Downloaded 681 times



















The document provides insights on winning data science competitions, emphasizing the importance of effective model building and the pitfalls of overfitting. Technical strategies include using gradient boosting machines, stacking models, and careful feature engineering. Key competitions, such as those hosted by Amazon and Allstate, illustrate practical applications of these concepts.
Overview of data science competitions, presentation objectives, and speaker background.
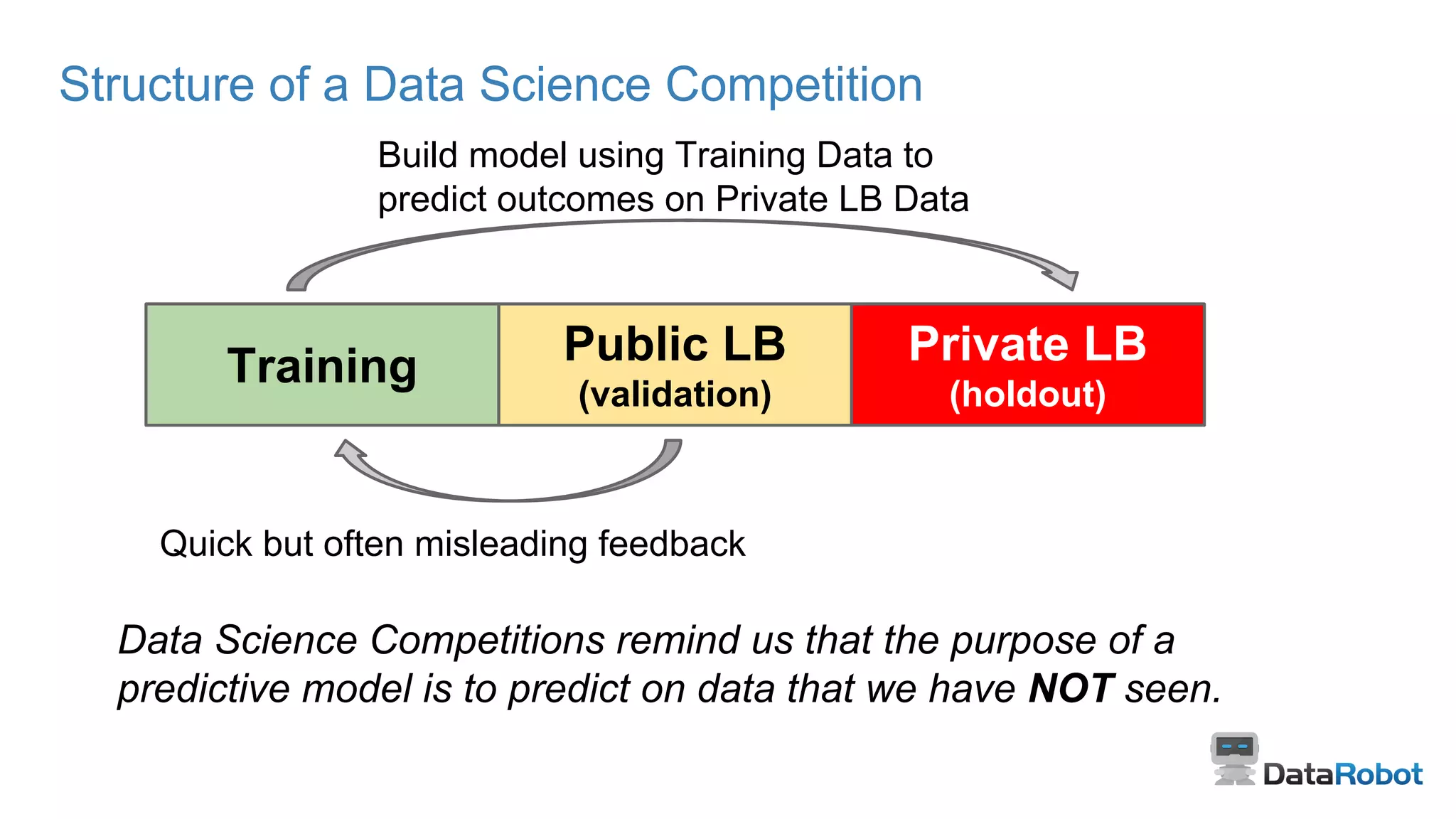
Focus on predicting unseen data, the pitfalls of overfitting, and validation strategies.
