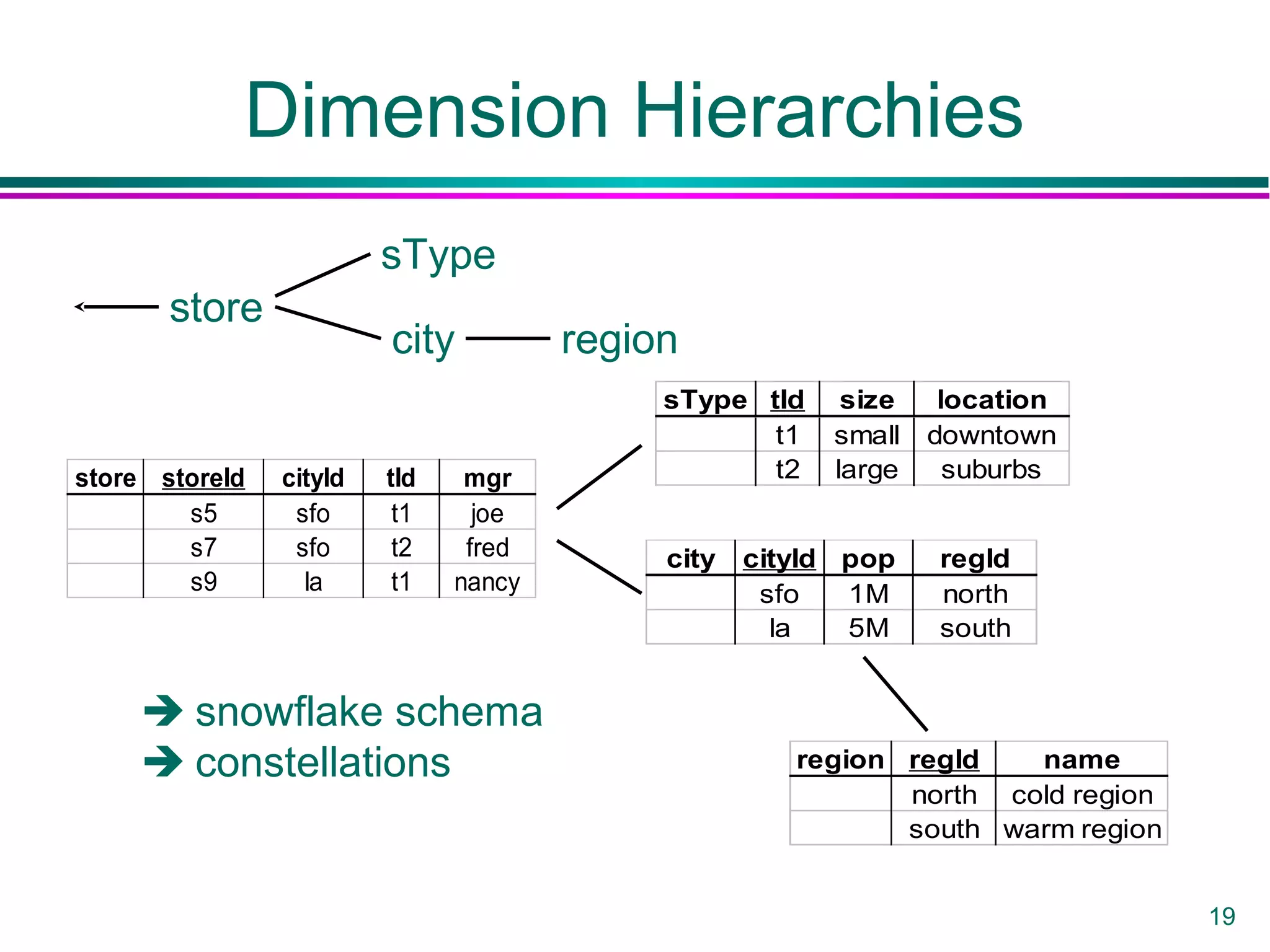








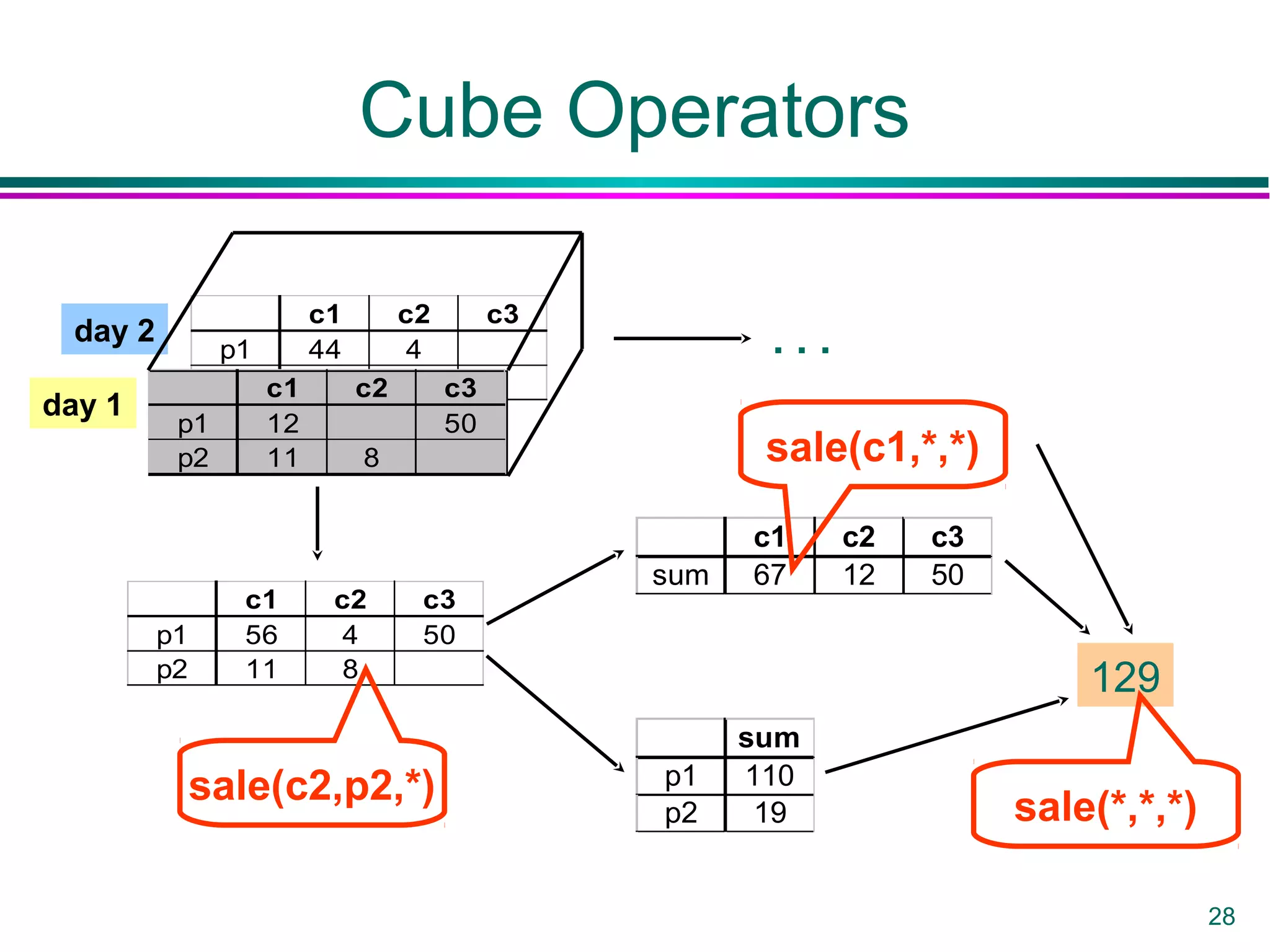

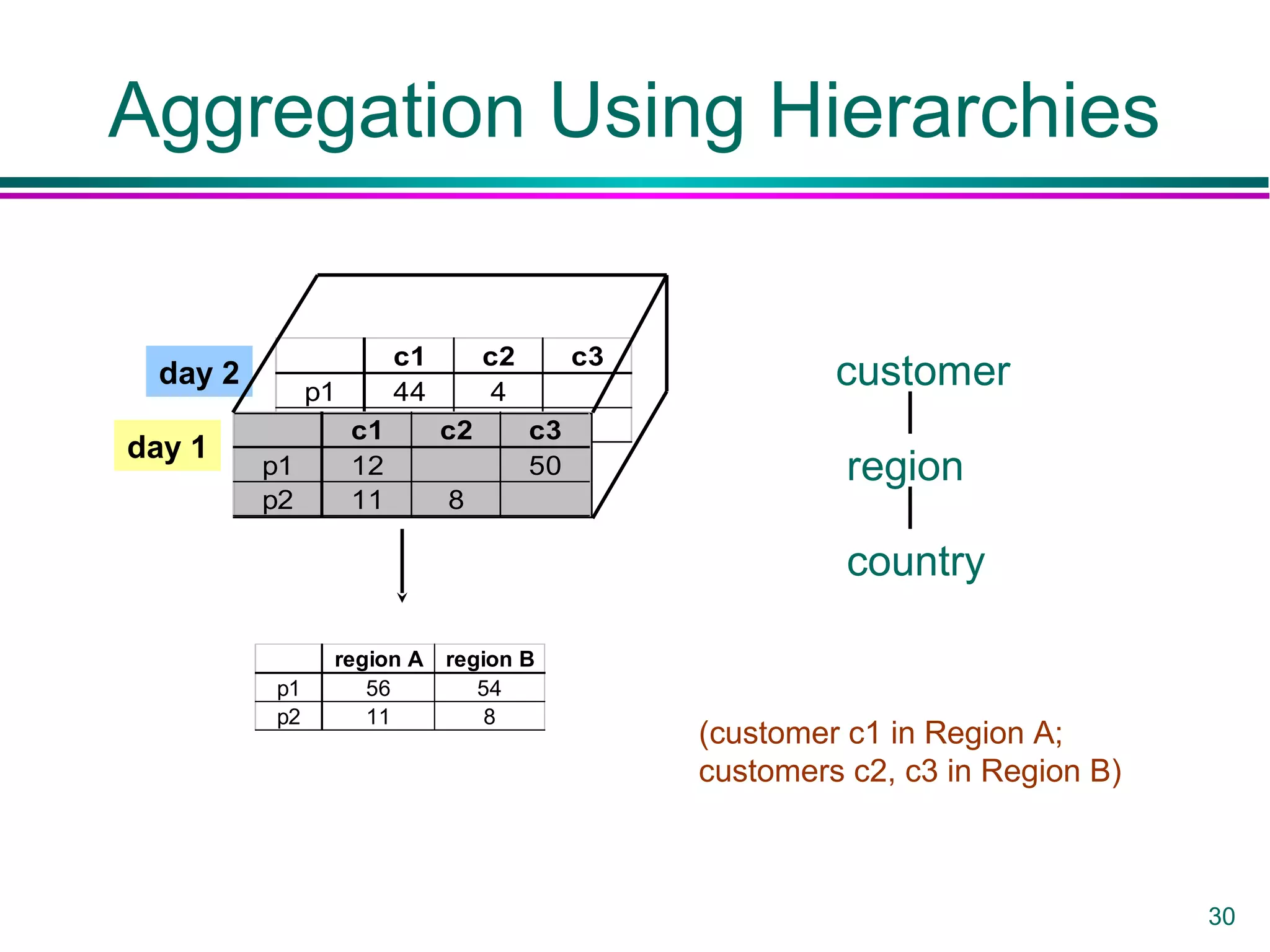



