Download as PDF, PPTX





![【おさらい】MDPとは
• マルコフ決定過程 (Markov Decision Process; MDP) とは現在の
⾏動と状態を必ず知ることができる状態遷移が確率的に起こ
る動的なモデルである。
• グラフィカルモデルで表現すると下の通り
[1]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-5-320.jpg)
![POMDPとは
• 部分観測マルコフ決定過程 (Partially Observable Markov
Decision Process; POMDP) は、⼀部しか観測できない状況であ
るモデルである。状態は直接わからない(潜在変数)。
MDPを⼀般化したモデルにあたる
• グラフィカルモデルで表現すると下の通り
[1]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-6-320.jpg)


![各種モデルの関係性
• 他のグラフィカルモデルとの位置づけを整理するとスッキリ
⾏動なし ⾏動あり
状態観測が完全 マルコフ連鎖 (MC) MDP
状態観測が⼀部 隠れマルコフモデル (HMM) POMDP
決定論 確率論
状態観測が完全 有限オートマトン マルコフ連鎖 (MC)
[15]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-9-320.jpg)

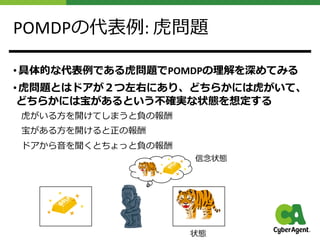

![⻁問題を状態遷移図にすると
• 各変数から状態遷移図を作ると以下の通り
• また観測確率関数は表の通り
[1]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-13-320.jpg)
![⻁問題における信念状態と履歴
• ここではひたすらlistenすることを考える。その時の観測か
ら信念状態𝑏$ 𝑠 は再帰的に更新されていく
[1]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-14-320.jpg)
![環境が既知である場合の解き⽅
• 実問題を解く上では環境は未知であることが多いので、
この場合は本発表では概要だけ説明する
• 環境が既知である場合、MDPと同様にプランニングにより解
くことができる。
• POMDPの厳密な解き⽅として、モナハンの価値反復法があ
る。しかし、組合せ爆発を起こす⼿法なので、実⽤的には使
われない。このため、点近似の価値反復法 (PBVI) がある。
モナハンの価値反復法を⼀回だけ反復した時の価値関数。
縦が信念状態に対する価値、
横が⻁が左にいるという信念状態
線の⾊が価値を最⼤にする⽅策
([1]より引⽤)](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-15-320.jpg)
![環境が未知である場合の解き⽅
• モデルベースの場合とモデルフリーの場合の2つのパターン
に分かれる
さらにモデルベースではデータからプランニングするものと
シミュレータからプランニングするものに分かれる
モデルベースでの強化学習
([1]より引⽤)
モデルフリーでの強化学習
([1]より引⽤)](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-16-320.jpg)


![POMDPの応⽤
• POMDPは実世界の様々な問題を表現することに適している
⼀⼈称シューティングゲーム
⾃動⾞の⾃動運転
対話システムの制御
その他は参考⽂献[3]を参照のこと
• ここではいくつかの具体例をあげて説明する](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-19-320.jpg)
![ゲームの例
• 例えば、⼀⼈称シューティングゲーム(FPS)の場合、環境
はゲーム空間になるが、プレイヤーは⾃分から⾒える範囲し
か観測できないことを前提としている
最たる例がViZDoom
ViZDoomの画⾯とメタデータ([4]より引⽤)](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-20-320.jpg)
![ViZDoomの定式化例
• ViZDoom P = 𝒮, 𝒜, 𝑠!!
, 𝑝", 𝑟, 𝒪, 𝑝# を定式化した結果はたくさ
んあるし、シナリオによるが、たとえば以下の通りとなる。
𝒮: 位置、健康状態、弾数
𝒜: {左に動く, 右に動く, 撃つ}
𝑠!!
: 中央に固定
𝑝": (未知)
𝑟: 敵を倒した、時間切れ
𝒪: マップ内で⾒れる⼀⼈称の画像すべて
𝑝#:(未知) [5]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-21-320.jpg)
![ViZDoomのベースライン解法
• MDPとして考えて、関数近似で解く[5]
畳み込みニューラルネットワークを使って、⽅策をDQNで解く
状態は全く記憶できていない
[5]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-22-320.jpg)
![ViZDoomの改善された解法
• LSTMによるメモリありのアプローチを採⽤する[6]
[6]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-23-320.jpg)
![ロボットの例
• ロボットではナビゲーションなどの問題がPOMDPとなる。
• 例えば、市街地における⾃動⾞の⾃動運転の場合、環境は実
世界の市街地を対象とするが、実世界そのものを完全に把握
することはできない。そこで、センサからの情報などしか観
測できないことを前提としている
[7]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-24-320.jpg)

