XGBoost is a decision-tree-based ensemble machine learning algorithm known for its speed and performance, particularly on large datasets. It utilizes boosting, which combines several weak learners to enhance prediction accuracy, and features a wide variety of tuning parameters. Common applications include projects in gold glove prediction, housing price estimation, and malware prediction.
Context
● What’s XGBoost
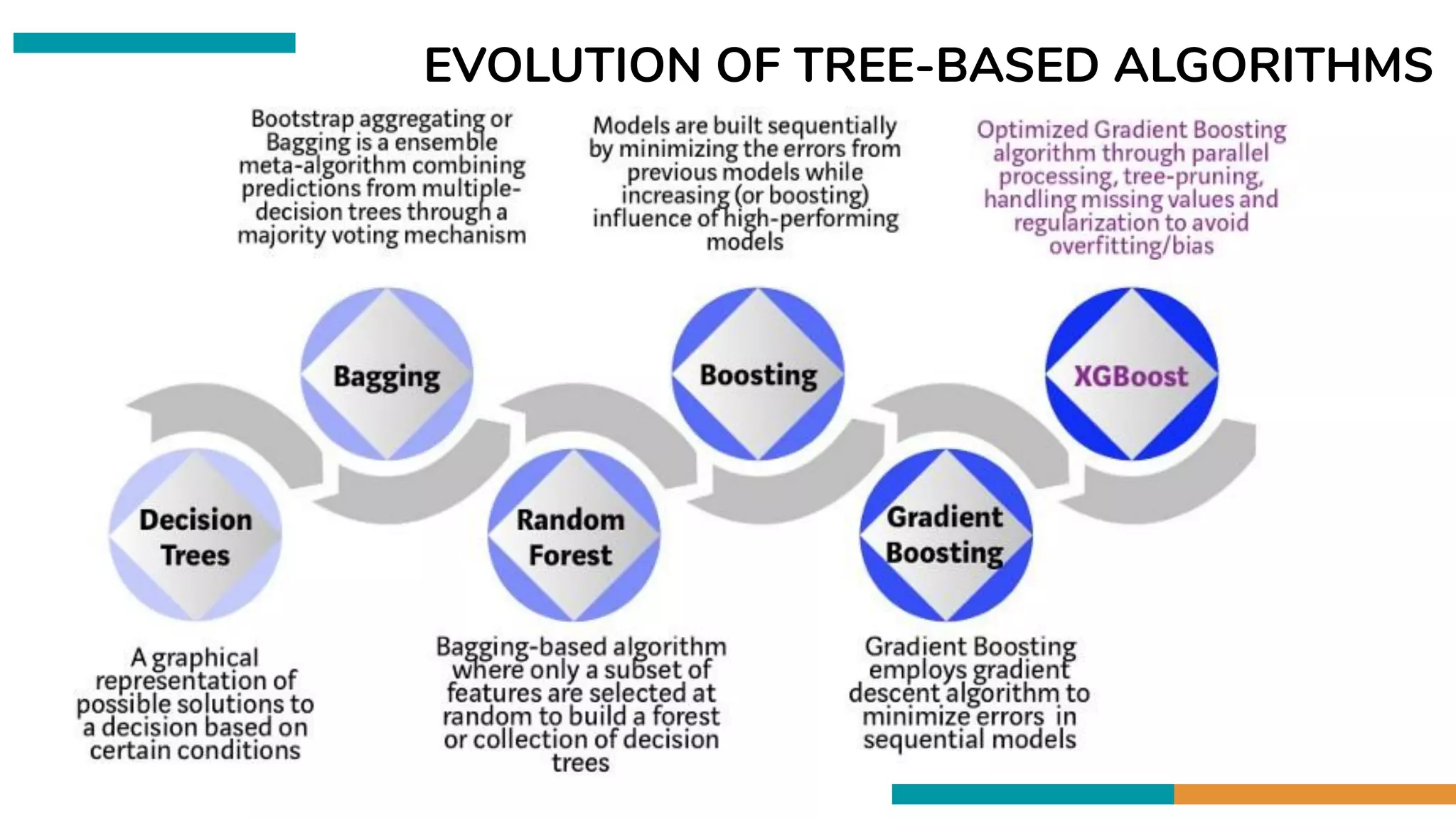
●Evolution of Tree Based Algorithms
● Why does XGBoost perform so well
● King of all algorithms
● Boosting
● Ensemble method
● Kaggle projects that uses XGBoost
● XGBoost on Code
3.