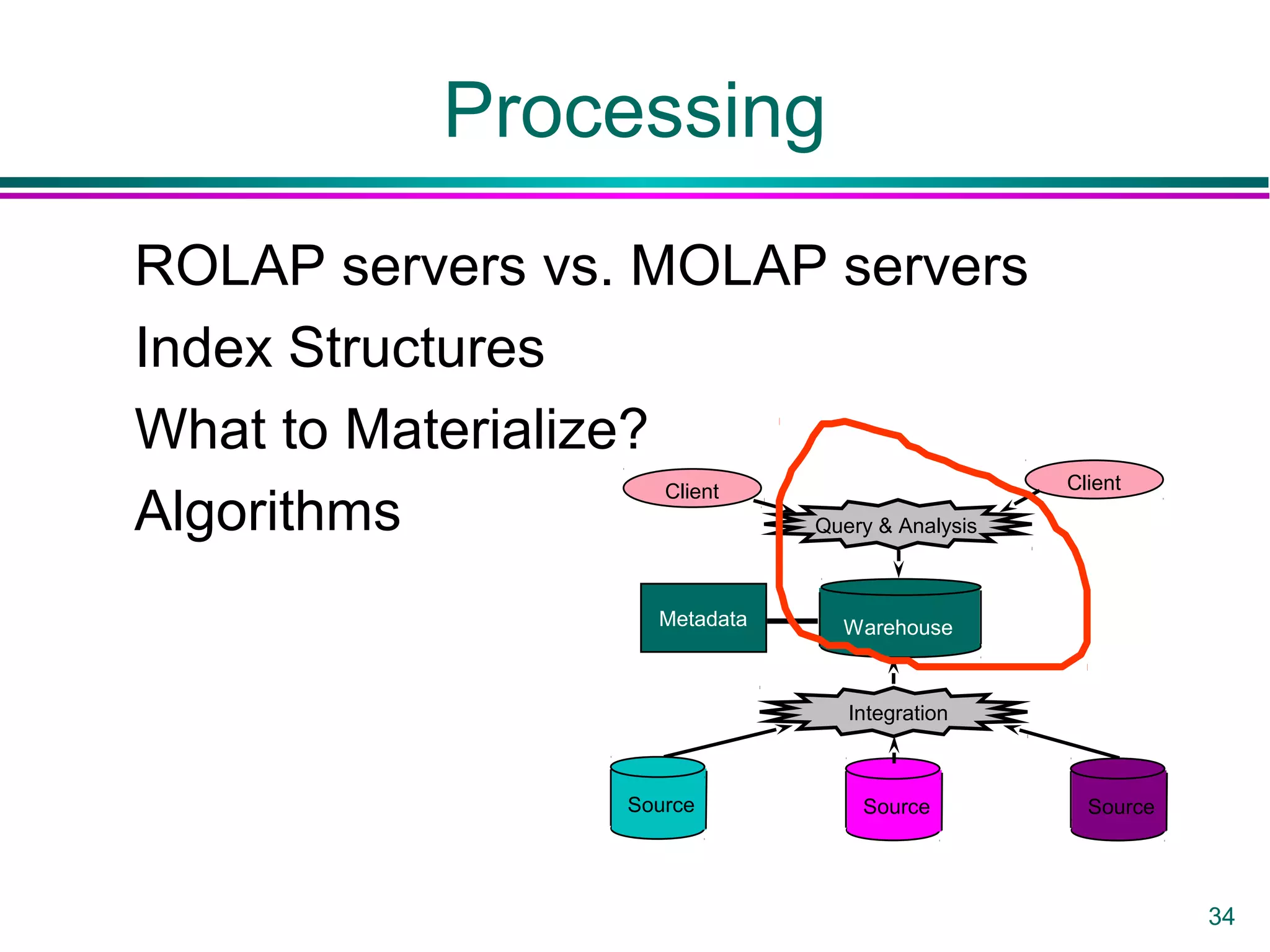








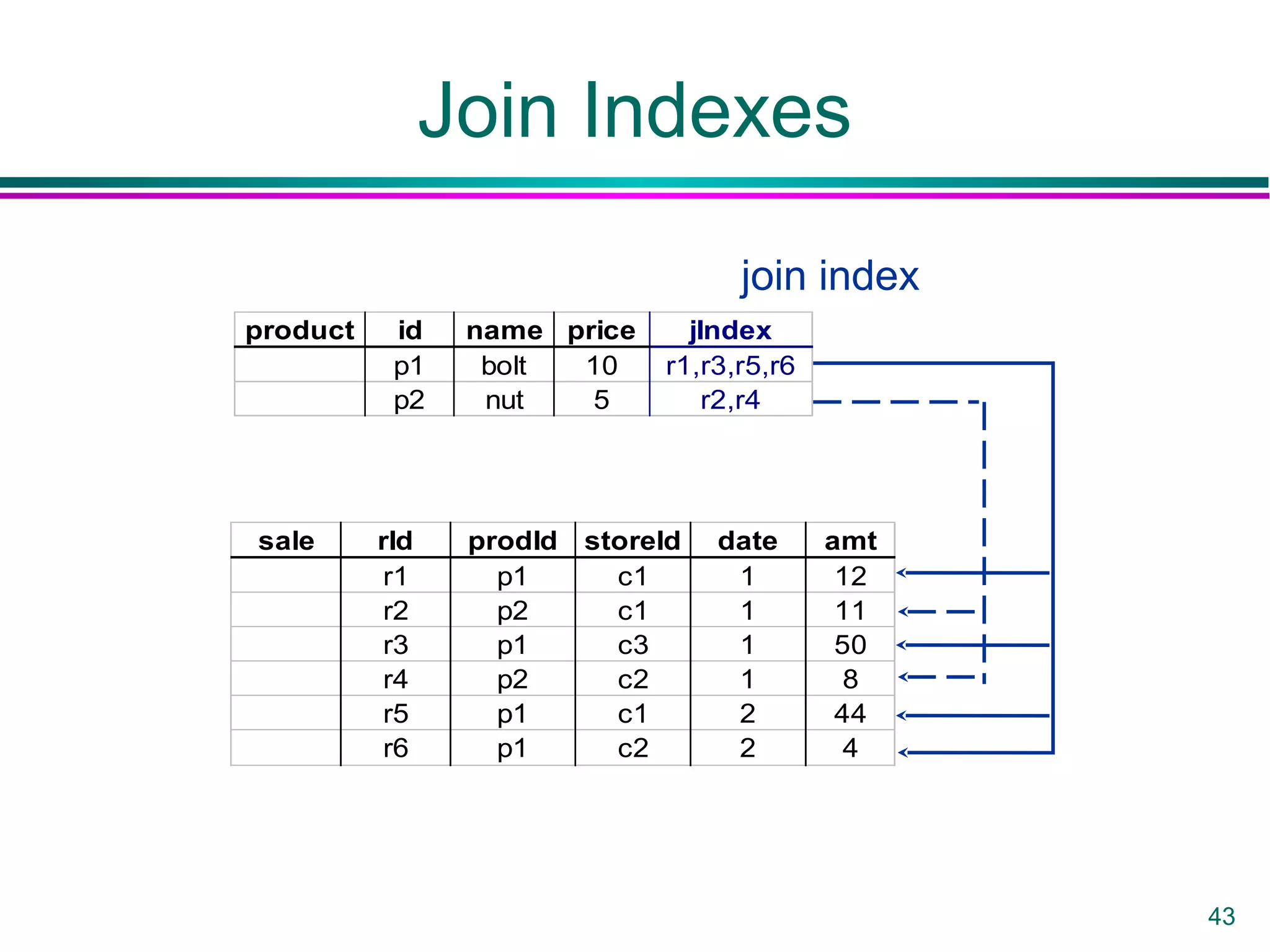
