Download as PDF, PPTX












![labs Data Engineering | Fast Data
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]) {
val inputFile = args(0)
val outputFile = args(1)
val spark = SparkSession.builder().appName("Hello World").getOrCreate()
// Create a Scala Spark Context.
val sc = spark.sparkContext
// Load our input data.
val input = sc.textFile(inputFile)
// Split up into words.
val words = input.flatMap(line => line.split(" "))
// Transform into word and count.
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// Save the word count back out to a text file, causing evaluation.
counts.saveAsTextFile(outputFile)
}
}](https://image.slidesharecdn.com/apache-spark-training-month-of-data-engineering-v-181018070744/85/An-Introduction-to-Spark-with-Scala-16-320.jpg)


![labs Data Engineering | Fast Data
Strongly Typing
Ability to use powerful lambda functions.
Spark SQL’s optimized execution engine (catalyst, tungsten)
Can be constructed from JVM objects & manipulated using Functional
transformations (map, filter, flatMap etc)
A DataFrame is a Dataset organized into named columns
DataFrame is simply a type alias of Dataset[Row]](https://image.slidesharecdn.com/apache-spark-training-month-of-data-engineering-v-181018070744/85/An-Introduction-to-Spark-with-Scala-19-320.jpg)

![labs Data Engineering | Fast Data
DataFrame
Dataset
Untyped API
Typed API
Dataset
(2016)
DataFrame = Dataset [Row]
Alias
Dataset [T]](https://image.slidesharecdn.com/apache-spark-training-month-of-data-engineering-v-181018070744/85/An-Introduction-to-Spark-with-Scala-21-320.jpg)

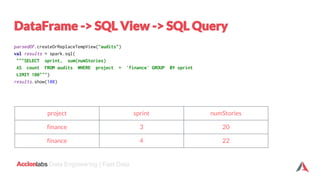

![labs Data Engineering | Fast Data
val employeesDF = spark.read.json("employees.json")
// Convert data to domain objects.
case class Employee(name: String, age: Int)
val employeesDS: Dataset[Employee] = employeesDF.as[Employee]
val filterDS = employeesDS.filter(p => p.age > 3)
Type-safe: operate on domain
objects with compiled lambda
functions.](https://image.slidesharecdn.com/apache-spark-training-month-of-data-engineering-v-181018070744/85/An-Introduction-to-Spark-with-Scala-26-320.jpg)
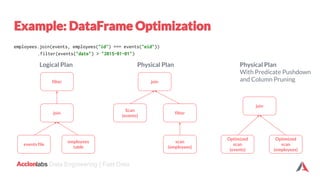
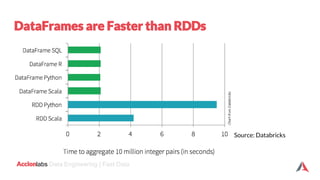
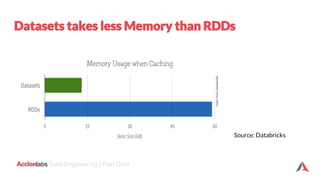





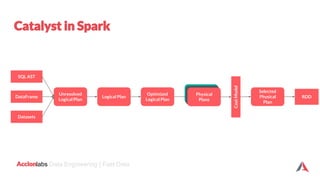
The document provides an introduction to Apache Spark and Scala. It discusses that Apache Spark is a fast and general-purpose cluster computing system that provides high-level APIs for Scala, Java, Python and R. It supports structured data processing using Spark SQL, graph processing with GraphX, and machine learning using MLlib. Scala is a modern programming language that is object-oriented, functional, and type-safe. The document then discusses Resilient Distributed Datasets (RDDs), DataFrames, and Datasets in Spark and how they provide different levels of abstraction and functionality. It also covers Spark operations and transformations, and how the Spark logical query plan is optimized into a physical execution plan.























































































