This document discusses the implementation of the word2vec model for word embeddings, focusing on its application in the Italian language. It details the corpus creation, preprocessing steps, network architecture, and training processes using two models: continuous bag of words (CBOW) and skip-gram. The document also presents experimental results, including analogies tests for evaluating the model's performance in comparison to English.
![Sapienza University of Rome • 12 April 2016 • Course: Neural Networks
Word2Vec on Italian language
Cucari Francesco
De Cillis Daniele
Molinari Dario
I. Introduction
Research on word representation models, word embeddings, has gained a lot of attention in the
recent years[1]. This happened also thanks to a renewed boost in neural network technologies,
such as deep learning. With these progresses it has become possible to train more complex models
on much larger data sets. Probably, one of the most popular of this series of work is without
doubt Mikolow’s word2vec [2][3], that introduces the concept of using distributed representations
of words.
Distributed word representations, also known as word embeddings, represent a word as a vec-
tor in n. The more the vectors are closer the more the two corresponding words are deemed to
share some degree of syntactical or semantical similarity[4]. For example, the result of a vector
calculation vec(‘Paris‘) - vec(‘France‘) + vec(‘Italy‘) is closer to vec(‘Rome‘) than to any other word
vector.1
The main purpose of this work is to validate previously proposed experiments for the English
language and then trying to figure out if it is possibile to reproduce the same accuracy and
performance with the Italian language, using our implementation of word2vec.
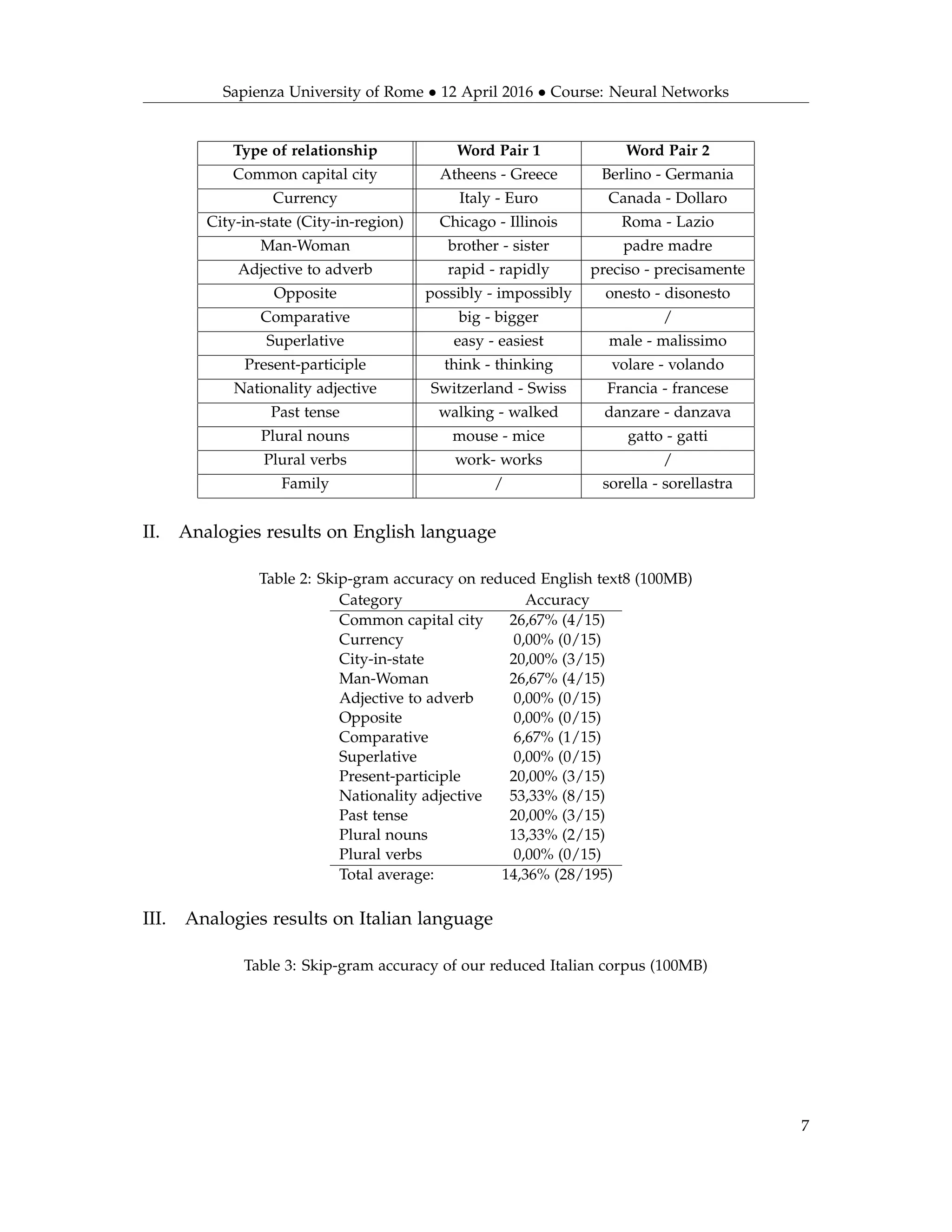
II. Corpus
A corpus is a collection of texts composed by many sentences of various topics, in such a way that
the neural network can learn the meaning of each word it finds thanks to the context.
