Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PDF, PPTX
10,493 views
[DL輪読会]Deep Learning 第15章 表現学習
2017/12/11 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Read more
12
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 33
2
/ 33
3
/ 33
4
/ 33
Most read
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
Most read
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
Most read
More Related Content
PDF
[DL輪読会]Deep Learning 第6章 深層順伝播型ネットワーク
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第3章 確率と情報理論
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第10章 系列モデリング 回帰結合型ニューラルネットワークと再帰型ネットワーク
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第18章 分配関数との対峙
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第17章 モンテカルロ法
by
Deep Learning JP
PDF
[DL輪読会]Deep Learning 第8章 深層モデルの訓練のための最適化
by
Deep Learning JP
[DL輪読会]Deep Learning 第6章 深層順伝播型ネットワーク
by
Deep Learning JP
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
[DL輪読会]Deep Learning 第3章 確率と情報理論
by
Deep Learning JP
[DL輪読会]Deep Learning 第10章 系列モデリング 回帰結合型ニューラルネットワークと再帰型ネットワーク
by
Deep Learning JP
[DL輪読会]Deep Learning 第18章 分配関数との対峙
by
Deep Learning JP
[DL輪読会]Deep Learning 第17章 モンテカルロ法
by
Deep Learning JP
[DL輪読会]Deep Learning 第8章 深層モデルの訓練のための最適化
by
Deep Learning JP
What's hot
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PPTX
Sliced Wasserstein距離と生成モデル
by
ohken
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
多様な強化学習の概念と課題認識
by
佑 甲野
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
PDF
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
最適輸送の計算アルゴリズムの研究動向
by
ohken
Sliced Wasserstein距離と生成モデル
by
ohken
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
GAN(と強化学習との関係)
by
Masahiro Suzuki
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
Triplet Loss 徹底解説
by
tancoro
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
多様な強化学習の概念と課題認識
by
佑 甲野
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
by
Deep Learning JP
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
Similar to [DL輪読会]Deep Learning 第15章 表現学習
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
PPTX
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
PDF
Contrastive learning 20200607
by
ぱんいち すみもと
PPTX
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
PDF
機械学習 入門
by
Hayato Maki
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
深層学習入門
by
Danushka Bollegala
PPTX
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
PDF
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
PDF
学習係数
by
hoxo_m
PDF
Seeing Unseens with Machine Learning -- 見えていないものを見出す機械学習
by
Tatsuya Shirakawa
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
PDF
Deep learning入門
by
magoroku Yamamoto
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
深層学習の数理
by
Taiji Suzuki
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
論文紹介 Semi-supervised Learning with Deep Generative Models
by
Seiya Tokui
Contrastive learning 20200607
by
ぱんいち すみもと
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
機械学習 入門
by
Hayato Maki
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
機械学習の理論と実践
by
Preferred Networks
深層学習入門
by
Danushka Bollegala
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
学習係数
by
hoxo_m
Seeing Unseens with Machine Learning -- 見えていないものを見出す機械学習
by
Tatsuya Shirakawa
20160329.dnn講演
by
Hayaru SHOUNO
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
Deep learning入門
by
magoroku Yamamoto
More from Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
[DL輪読会]Deep Learning 第15章 表現学習
1.
Deep Learning 輪読会
2017 第15章 表現学習 松尾研究室 リサーチエンジニア 曽根岡 侑也
2.
構成 15章 表現学習 15.1 層ごとの貪欲教師なし事前学習 15.1.1
教師なし事前学習はいつ、なぜうまく働くのか 15.2 転移学習とドメイン適応 15.3 半教師あり学習による原因因子のひもとき 15.4 分散表現 15.5 深さがもたらす指数関数的な増大 15.6 潜在的な原因発見のための手がかり 2
3.
はじめに • 本章の内容:表現を学習するとは何か – 「表現を学習する」とは –
「よい表現」とは – 表現の共有 – マルチドメイン、マルチタスク、マルチモーダルで有用 – 転移学習、ドメイン適応 – 分散表現の優位性 3
4.