What is XGBoost
XGBoostis a decision-tree-based
ensemble Machine Learning
algorithm that uses a gradient
boosting framework. In prediction
problems involving unstructured
data (images, text, etc.)
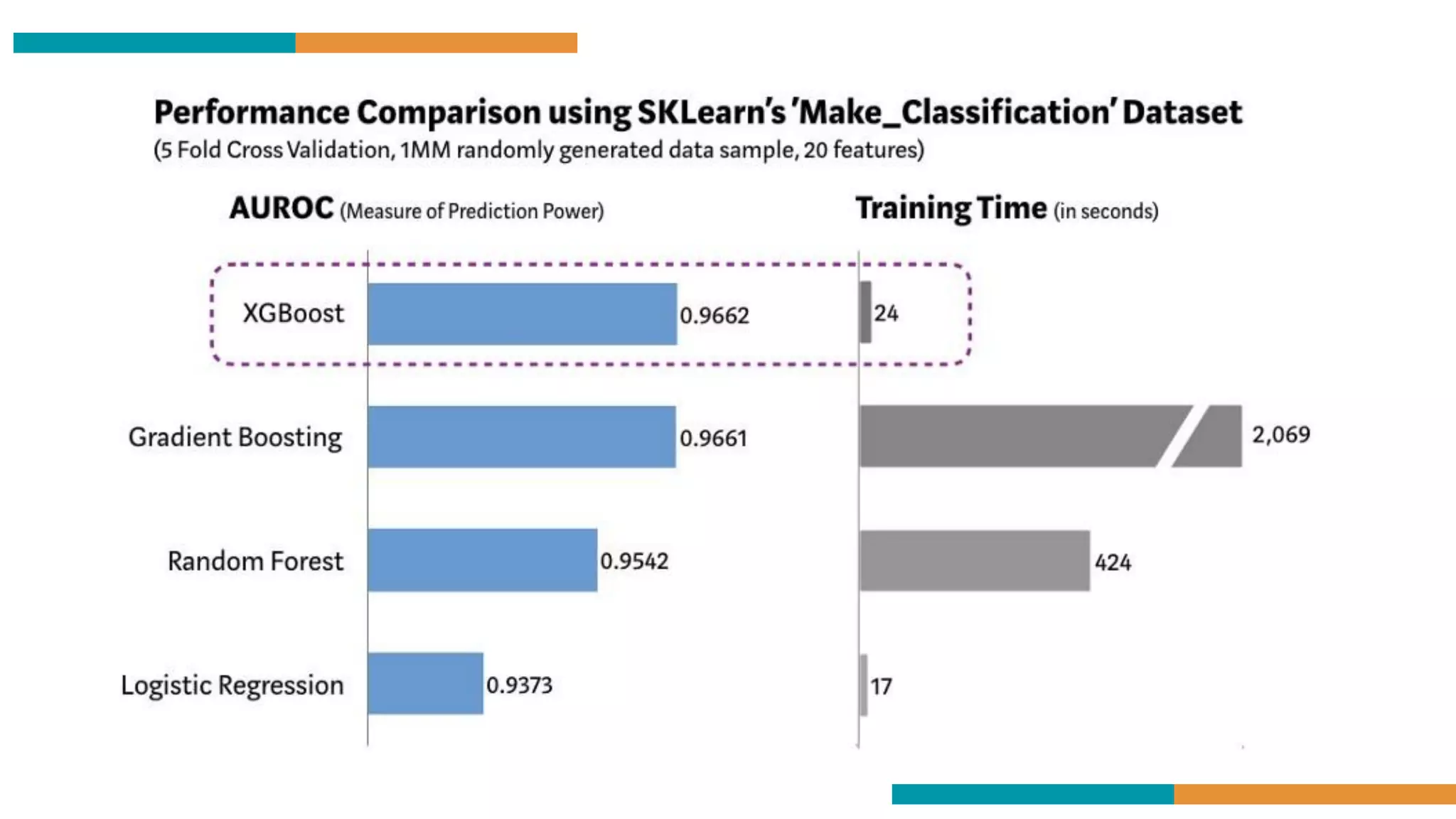
Why is XGBoostthe King of all other machine learning Algorithm
Speed and
performance :
Originally written in
C++, it is comparatively
faster than other
ensemble classifiers and
useful for very large
datasets that don’t fit
into memory.
Consistently outperforms
other algorithm methods :
It has shown better
performance on a variety
of machine learning
benchmark datasets.Wide variety of tuning
parameters : XGBoost
internally has parameters for
cross-validation, regularization,
user-defined objective
functions, missing values, tree
parameters, scikit-learn
compatible API etc.