Some of the most famous Italian corpus are Paisà2 and ItWac3. Both include texts from the
web, such as chat conversations, books extracts and articles. However, both are not formatted prop-
erly for our purpose. So, we preferred to manually create a corpus. Our corpus has two datasets
in the Italian language: half of the dump of the Italian Wikipedia4 (dated 06/03/2016) and a
collection of about 120.000 Italian articles written in 2010 taken from the archive of “La Repubblica”.
We trained the network with corpus of different sizes. Initially, we train the model with an
English corpus, called text85, that had a dimension of 100 MB, corresponding to about 17 millions
of words. Finally, we train the model with our Italian corpus that has a dimension of 920 MB,
1https://code.google.com/archive/p/word2vec/ Google Code archive: word2vec - Tool for computing continuous
distributed representations of words.
2http://www.corpusitaliano.it/
3http://wacky.sslmit.unibo.it/doku.php?id=corpora
4http://dumps.wikimedia.org/itwiki/latest/
5http://mattmahoney.net/dc/textdata
1](https://image.slidesharecdn.com/word2vec-report-160412171355/75/Word2Vec-on-Italian-language-1-2048.jpg)





![Sapienza University of Rome • 12 April 2016 • Course: Neural Networks
padre
Nearest to Cosine distance
nonno 0.354935
figlio 0.381211
quando 0.687557
mentre 0.834535
paraurti
Nearest to Cosine distance
calandra 0.367163
cofano 0.475904
abitacolo 0.495059
carrozzeria 0.496319
V. ”Doesn’t match” test
The test consists of some questions, each is composed by 4 words. The goal of the test is to find
the word that doesn’t match with others. We compute the cosine distance of each word with the
others. Then, we compute the mean of these distances and finally the word with the highest mean
is the intrusive word.
Table 6: Some outputs of the test
Word 1 Word 2 Word 3 Word 4 Predicted intrusive word
uomo donna cucina bambino cucina
uomo mamma bambino ragazzo mamma
roma lombardia milano napoli lombardia
argentina francia spagna berlino berlino
sono ero essendo avere avere
trovai trovato trovare essere trovai
essendo avendo amando leggere amando
giallo uomo rosso arancione uomo
giallo bianco rosso arancione arancione
As a result, generally the trained model is able to identify similar words in clusters and it
deletes the word farthest from the others.
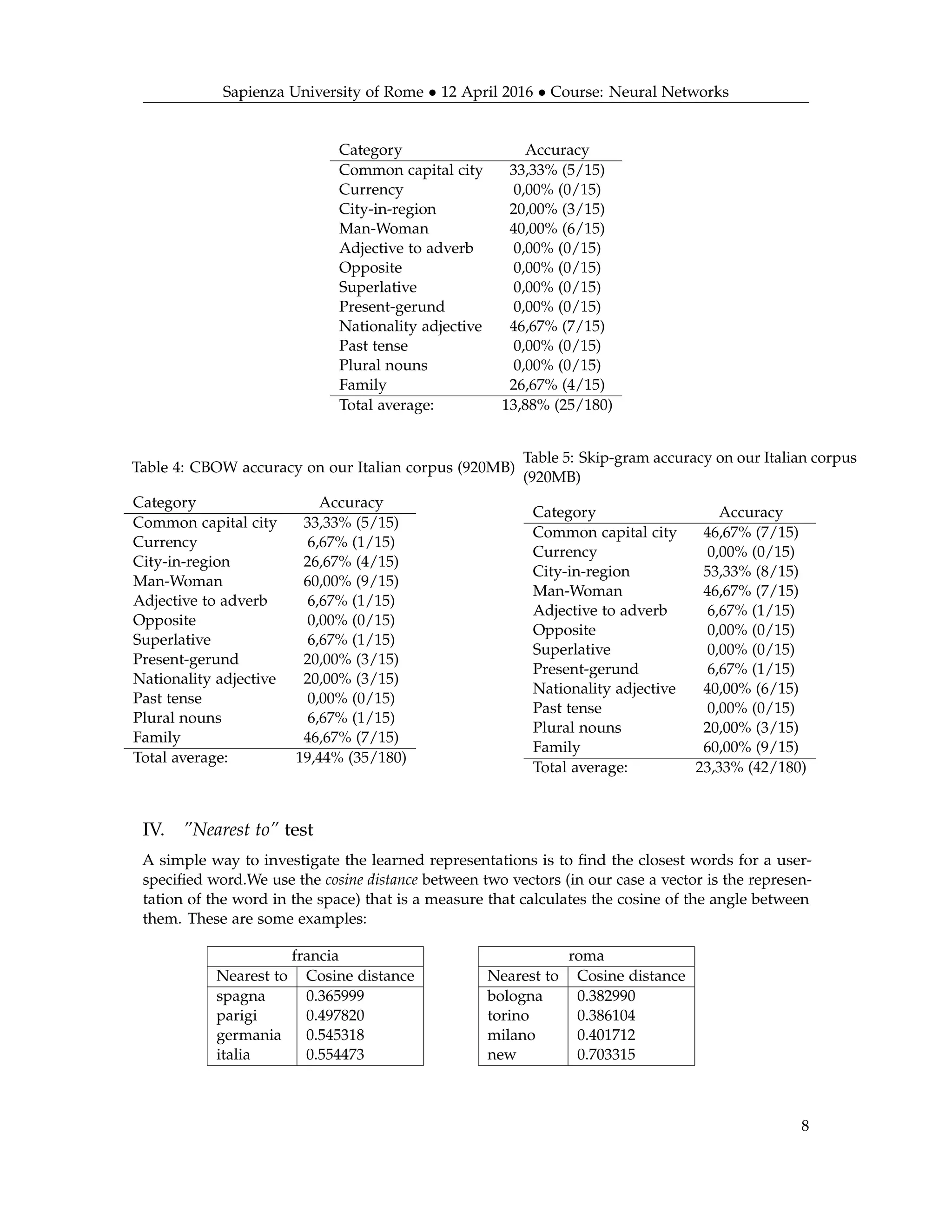
VI. Visualization of learned embeddings
After the training has finished we can visualize the learned embeddings using t-SNE (t-distributed
Stochastic Neighbor Embedding).