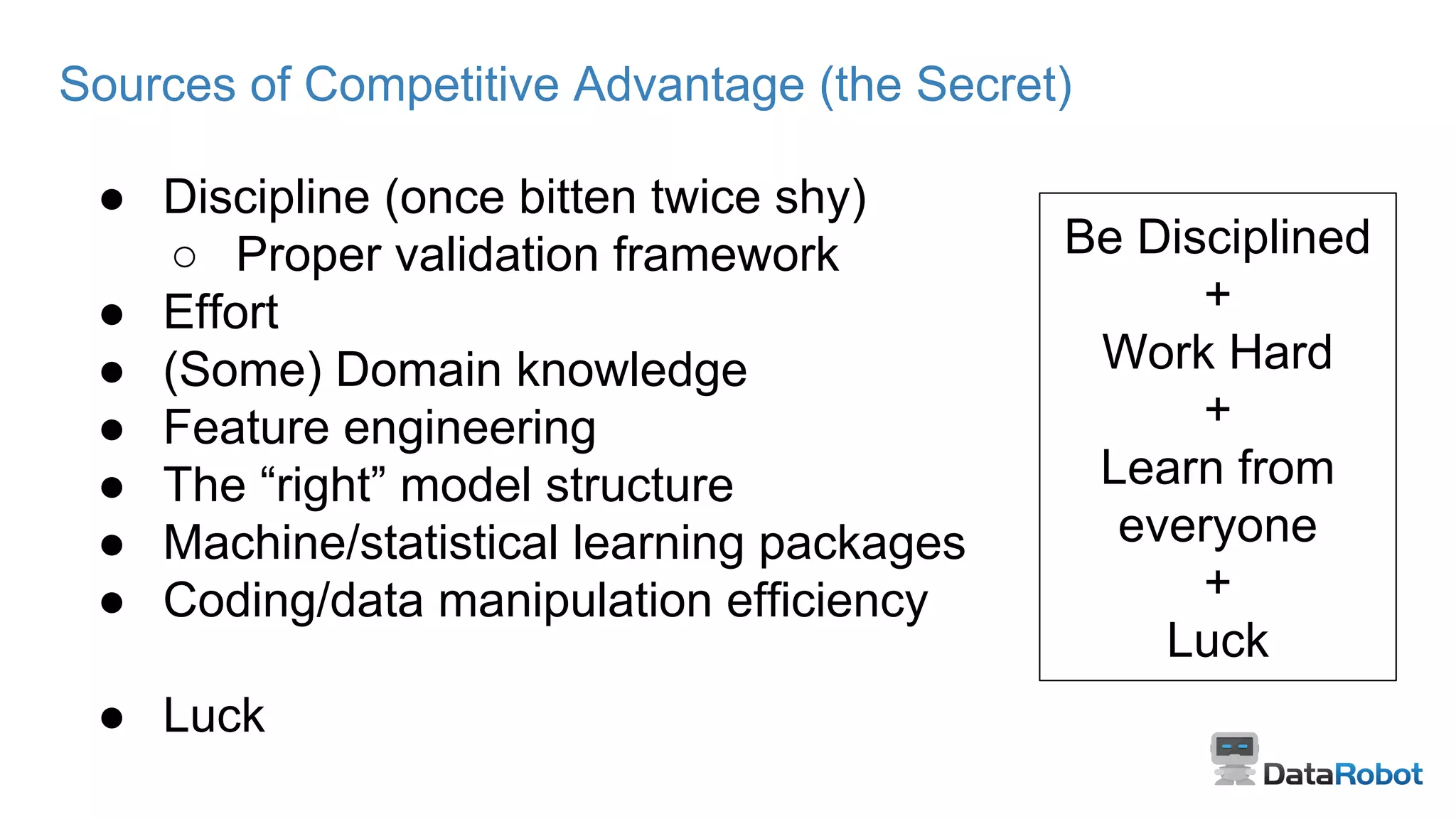
Key factors for success include discipline, effort, domain knowledge, feature engineering, and luck.
In-depth tips on using GBM effectively, including tuning parameters and handling high cardinality features.