表現学習 • 表現次第で情報処理タスクの難易度は変わる - 例1)アラビア数字の計算(「CCX割るVI」
vs 「210 割る 6」 ) - 例2)数値リストのソート(連結リスト vs 木) • 良い表現とは何か - それに続くタスクを簡単にするもの、タスク次第 - (例)NNの分類の場合、Softmaxに渡す表現は線形分離可能であるべき - 入力の情報をできるだけ保存すること vs 好ましい特性の獲得 • 教師なし学習・半教師あり学習に役立つ - ラベルなしデータでよい表現を学習し、教師あり学習で使用 4
5.
15.1 層ごとの貪欲教師なし事前学習 • 層ごとの貪欲教師なし事前学習 -
畳み込みなどの特殊な構造を使わず深層教師あり学習を可能にした 初めての方法で深層学習を再燃させるきっかけ - あるタスク(教師無し)で学習した表現が別タスクで有用と示した実例 - 層ごとに教師なし学習し全部の層の初期化を行ない、その後再学習させる - (例)深層自己符号化器、深層ボルツマンマシン 5
6.
15.1 層ごとの貪欲教師なし事前学習 • 層ごとの貪欲教師なし事前学習のアルゴリズム 6
7.
15.1 層ごとの貪欲教師なし事前学習:事前学習 • 事前学習(Pretraining) -
一度他のタスクで学習し, その後 再学習(fine-tune)すること - 事前学習と再学習の二段階を刺すことが多い • 事前学習の主な使い方 - 特徴抽出器:抽出した表現の上に分類機をつけ、分類機だけを再学習 - パラメータの初期化:モデル全体を再学習させる (参考:ChainThaw:層ごとに再学習) 7
8.
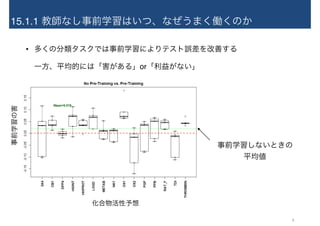
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 多くの分類タスクでは事前学習によりテスト誤差を改善する 一方、平均的には「害がある」or「利益がない」 事前学習しないときの 平均値 事前学習の害 化合物活性予想 8
9.
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 教師なし事前学習を行う動機・アイデア 1.
NNの初期パラメータ選択が正則化の効果があるという仮説 • 事前学習なしでは到達できない領域にモデルを初期化している 2. 入力分布の学習が出力への写像の学習を手助けしうる • 教師なしタスクで有用な特徴量は教師ありでも有用 9
10.
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 表現学習の観点で有効なとき -
自然言語のような初期表現が不十分なものに有効 - 画像のような既にリッチなベクトル空間ではそこまで有用ではない • 正則化の観点で有効なとき - ラベルなしデータは大量にあるが、ラベルありデータが少ないとき • その他の有効なとき - 学習される関数が極めて複雑な場合 • 通常の正則化が単純な関数を学習させようとしているのに対して、 学習タスクに有用な特徴量を発見させる方向に働いている 10
11.
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 教師なし事前学習は正則化だけでなく訓練誤差も改良する •
到達不可能な領域に事前学習が導いていることを示す実験 [Erhan, (2010)] - 事前学習をすると一貫した特定の関数へ収束する - 事前学習により、推定過程の分散を低下 + 過適合のリスクを低下 11
12.
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 事前学習が最もよく働くのはいつか
[Erhan 2010] - より深いネットワークではテスト誤差の平均と分散を低下させた ※ この実験は、ReLU・ドロップアウト・バッチ正規化以前の話 • 教師なし事前学習がどのように正規化として機能するのか - 観測データを生成する潜在因子に関する特徴量の発見の手助けをしている 12
13.
15.1.1 教師なし事前学習はいつ、なぜうまく働くのか • 教師なし事前学習のデメリット -
正則化の強度を調整するわかりやすい方法がない - 事前学習時のハイパーパラメータ調整が難しい • 2段階でのステップをふむため、事前学習のハイパーパラメータを 再学習時の結果をみて変更する必要がある • 現在のユースケース - 自然言語処理の単語埋め込み以外ほとんど使わない (one-hot, 大量のラベルなしデータがあるという理由) - 教師あり事前学習はよく使われており主流のものは公開されている 13
14.