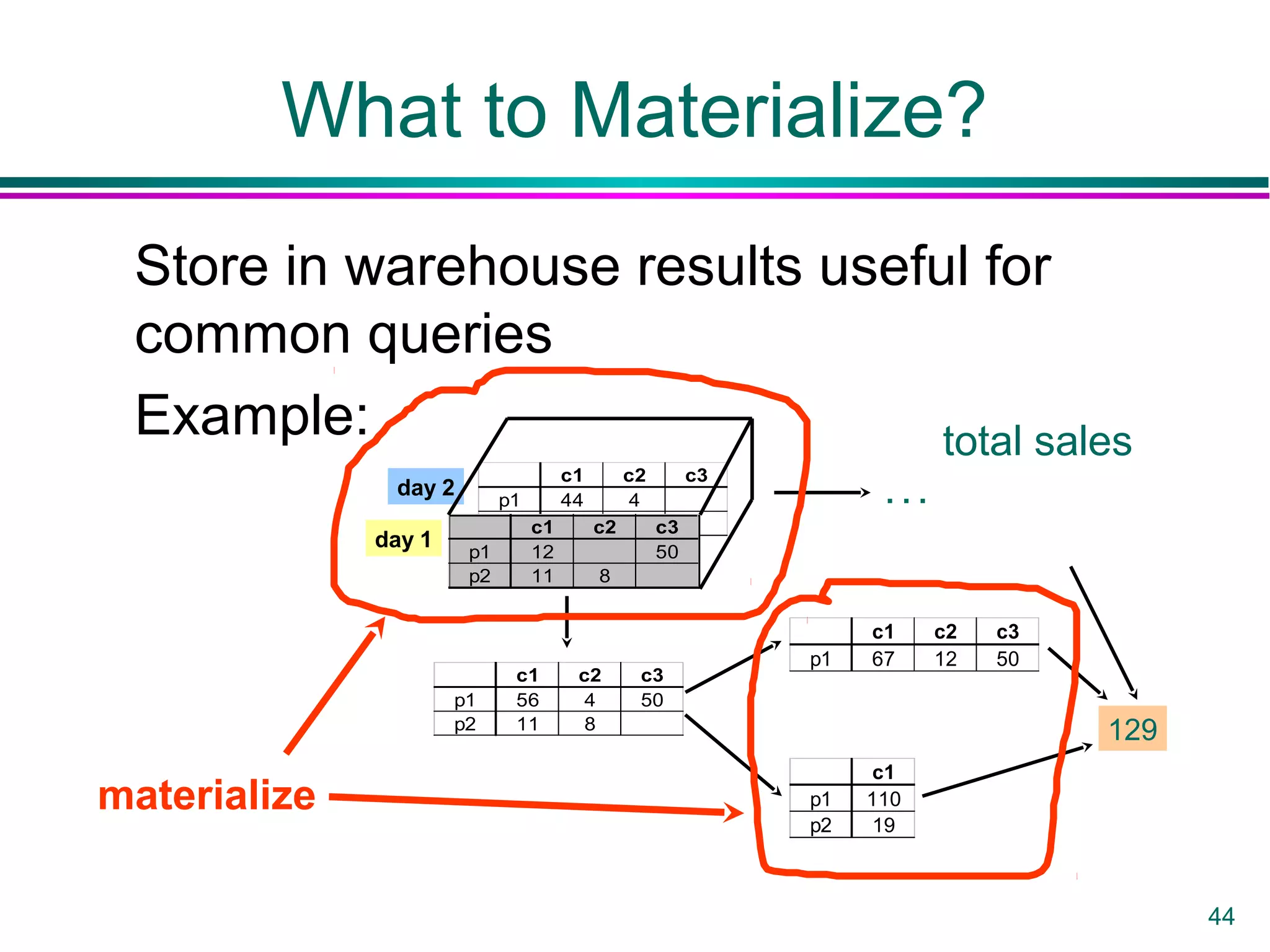

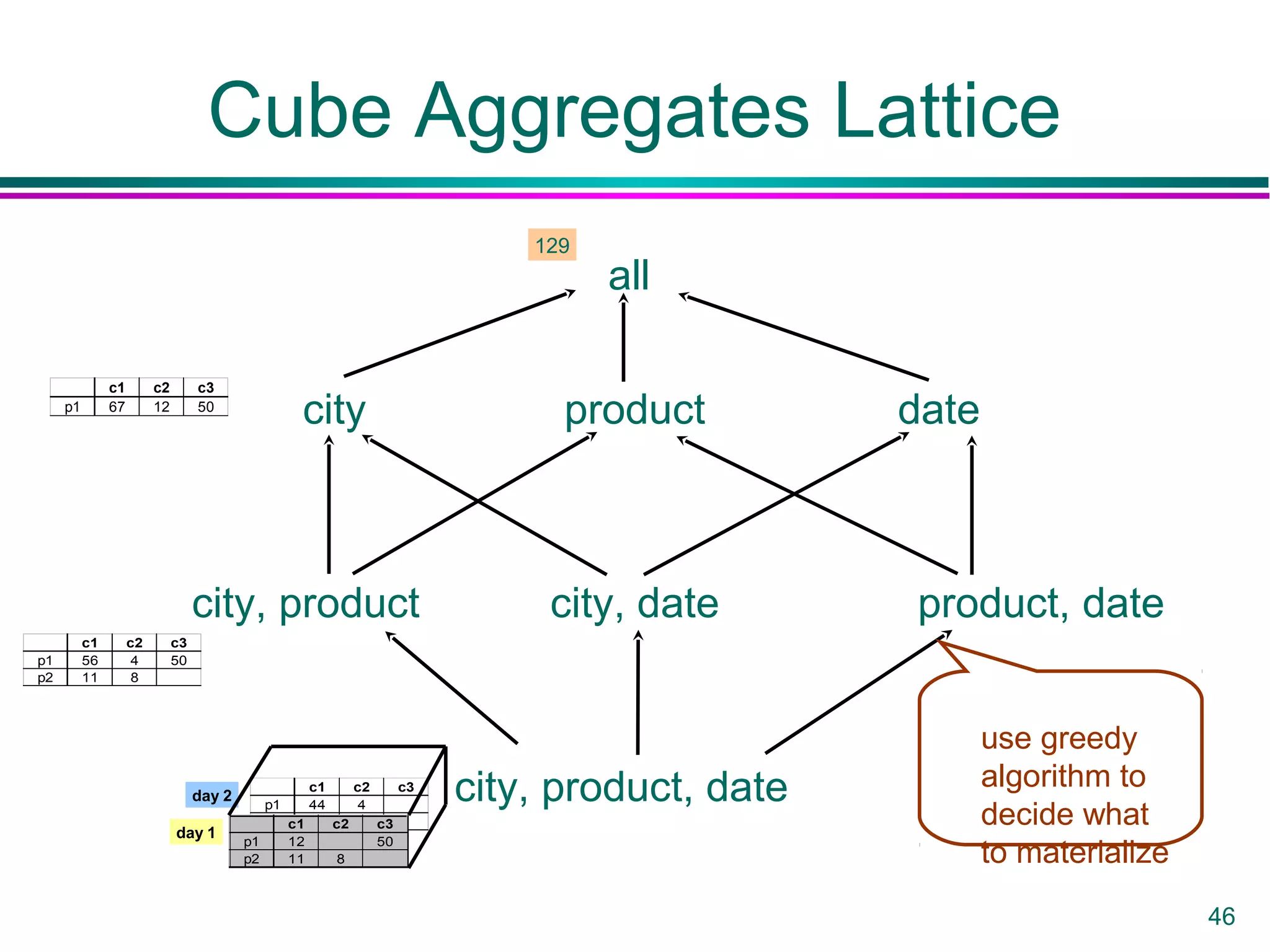
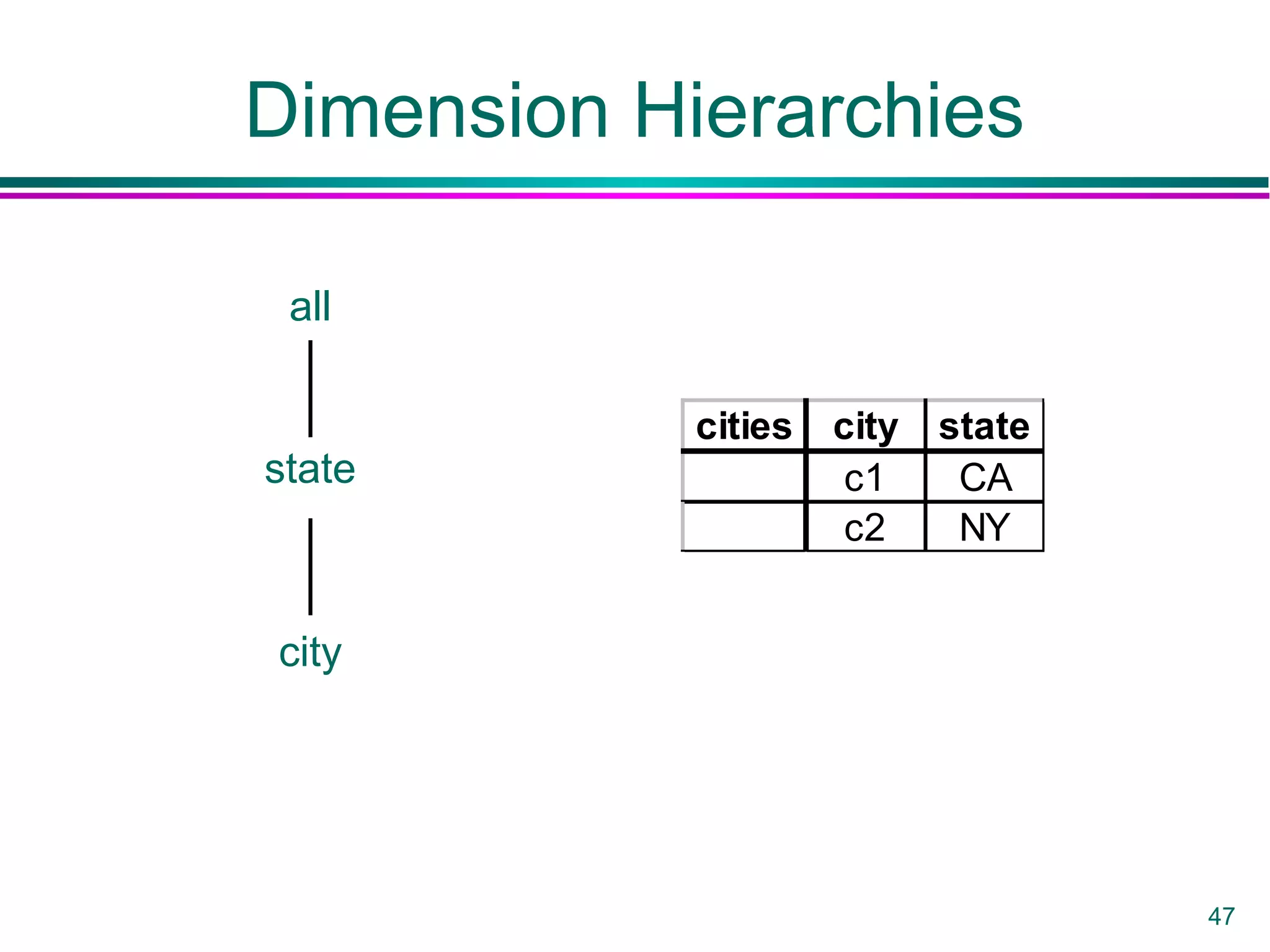