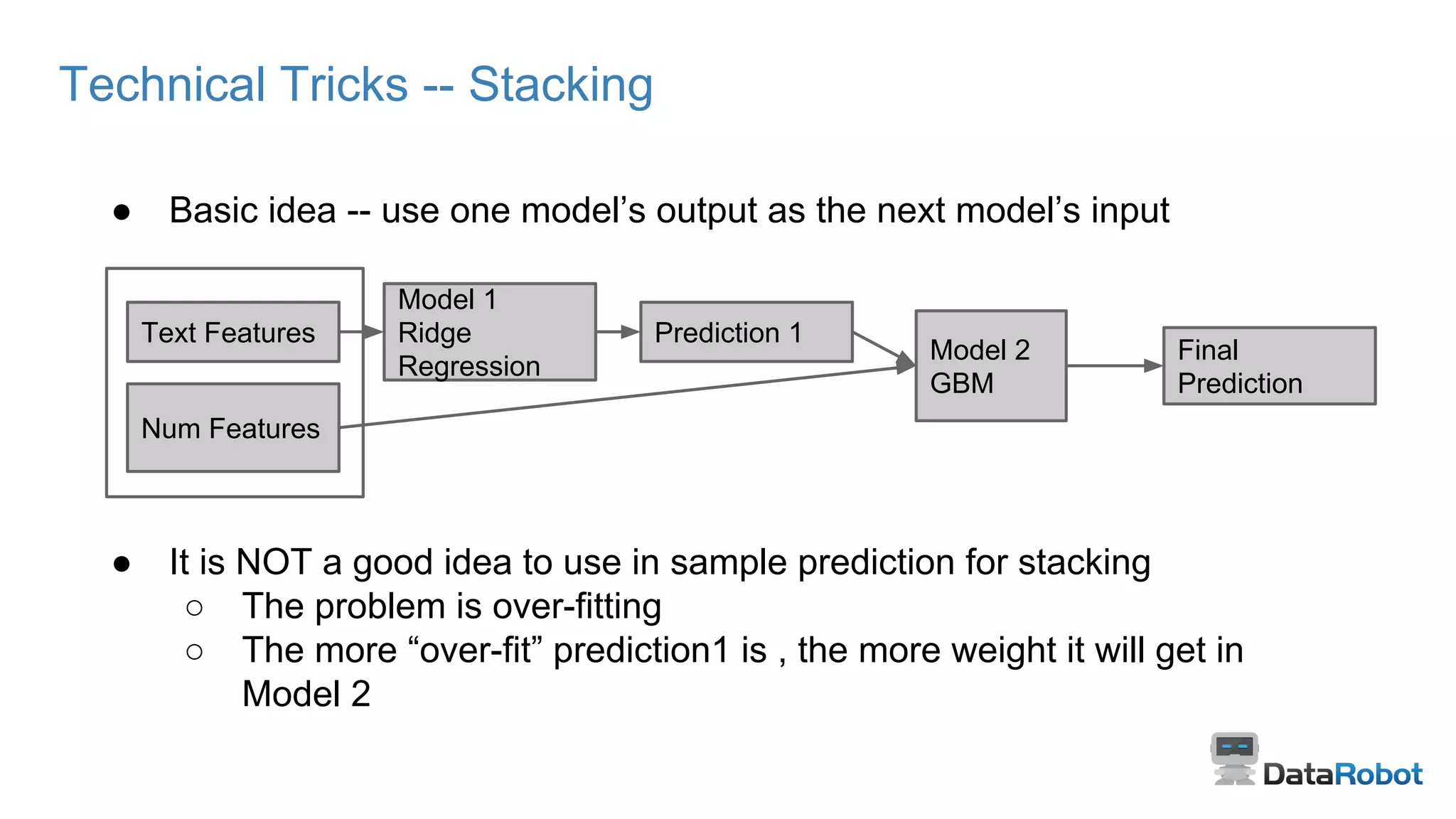
Utilizing output from one model as input for another to improve predictions with best practices in CV.
Importance of explicitly defining strong interactions and complex features for better model performance.
Contrasting GBM with Glmnet for linear relationships and applying text mining methods.
Using diverse models and careful blending to enhance predictive accuracy while avoiding overfitting.
Insights gained from competitions can inform problem structuring, data selection, and model application.
