Download as PDF, PPTX







![Example ML Workflow
Training
Train
model
labels
+
predicEons
Evaluate
Load
data
labels
+
plain
text
labels
+
feature
vectors
Extract
features
Explicitly
unzip
&
zip
RDDs
labels.zip(predictions).map {
if (_._1 == _._2) ...
}
val features: RDD[Vector]
val predictions: RDD[Double]
Create
many
RDDs
val labels: RDD[Double] =
data.map(_.label)
Pain
point](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-8-320.jpg)






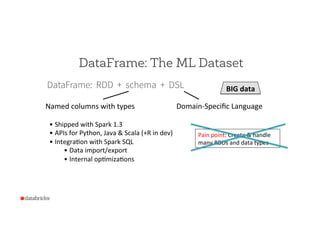
![DataFrame: The ML Dataset
DataFrame: RDD + schema + DSL
Named
columns
with
types
label: Double
text: String
words: Seq[String]
features: Vector
prediction: Double
label
text
words
features
0
This
is
...
[“This”,
“is”,
…]
[0.5,
1.2,
…]
0
When
we
...
[“When”,
...]
[1.9,
-‐0.8,
…]](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-15-320.jpg)








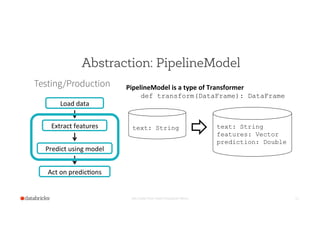

![Demo
Set Footer from Insert Dropdown Menu 27
Transformer
DataFrame
Estimator
Evaluator
label: Double
text: String
features: Vector
Current
data
schema
prediction: Double
Training
Logis'cRegression
BinaryClassifica'on
Evaluator
Load
data
Tokenizer
Transformer HashingTF
words: Seq[String]](https://image.slidesharecdn.com/15-03-18ssemlpipelines-150325000457-conversion-gate01/85/Practical-Machine-Learning-Pipelines-with-MLlib-27-320.jpg)








The document presents a detailed overview of practical machine learning workflows using Spark MLlib, which aims to simplify the development of scalable machine learning applications. It discusses the key components of ML workflows such as data preparation, model training, evaluation, and the integration of pipelines introduced in Spark 1.2 and 1.3. Additionally, it highlights the challenges faced in machine learning processes and the solutions provided through new abstractions like dataframes and estimators.

















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)