15.2 転移学習とドメイン適応 • ある設定(分布P1)で学んだことを別の設定(分布P2)の汎化能力の向上を 試みるアイデアがある -
同一の表現が双方の問題設定で有用というアイデア • 転移学習 - 異なる2つ以上のタスクで学習 - P1とP2の変化を説明する因子が近いという仮定 - あるタスクで学習したあとに近いタスクで再学習する - 例1)犬猫分類 → アリハチ分類(エッジなどの下位概念を共有) - 例2)音声認識(人毎に変更、上位層の言語モデルを共有) 14
15.
15.2 転移学習とドメイン適応 • ドメイン適応 -
タスクは同じであるが、入力分布が異なる問題で学習 - 例)音楽レビューの感情分析 → 家電レビューの感情分析 (語彙や文体が違うため、再学習が必要) • コンセプトドリフト - 時間経過でデータ分布が変化することを考慮した転移学習 15
16.
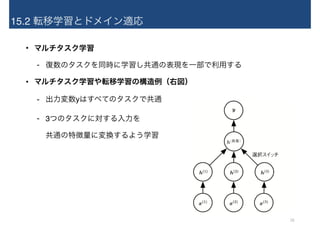
15.2 転移学習とドメイン適応 • マルチタスク学習 -
復数のタスクを同時に学習し共通の表現を一部で利用する • マルチタスク学習や転移学習の構造例(右図) - 出力変数yはすべてのタスクで共通 - 3つのタスクに対する入力を 共通の特徴量に変換するよう学習 16
17.
15.2 転移学習とドメイン適応 • ゼロショット学習:ラベルあり事例はなし -
入力x, 出力y, タスクを記述する確率変数Tでモデル化 - 例)大量のテキストで学習し、物体認識する 猫の特徴のテキストから画像に猫がいるかを判定 - 例2) 機械翻訳 単一言語コーパスからそれぞれの言語の分散表現を学習し結びつける • ワンショット学習:ラベルありが1つだけ与えられる - ラベル無しで潜在的なクラスを分けるような表現を学習 - 1つのラベルありデータがあれば特徴空間上で周りにあるデータの ラベルを推論できる 17
18.
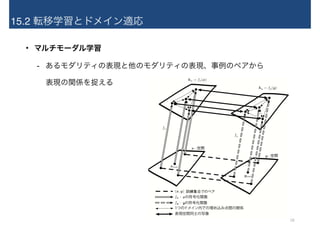
15.2 転移学習とドメイン適応 • マルチモーダル学習 -
あるモダリティの表現と他のモダリティの表現、事例のペアから 表現の関係を捉える 18
19.
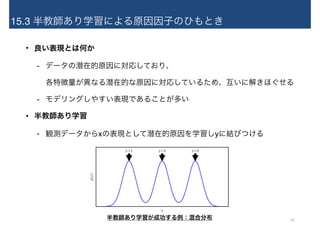
15.3 半教師あり学習による原因因子のひもとき • 良い表現とは何か -
データの潜在的原因に対応しており、 各特徴量が異なる潜在的な原因に対応しているため、互いに解きほぐせる - モデリングしやすい表現であることが多い • 半教師あり学習 - 観測データからxの表現として潜在的原因を学習しyに結びつける x p(x) y=1 y=2 y=3 半教師あり学習が成功する例:混合分布 19
20.
15.3 半教師あり学習による原因因子のひもとき • 観測xの原因となる潜在因子hを見つけることができ、 ラベルyがその潜在因子と結びつきであれば、半教師あり学習が有効 -
p(y | x)は周辺分布p(x)と密接に結びついているため、 p(x)の知識は手助けになるはずである 20
21.
• 課題: - 観測結果の大半が多くの潜在的原因によって生成されている -
全ての潜在的原因を捉えて、紐解くことはほぼ不可能 • 重要な研究テーマ - 「それぞれの状況で何を符号化するべきか」を決定すること 1. 最も適切な変化の要因群を捉えるように教師あり + 教師なしを利用 2. 教師なしのみであれば大きな表現を使う 21
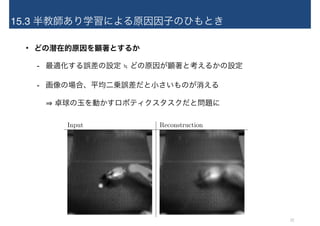
22.