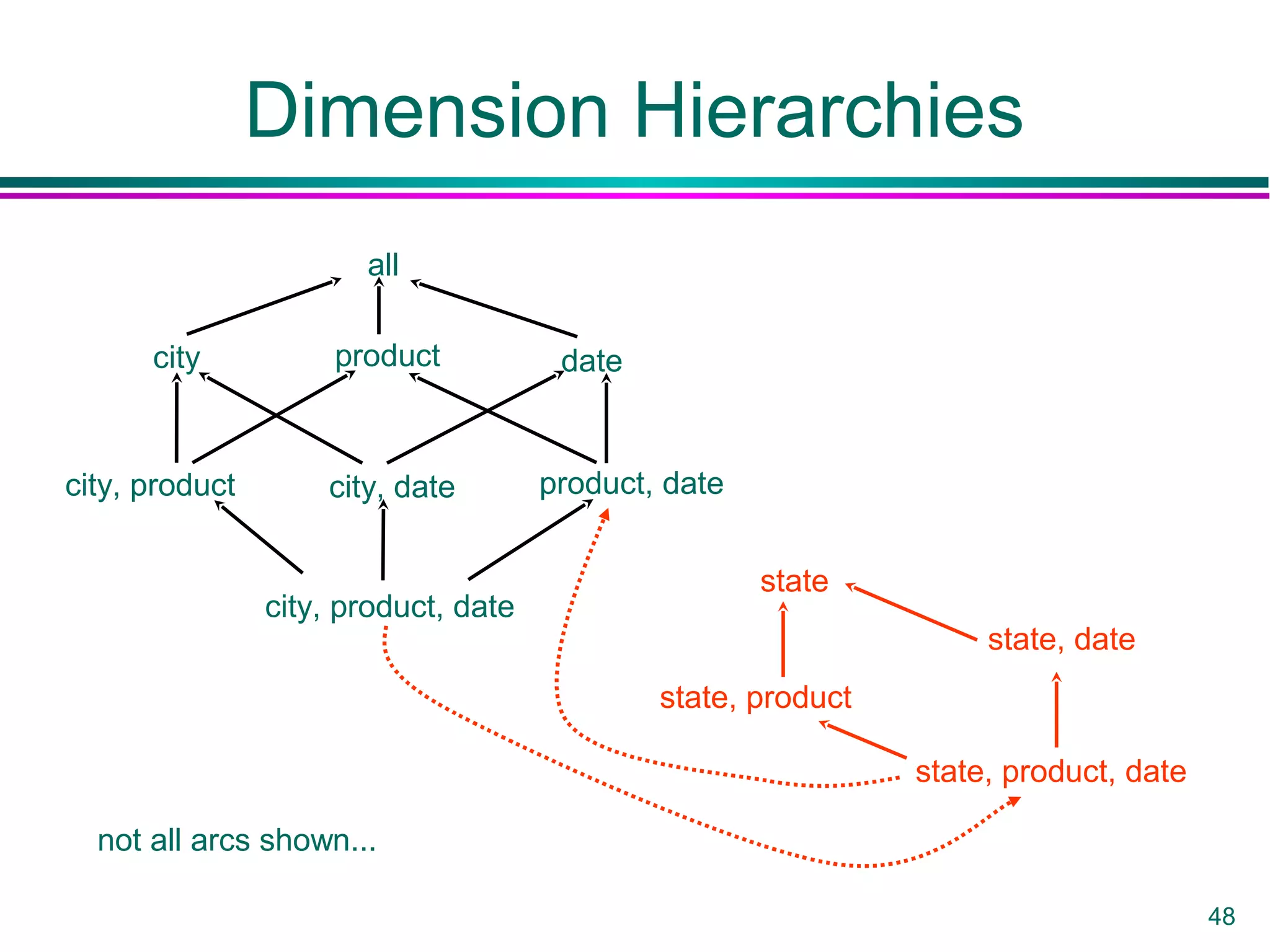


This document provides an overview of data warehousing. It defines a data warehouse as a collection of diverse data aimed at executives and decision makers that is integrated, time-varying, and non-volatile. It discusses why warehouses are used, different warehouse architectures and models, and operations like aggregation, pivoting and materializing views. Key benefits of warehouses include high query performance, flexibility to query data not in a DBMS, and ability to operate when sources are unavailable.















