Cross validation is
80/20Data Spliting
Boosting
Boosting is a sequential technique which works
on the principle of an ensemble. It combines a
set of weak learners and delivers improved
prediction accuracy
12.
Cross validation is
80/20Data Spliting
Boosting
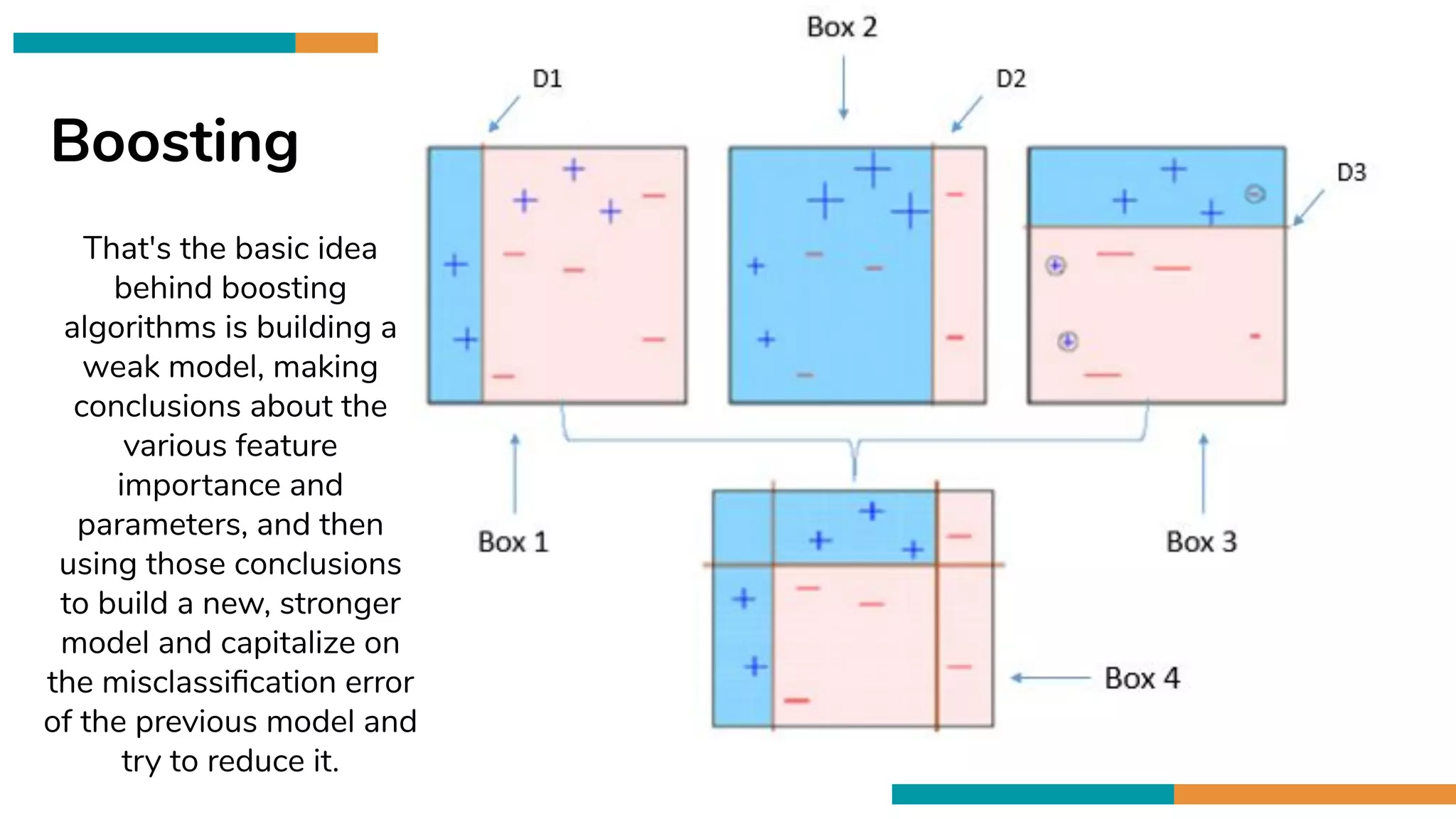
That's the basic idea
behind boosting
algorithms is building a
weak model, making
conclusions about the
various feature
importance and
parameters, and then
using those conclusions
to build a new, stronger
model and capitalize on
the misclassification error
of the previous model and
try to reduce it.
13.
Ensemble Methods
ensemble methodsuse multiple learning algorithms to obtain
better predictive performance than could be obtained from
any of the constituent learning algorithms alone.
