Download to read offline





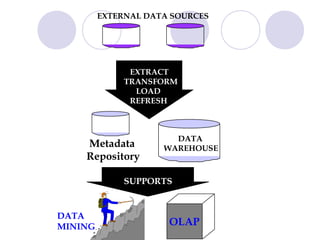
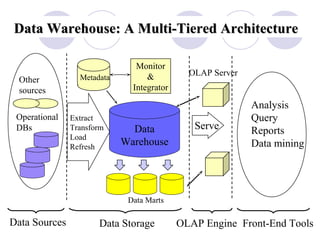

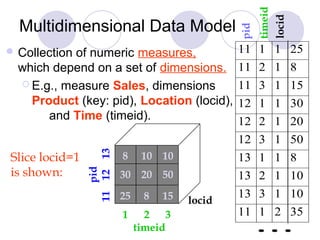

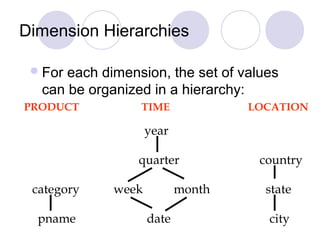












This document discusses data warehousing and online analytic processing (OLAP). It introduces key concepts such as data warehouses, OLAP, multidimensional data models, dimension hierarchies, and OLAP queries including roll-up, drill-down, pivoting, slicing and dicing. It also covers implementation issues such as indexing techniques and view maintenance to enable interactive queries for OLAP.


































![Tugas 2[1]](https://cdn.slidesharecdn.com/ss_thumbnails/tugas21-161004165952-thumbnail.jpg?width=640&height=640&fit=bounds)








































































