Download as PDF, PPTX












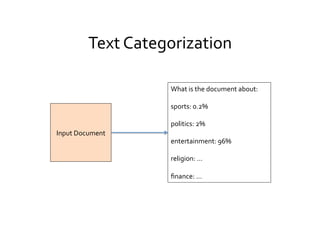


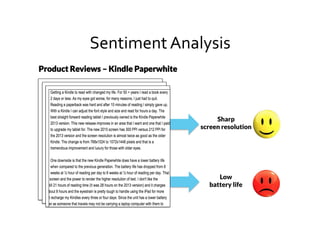




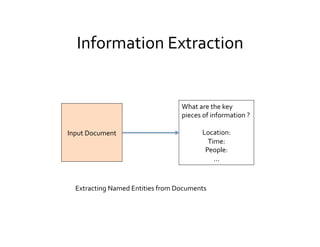
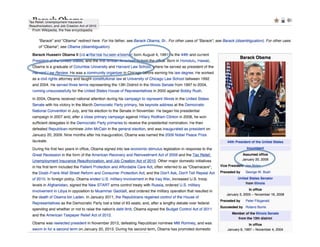






























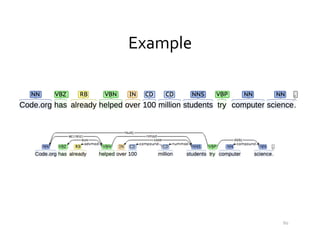









This document provides an introduction to natural language processing (NLP) through a presentation given by Rutu Mulkar-Mehta. The presentation covers understanding natural language, common NLP tasks like text categorization and sentiment analysis, and challenges like ambiguity. It also discusses part-of-speech tagging and linguistic resources. The overall goal is to introduce attendees to the field of NLP and some of its applications.























































