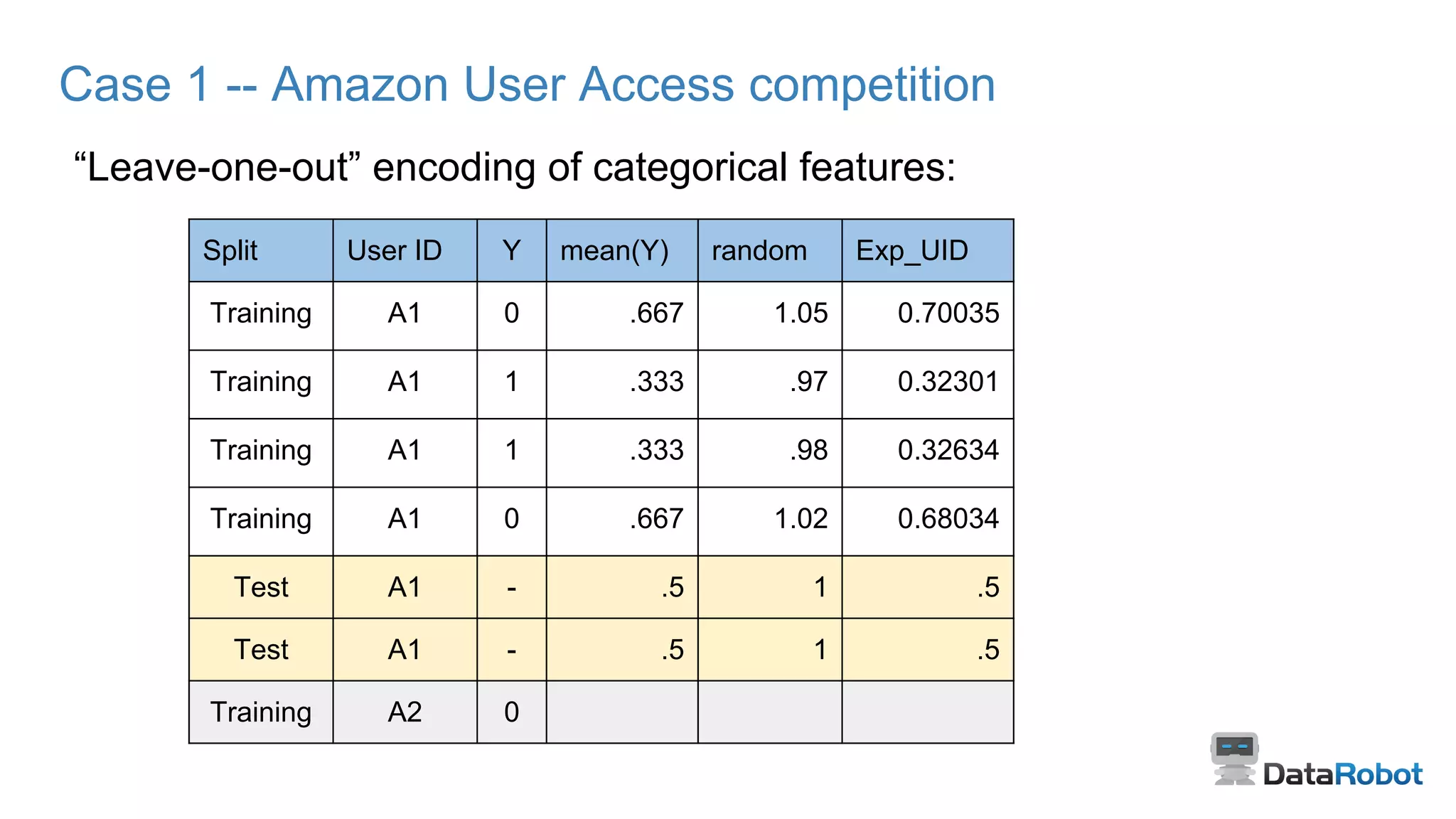
Analysis of approach and techniques used in the popular Amazon competition focusing on feature encoding.
Challenges and strategies for predicting multiple correlated product options in a competitive environment.
Useful links to competitions, forums, and learning resources for data science practitioners.

































































