15.3 半教師あり学習による原因因子のひもとき • どの潜在的原因を顕著とするか -
最適化する誤差の設定 ≒ どの原因が顕著と考えるかの設定 - 画像の場合、平均二乗誤差だと小さいものが消える ⇒ 卓球の玉を動かすロボティクスタスクだと問題に Input Reconstruction 22
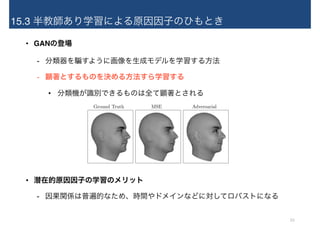
23.
15.3 半教師あり学習による原因因子のひもとき • GANの登場 -
分類器を騙すように画像を生成モデルを学習する方法 - 顕著とするものを決める方法すら学習する • 分類機が識別できるものは全て顕著とされる • 潜在的原因因子の学習のメリット - 因果関係は普遍的なため、時間やドメインなどに対してロバストになる Ground Truth MSE Adversarial 23
24.
15.4 分散表現 • 分散表現:互いに分離可能な要素により構成された表現 -
k個の値を持つn個の特徴量を利用することで の概念を表現できる - データを説明する潜在因子を隠れ層が学習できるという仮説に基づく 24
25.
15.4 分散表現 • 分散表現:n次元のバイナリ素性ベクトル(左) -
の状態を取ることができる、一般的に を表すことができる • シンボリック表現(onehot表現):各要素が各シンボルを表す(右) - n個の異なる状態のみが起こる相互排他的な表現 h1 h2 h3 h = [1, 1, 1]> h = [0, 1, 1]> h = [1, 0, 1]> h = [1, 1, 0]> h = [0, 1, 0]> h = [0, 0, 1]> h = [1, 0, 0]> 25
26.
15.4 分散表現 • 非分散表現に基づく学習アルゴリズム例 -
k平均法を含むクラスタリング手法:1つのクラスタに割り当てられる - k近傍法アルゴリズム: 少数のテンプレートやプロトタイプ事例が関連付けられる - 決定木:1つの葉ノードのみが活性化する - 混合ガウスや混合エキスパート: - ガウシアンカーネルを用いたカーネルマシン: 復数の値により表現されるが独立に制御するのは容易ではない - n-gramによる言語/翻訳モデル: 文脈(シンボルの連なり)の集合は接尾辞の木構造に応じて仕切られる 26
27.
15.4 分散表現 • 分散表現によるメリット -
異なる概念感で共通の属性による汎化(ex:猫と犬) - 類似度の測定が可能 - 複雑な構造が少数のパラメータによって表現できる時が有効 • 統計的な観点による比較:’ の領域を分解する際 - 非分散学習:識別可能な領域数と同じ事例が最低でも必要 - 分散表現: のパラメータ数で分割可能 ⇒ 少ないパラメータのモデルで良いため汎化に必要なデータは少ない 27
28.
15.4 分散表現 • GANを使った分散表現 -
性別やサングラスなどの表現を分離して獲得できている - + = 28
29.
15.5 深さがもたらす指数関数的な増大 • 原因因子はかなり高次なため、深層分散表現が必要 •
莫大なユニット数があれば隠れ層を持つネットワークは万能近似器 - 多種類の関数を近似 - 不十分な深さの場合、ユニット数は入力規模に対して指数関数的になる - 基本的に十分な深さがあると指数関数的なメリットがある • 例)積和ネットワーク(SPN) - 確率変数の集合に対する確率分布を計算する ために多項式回路を利用 - 有限の深さで確率分布を表せるが、表現力が制限される可能性がある - 深くなるほど、指数関数的な表現力を持つ 29
30.
15.6 潜在的な原因発見のための手がかり • まとめ -
よい表現は、原因因子をひもとく表現である - 教師あり学習は、直接的に変動の因子を少なくとも1つ紐解いている - 表現学習は特設的ではない手がかりを利用している • よりよい表現を獲得するために正則化戦略が必要 - 人間が解けるタスクに類似した様々なAIタスクに適用可能な 一般的な正則化戦略を見つけるのが深層学習の目的の1つ 30
31.