![⾃動運転へのアプローチ
• アプローチはいくつか提案されている[7]
⼈が運転した結果を模倣
シミュレータで獲得した⽅策を実世界に転移
• また、制御の抽象度によっても分類されている[8]
センサの値から⾏動する
センサの値と経路のプランニング結果から⾏動する
などなど
• ただし、POMDPで定式化して実世界に適⽤した例は
とても少ない](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-26-320.jpg)
![• 実世界で⼈間が運転した結果を元にニューラルネットワーク
を⾏動を模倣させ、実世界にも試してみた[9]
POMDPであることはあまり気にしていない気がする
⾃動運転の解き⽅の代表例
[9]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-27-320.jpg)
![⾃動運転の解き⽅の例
• 駐⾞場で移動するタスクにおいて、シミュレータ環境で深層
学習させた結果を実世界に適⽤した[10]
というMDPとはいうけど、
POMDPに近い気がする
[10]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-28-320.jpg)
![まとめ
• 部分観測マルコフ決定過程 (Partially Observable Markov
Decision Process; POMDP) は、⼀部しか観測できない状況であ
るモデルである。状態は直接わからない。
環境が既知であるとき、モナハンの価値反復法で解ける
環境が未知であるとき、部分観測モンテカルロプランニングなどで解く
近年では深層強化学習を使って近似的に解くことが多い
• POMDPの解法を本発表よりも詳しく学びたい⼈は参考⽂献
[1,2,13,14]を読んでください
• また、POMDPの問題を実際に解いてみたいという⼈は参考
⽂献[14]にソルバーがあるので使ってみてください](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-29-320.jpg)
![おまけ1︓LSTMの有効性
• MDPなゲームをたまに画⾯を隠すことでPOMDPにした場合、
DQNにLSTMをいれるとスコアが改善した[11]
[11]より引⽤](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-30-320.jpg)
![参考⽂献
[1] 森村哲郎, “強化学習 (機械学習プロフェッショナルシリーズ),” 2019
[2] セバスチャン・スランら, “確率ロボティクス”, 2007
[3] Cassandra et al., “A Survey of POMDP Applications,”
[4] Wydmuch et al., “ViZDoom Competitions: Playing Doom from Pixels,” 2018,
https://github.com/mwydmuch/ViZDoom
[5] Kempka, et al., “ViZDoom: A Doom-based AI Research Platform for Visual
Reinforcement Learning,” 2016
[6] Lample et al., “Playing FPS Games with Deep Reinforcement Learning”, 2016](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-31-320.jpg)
![参考⽂献
[7] Kiran et al., “Deep Reinforcement Learning for Autonomous Driving: A Survey” 2020
[8] Zhu., “A Survey of Deep RL and IL for Autonomous Driving Policy Learning,” 2021
[9] Bojarski et al., “End to End Learning for Self-Driving Cars,” 2016
[10] Folkers et al., “Controlling an Autonomous Vehicle with Deep Reinforcement
Learning,” 2019
[11] Hausknecht et al., “Deep Recurrent Q-Learning for Partially Observable MDPs” 2015
[12] “POMDPs for Dummies”,
https://cs.brown.edu/research/ai/pomdp/tutorial/index.html
[13] 牧野ら, “これからの強化学習”, 2016
[14] Anthony R. Cassandra, “The POMDP Page”, https://www.pomdp.org/
[15] 渡辺有祐、”グラフィカルモデル” 2016](https://image.slidesharecdn.com/pomdp-210517094400/85/POMDP-32-320.jpg)

This document provides an overview of POMDP (Partially Observable Markov Decision Process) and its applications. It first defines the key concepts of POMDP such as states, actions, observations, and belief states. It then uses the classic Tiger problem as an example to illustrate these concepts. The document discusses different approaches to solve POMDP problems, including model-based methods that learn the environment model from data and model-free reinforcement learning methods. Finally, it provides examples of applying POMDP to games like ViZDoom and robot navigation problems.
![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





