14.
So should weuse just XGBoost all the time?
When it comes to Machine Learning (or
even life for that matter), there is no free
lunch.
16.
Cross validation is
80/20Data Spliting
Kaggle Projects the uses XGBoost
● Predicting Gold Glove
● Sloan Digital Sky Survey Classification
● Boston Housing Price
● Santander Customer Transaction Prediction
● Microsoft malware prediction etc
17.
Cross validation is
80/20Data Spliting
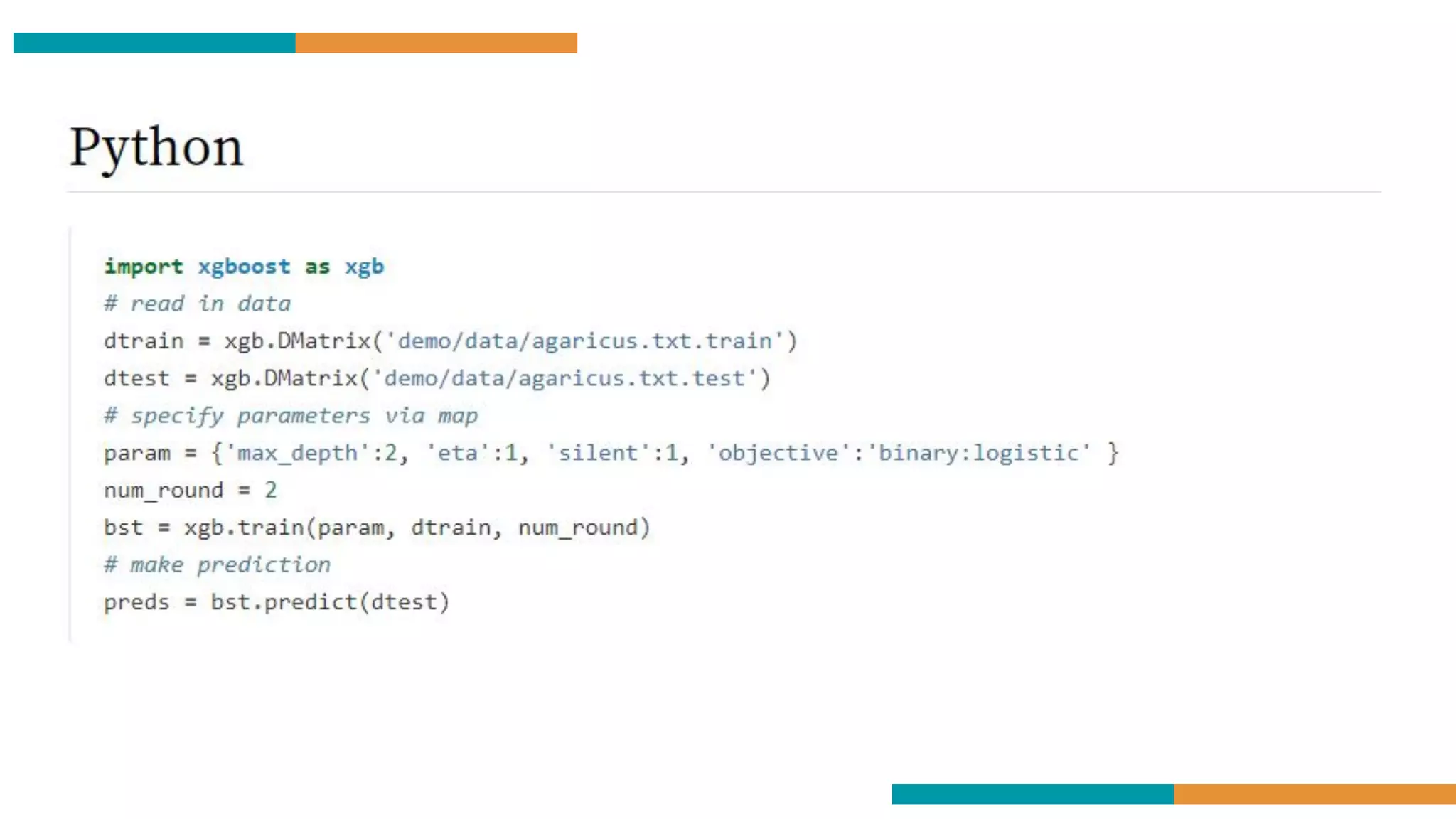
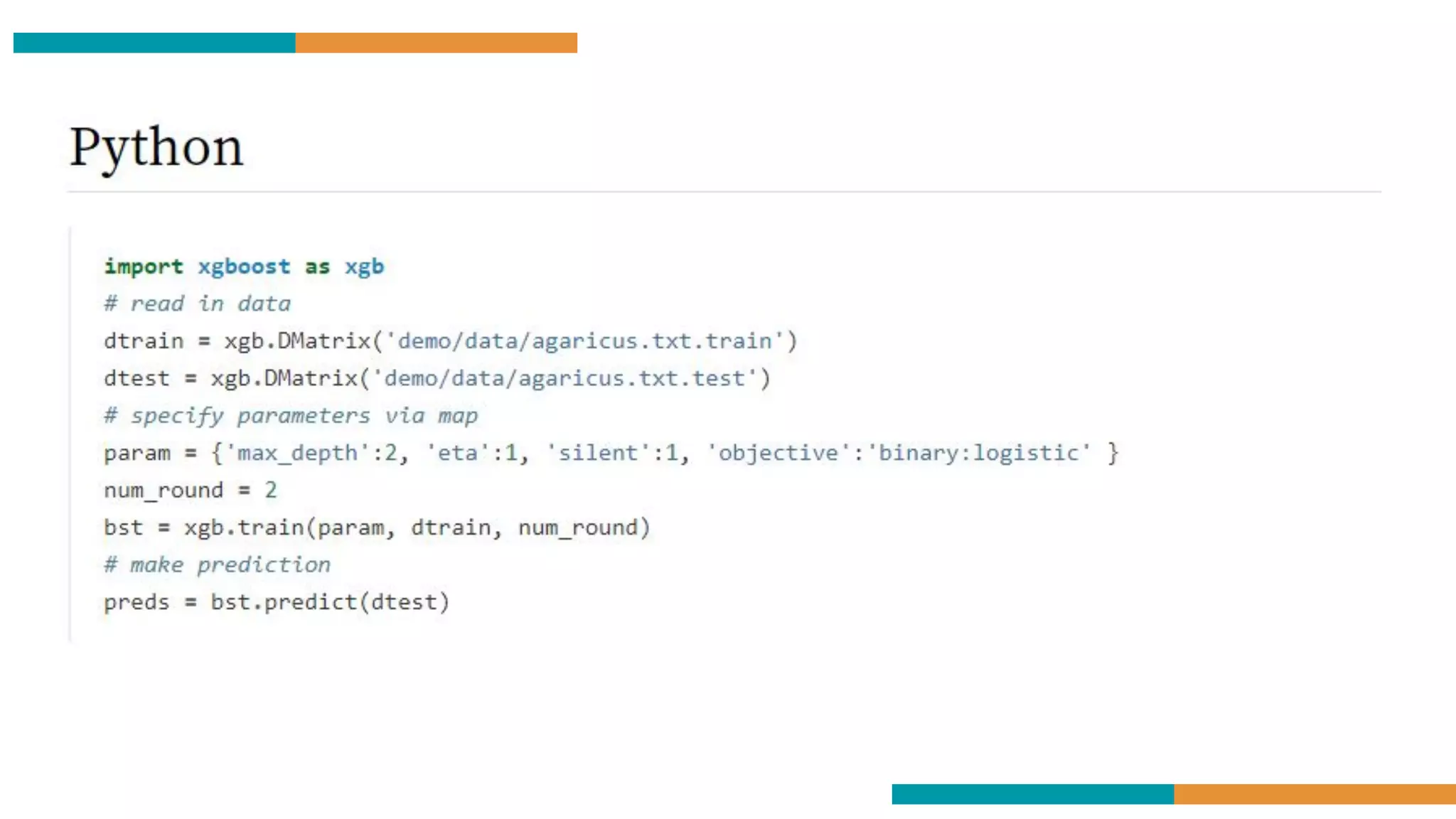
XGBoost on Code
Using the XGBoost Regressor is just like using any other
regression-based approach like Random Forest. We follow the
same methods:
● Clean the Data
● Select the important parameters
● Make a training and test set
● Fit the model to your training set
● Evaluate your model on your test data
21.
Thank you
Datacamp Instructor|
Simpliv | Head Boy at
Gitgirl
Co- Organiser Pydata
Port Harcourt |
Phschoolofai
@emekaboris









































![XGBOOST [Autosaved]12.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/xgboostautosaved12-230501140101-a562c3ba-thumbnail.jpg?width=640&height=640&fit=bounds)






































