Downloaded 299 times



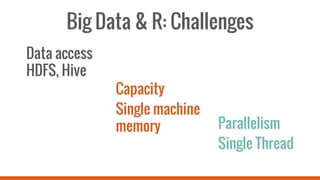

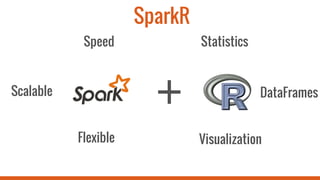



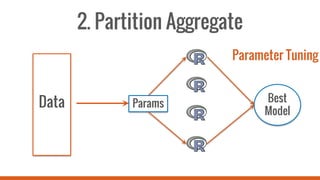
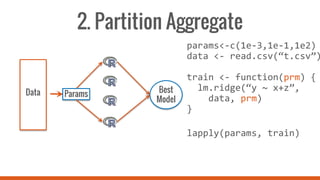
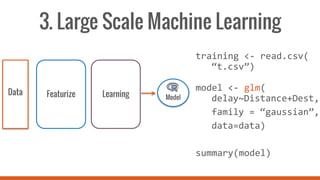












This document introduces SparkR, which allows users to perform big data processing from R. It discusses how SparkR enables data exploration using DataFrames for ETL and data cleaning. SparkR also supports advanced analytics like machine learning by integrating R with Spark MLlib. The tutorial outlines exploring data, advanced analytics, and using SparkR DataFrames for tasks like aggregation, filtering, visualization with ggplot, and large-scale machine learning. It recommends signing up for an online Databricks notebook to run SparkR examples and tutorials interactively on a dedicated Spark cluster.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