15.6 潜在的な原因発見のための手がかり • 滑らかさ:僅かな変動εに対して が成立するという仮定. これにより、入力の近傍店を汎化できる •
線形性:幾つかの変数の間の関係が線形であるという仮定. • 復数の説明因子:データが複数の潜在的な説明因子により生成されており, 因子の各状態がわかれば大半のタスクは解けるという仮定. • 原因因子:モデルは変動因子hを観測データ x の原因として扱うように構築し その逆は成り立たない • 深さあるいは説明因子の階層性 : 上位の抽象的な概念は階層構造をなす単純な概念により定義できるという仮定 31
32.
15.6 潜在的な原因発見のための手がかり • タスク間の共有因子: タスク間で共有の原因を持ちそうな時、因子hを共通に使える部分がある •
多様体:確率の大部分は集中しており、集中領域は局所的につながっている • 自然なクラスタリング:入力空間において結合された多様体は それぞれ 1 つのクラスに割り当てられると仮定. • 時間的・空間的なコヒーレンス: 1. 最も重要な説明因子は時間をかけてゆっくり変化 2. 真の潜在的な説明因子を予測する方が生の観測値を予測するよりも簡単であることを仮定 • スパース性:大半の特徴量は,大半の入力を説明するのに関連していない • 因子の依存関係の簡潔さ: よい高次の表現では因子は互いに単純な依存関係で結び付いている 32
33.
参考文献 • Deep Learning –
Ian Goodfellow, Yoshua Bengio, Aaron Courville – 日本語版 – https://www.amazon.co.jp/%E6%B7%B1%E5%B1%A4%E5%AD%A6%E7%BF%92- Ian-Goodfellow/dp/4048930621 33
Download









![15.1.1 教師なし事前学習はいつ、なぜうまく働くのか
• 教師なし事前学習は正則化だけでなく訓練誤差も改良する
• 到達不可能な領域に事前学習が導いていることを示す実験 [Erhan, (2010)]
- 事前学習をすると一貫した特定の関数へ収束する
- 事前学習により、推定過程の分散を低下 + 過適合のリスクを低下
11](https://image.slidesharecdn.com/deeplearning15-180601023904/85/DL-Deep-Learning-15-11-320.jpg)
![15.1.1 教師なし事前学習はいつ、なぜうまく働くのか
• 事前学習が最もよく働くのはいつか [Erhan 2010]
- より深いネットワークではテスト誤差の平均と分散を低下させた
※ この実験は、ReLU・ドロップアウト・バッチ正規化以前の話
• 教師なし事前学習がどのように正規化として機能するのか
- 観測データを生成する潜在因子に関する特徴量の発見の手助けをしている
12](https://image.slidesharecdn.com/deeplearning15-180601023904/85/DL-Deep-Learning-15-12-320.jpg)







![15.4 分散表現
• 分散表現:n次元のバイナリ素性ベクトル(左)
- の状態を取ることができる、一般的に を表すことができる
• シンボリック表現(onehot表現):各要素が各シンボルを表す(右)
- n個の異なる状態のみが起こる相互排他的な表現
h1
h2 h3
h = [1, 1, 1]>
h = [0, 1, 1]>
h = [1, 0, 1]>
h = [1, 1, 0]>
h = [0, 1, 0]>
h = [0, 0, 1]>
h = [1, 0, 0]>
25](https://image.slidesharecdn.com/deeplearning15-180601023904/85/DL-Deep-Learning-15-25-320.jpg)








![[DL輪読会]Deep Learning 第6章 深層順伝播型ネットワーク](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning6-180601022208-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第3章 確率と情報理論](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning3-180601014703-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第10章 系列モデリング 回帰結合型ニューラルネットワークと再帰型ネットワーク](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning10-180601023046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第18章 分配関数との対峙](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning18-180601024904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第17章 モンテカルロ法](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning17-180601024803-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第8章 深層モデルの訓練のための最適化](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning8-180601022707-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Causality Inspired Representation Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20220422lin-220422031920-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

























