Downloaded 10 times

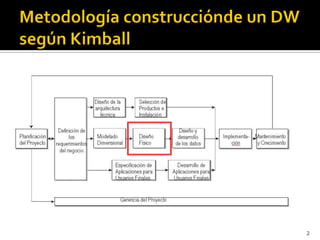









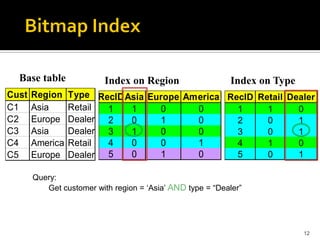


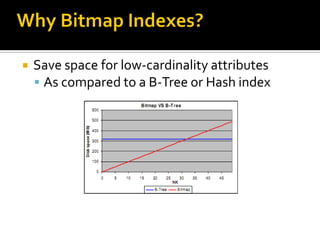




The document discusses different types of indexes that can be used in data warehousing for efficient data access and query processing. It describes indexes like B-trees, hash tables, and bitmap indexes. It also covers multi-column indexes, covering indexes, and join indexes which are particularly useful in data warehousing to optimize queries involving filters, aggregations, and joins.






































