Download as PDF, PPTX







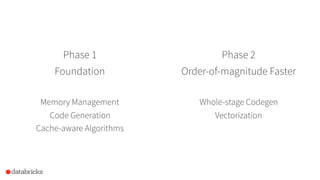




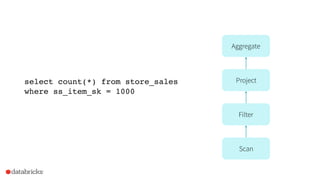




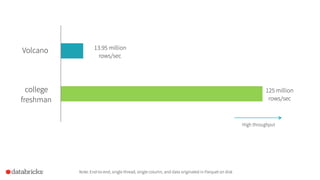


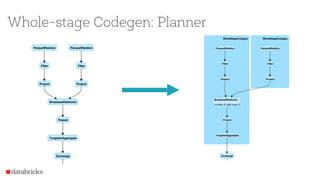




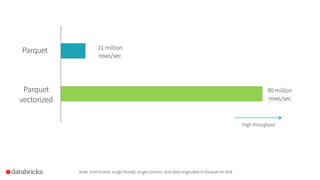

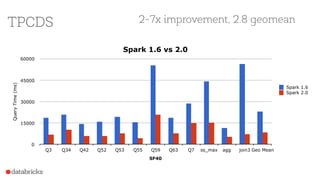




Project Tungsten aims to enhance Spark's memory and CPU efficiency through improved execution techniques rather than optimization. It involves a two-phase approach focused on manual memory management, code generation, and cache-aware algorithms to achieve significant performance boosts. The initiative also emphasizes columnar data formats to leverage modern CPU capabilities, with preliminary results showing substantial improvements over previous versions of Spark.























































































