Download to read offline









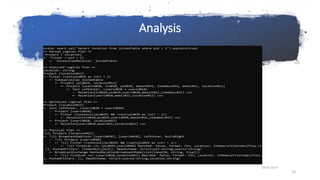








![Sample CombineFilter rule from spark source
code
object CombineFilters extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case ff @ Filter(fc, nf @ Filter(nc, grandChild)) => Filter(And(nc, fc), grandChild)
}
}
08-03-2019
23](https://image.slidesharecdn.com/catalystoptimizer-190308041357/85/Catalyst-optimizer-23-320.jpg)
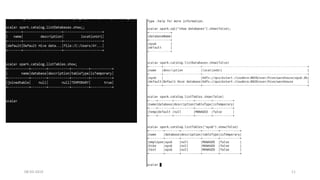
![Custom rules
object MultiplyOptimizationRule extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
case Multiply(left,right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Double] == 1.0 =>
println("optimization of one applied")
left
}
}
08-03-2019
24](https://image.slidesharecdn.com/catalystoptimizer-190308041357/85/Catalyst-optimizer-24-320.jpg)
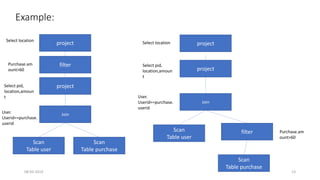
![Custom rules
val purchase=spark.read.option("header",true).option("delimiter","t").csv("purchase.txt");
val purchaseamount = purchase.selectExpr("amount * 1")
println(purchaseamount.queryExecution.optimizedPlan.numberedTreeString)
00 Project [(cast(amount#3 as double) * 1.0) AS (amount * 1)#5]
01 +- Relation[tid#10,pid#11,userid#12,amount#3,itemdesc#14] csv
sparkSession.experimental.extraOptimizations = Seq(MultiplyOptimizationRule)
val purchaseamount = purchase.selectExpr("amount * 1")
println(purchaseamount.queryExecution.optimizedPlan.numberedTreeString)
00 Project [cast(amount#3 as double) AS (amount * 1)#7]
01 +- Relation[tid#10,pid#11,userid#12,amount#3,itemdesc#14] csv
08-03-2019
25](https://image.slidesharecdn.com/catalystoptimizer-190308041357/85/Catalyst-optimizer-25-320.jpg)


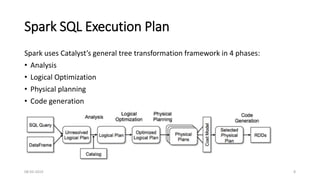
Catalyst optimizer optimizes queries written in Spark SQL and DataFrame API to run faster. It uses both rule-based and cost-based optimization. Rule-based optimization applies rules to determine query execution, while cost-based generates multiple plans and selects the most efficient. Catalyst optimizer transforms logical plans through four phases - analysis, logical optimization, physical planning, and code generation. It represents queries as trees that can be manipulated using pattern matching rules to optimize queries.



































































