Downloaded 285 times














![Logical Plan
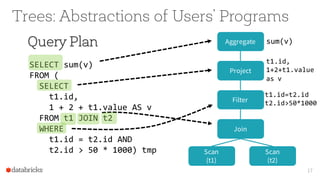
• A Logical Plan describescomputation
on datasets without defining how to
conductthe computation
• output: a list of attributes generated
by this Logical Plan, e.g. [id, v]
• constraints: a setof invariants about
the rows generatedby this plan, e.g.
t2.id > 50 * 1000
18
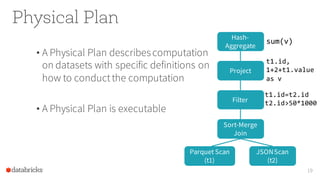
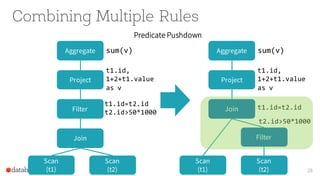
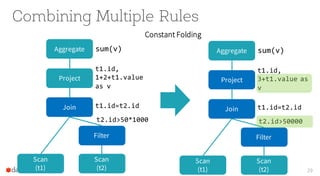
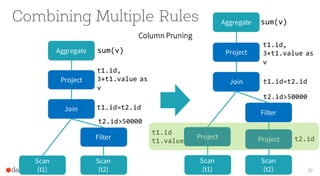
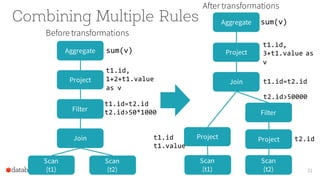
Scan
(t1)
Scan
(t2)
Join
Filter
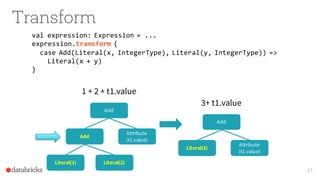
Project
Aggregate sum(v)
t1.id,
1+2+t1.value
as v
t1.id=t2.id
t2.id>50*1000](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-18-320.jpg)




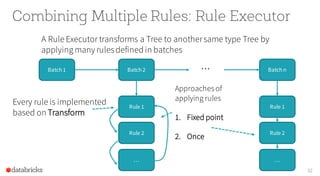

![From Logical Plan to Physical Plan
• A Logical Plan is transformedto a Physical Plan by applying
a set of Strategies
• Every Strategy uses patternmatchingto converta Tree to
anotherkind of Tree
34
object BasicOperators extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
…
case logical.Project(projectList, child) =>
execution.ProjectExec(projectList, planLater(child)) :: Nil
case logical.Filter(condition, child) =>
execution.FilterExec(condition, planLater(child)) :: Nil
…
}
} Triggers other Strategies](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-34-320.jpg)
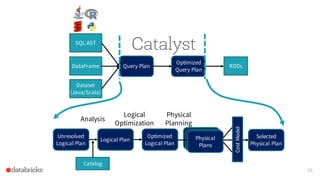

![Ensure Requirements on Input Rows
38
Sort-MergeJoin
[t1.id = t2.id]
t1
Requirements:
Rows Sorted by t1.id
t2
Requirements:
Rows Sorted by t2.id](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-38-320.jpg)
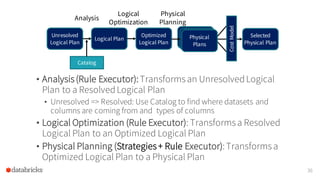
![Ensure Requirements on Input Rows
39
Sort-MergeJoin
[t1.id = t2.id]
t1
Requirements:
Rows Sorted by t1.id
Requirements:
Rows Sorted by t2.id
Sort
[t1.id]
t2
Sort
[t2.id]](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-39-320.jpg)
![Ensure Requirements on Input Rows
40
Sort-MergeJoin
[t1.id = t2.id]
t1
[sortedby t1.id]
Requirements:
Rows Sorted by t1.id
Requirements:
Rows Sorted by t2.id
Sort
[t1.id]
t2
Sort
[t2.id]What if t1 has been
sorted by t1.id?](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-40-320.jpg)
![Ensure Requirements on Input Rows
41
Sort-MergeJoin
[t1.id = t2.id]
t1
[sortedby t1.id]
Requirements:
Rows Sorted by t1.id
Requirements:
Rows Sorted by t2.id
t2
Sort
[t2.id]](https://image.slidesharecdn.com/catalystyinhuaifinal-160608233303/85/Deep-Dive-Into-Catalyst-Apache-Spark-2-0-s-Optimizer-41-320.jpg)

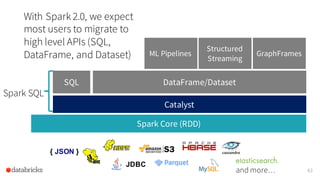






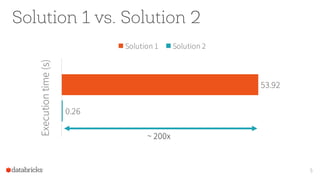
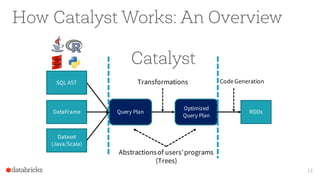
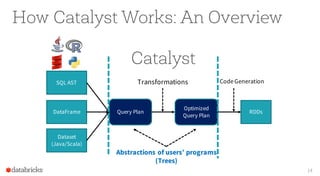
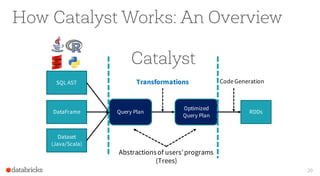
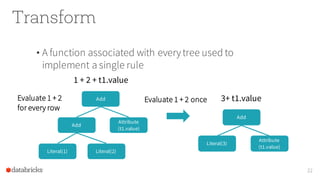
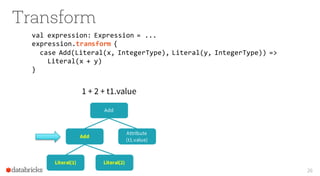
The document presents an overview of Apache Spark 2.0's Catalyst optimizer, emphasizing automatic optimization of programs written with high-level APIs like SQL and DataFrames. It compares two solutions for counting elements from joined tables, highlighting differences in execution time and efficiency. The presentation also discusses how Catalyst processes query plans through abstraction, logical and physical plan transformations, and optimization strategies.




























































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)


![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)