t-SNE[6] is a tool to visualize high-dimensional data. It converts similarities between data
points to joint probabilities and tries to minimize the Kullback-Leibler divergence between the
joint probabilities of the low-dimensional embedding and the high-dimensional data. t-SNE has a
cost function that is not convex, i.e. with different initializations we can get different results.
The static image of the plot looks very confusing, since it contains 150000 words. If you can
dynamically navigate through the Python tools, then you can notice that words with a similar
semantic meaning are grouped nearby, as you can see in the Fig. 3 and Fig.4.
9](https://image.slidesharecdn.com/word2vec-report-160412171355/75/Word2Vec-on-Italian-language-9-2048.jpg)

![Sapienza University of Rome • 12 April 2016 • Course: Neural Networks
(skip-window) to avoid considering different contexts’ sentences.
We adopted a simple word analogies test to evaluate the generated word embeddings. We
provided a literal translation, and probably rough, of the analogies file used for testing. To
improve the performance it would be necessary to implement a test file with more accurate
translations and with a greater number of elements. Furthemore, to train efficiently the neural
network, it would be necessary to insert in the corpus a greater number of words from different
sources, such as books, conversations and articles of various newspapers, in order to learn more
information from multiple contexts.
In conclusion, the test was conducted on corpora of various sizes in order to demonstrate
that increasing the size of the corpus and the number of words in the vocabulary, the neural
network provides better results.
References
[1] "Natural language processing (almost) from scratch." - Collobert, Ronan, et al. 2011
[2] “Distributed representations of words and phrases and their compositionality” - Mikolov,
Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg S and Dean, Jeff 2013
[3] “Efficient estimation of word representations in vector space.” - Mikolov, Tomas, et al. 2013.
[4] “Word Embeddings Go to Italy: a Comparison of Models and Training Datasets” - Berardi,
Giacomo and Esuli, Andrea and Marcheggiani, Diego 2015
[5] “A closer look at skip-gram modelling.” - Guthrie, David, et al. 2006.
[6] "Visualizing data using t-SNE." - Van der Maaten, Laurens, and Geoffrey Hinton 2008
11](https://image.slidesharecdn.com/word2vec-report-160412171355/75/Word2Vec-on-Italian-language-11-2048.jpg)











































































