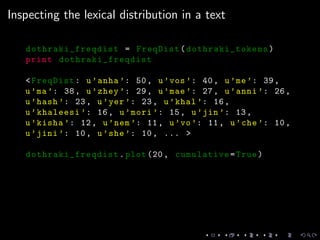
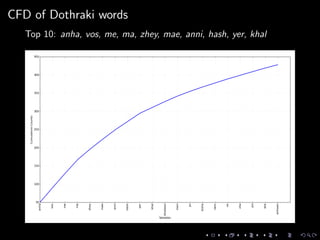
Downloaded 11 times





![Importing raw text
dothraki_f = codecs.open(
"/home/cr/Python/westeros/dothraki.txt",
encoding=’utf -8’)
dothraki_raw = dothraki_f.read ()
print dothraki_raw
Athchomar chomakaan , [zhey] khal vezhven. Azha
anhaan asshilat ... Itte oakah! Jadi , zhey Jora
Andahli. Khal vezhven. Ajjalan anha zalat vitiherat
yer hatif. Kash qoy qoyi thira disse. Hash shafka
zali addrivat mae , zhey Khaleesi? Ishish chare
...](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-5-320.jpg)
![Text processing: Cleaning
punct_re = re.compile(
ur’[. ,;:?! u2014u2019u2026 []] ’,
re.UNICODE)
dothraki_proc = punct_re.sub(’’, dothraki_raw)
dothraki_proc = dothraki_proc.lower ()
print dothraki_proc
athchomar chomakaan zhey khal vezhven azha anhaan
asshilat itte oakah jadi zhey jora andahli khal
vezhven ajjalan anha zalat vitiherat yer hatif kash
qoy qoyi thira disse
...](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-6-320.jpg)
![Text processing: Tokenizing
dothraki_tokens = re.split(ur’s+’, dothraki_proc)
dothraki_types = set(dothraki_tokens )
print dothraki_types
set([u’izzi ’, u’ale’, u’morea ’, u’vesazhao ’,
u’yeri ’, u’ishish ’, u’dalen ’, u’vesazhae ’, u’yera ’,
u’afisi ’, u’rhae ’, u’mawizzi ’, u’vee’, u’arrisse ’,
u’ti’, u’ven’, u’rizh ’, u’afichak ’, u’gache ’,
u’zigerek ’, u’zigereo ’, u’drivoe ’, u’maaz ’,
u’zigeree ’, u’ayyeyoon ’, u’maan ’, u’mahrazhi ’,
u’ma’, u’vos’, u’movekkhi ’, u’mahrazhis ’,
u’meshafka ’, u’qisi ’, u’sani ’, u’ville ’, u’vikeesi ’,
u’ifak ’, u’javrathi ’, u’zisa ’, u’chek ’, u’nem’,
...
])](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-7-320.jpg)

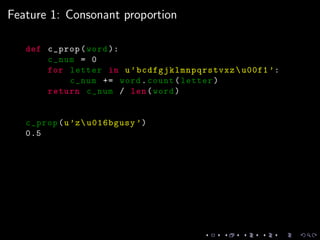

![Feature 3: Coda presence
def c_coda(word ):
if word [-1] in u’bcdfgjklmnpqrstvxz u00f1 ’:
return 1
else:
return 0
def obstruent_coda (word ):
if word [-1] in u’bcdfgjkpqstvxz ’:
return 1
else:
return 0
c_coda(u’lysoon ’)
1
obstruent_coda (u’lysoon ’)
0](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-15-320.jpg)
![Feature 4: Consonant clusters
regex = ur’[ bcdfghjklmnpqrstvxz u00f1]
[ bcdfghjklmnpqrstvxz u00f1 ]+’
def c_cluster(word ):
cc_set = re.findall(regex , word , re.UNICODE)
return len(cc_set)
c_cluster(u’avvirsosh ’)
3](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-18-320.jpg)
![Feature 5: Obstruent clusters
regex1 = ur’[bcdfghjkpqstvxz ][ bcdfghjkpqstvxz ]+’
def obs_cluster(word ):
oo_set = re.findall(regex1 , word , re.UNICODE)
return len(oo_set)
obs_cluster(u’avvirsosh ’)
2](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-20-320.jpg)
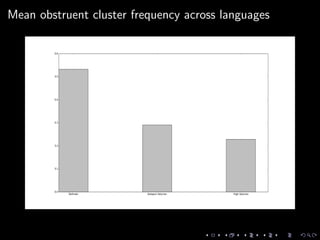
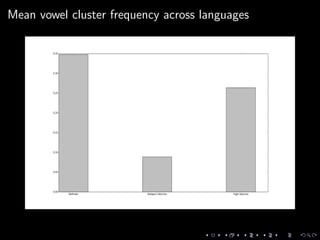
![Feature 6: Vowel clusters
regex2 = ur’[ bcdfghjklmnpqrstvxz u00f1 ]+’
def v_cluster(word ):
v_set = re.split(regex2 , word , re.UNICODE)
vv_set = [v for v in v_set if len(v) > 1]
return len(vv_set)
v_cluster(u’haeshi ’)
1](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-22-320.jpg)


![Assamese corpus files
directory = "/home/cr/Documents/NLPwP_pres/
TDIL_assamese_corpus_data "
os.listdir(directory)
[’subj_art2.txt’, ’subj_politics1 .txt’, ’lit3.txt’,
’drama.txt’, ’religion2.txt’, ’criticism2.txt’,
’criticism1.txt’, ’subj_science3.txt’,
’ref_encyclopaedia -entry.txt’, ’subj_science2.txt’,
’subj_social -studies.txt’, ’music.txt’, ’subj_art1.txt
’subj_science1.txt’, ’subj_art3.txt’, ’news.txt’,
’subj_sociology .txt’, ’criticism3.txt’, ’lit8.txt’,
’subj_history1.txt’, ’lit4.txt’, ’lit6.txt’, ’religion
’subj_law.txt’, ’lit7.txt’, ’religion1.txt’, ’criticis
’lit5.txt’, ’subj_math.txt’, ’lit1.txt’, ’subj_science
’subj_science_5 .txt’, ’subj_history2.txt’, ’lit2.txt’,
’subj_science4.txt’, ’letter.txt’]](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-27-320.jpg)
![Frequency of the sound /x/ in ’lit5.txt’
len(re.findall(ur’[ u09b6u09b7u09b8]’,
assamese_sample_raw , re.UNICODE ))
1313
len(re.findall(ur’u09b6 ’, assamese_sample_raw ,
re.UNICODE ))
298
len(re.findall(ur’u09b7 ’, assamese_sample_raw ,
re.UNICODE ))
195
len(re.findall(ur’u09b8 ’, assamese_sample_raw ,
re.UNICODE ))
820](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-29-320.jpg)
![Positional restrictions
Beginning a word:
len(re.findall(ur’b[ u09b6u09b7u09b8]’,
assamese_sample_raw , re.UNICODE ))
1129
Ending a word:
len(re.findall(ur’[ u09b6u09b7u09b8 ]b’,
assamese_sample_raw , re.UNICODE ))
895](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-30-320.jpg)
![Positional restrictions
Following /a/:
len(re.findall(ur’u09be [ u09b6u09b7u09b8]’,
assamese_sample_raw , re.UNICODE ))
57
Following /i/:
len(re.findall(ur’[ u09bfu09c0 ][ u09b6u09b7u09b8]’,
ssamese_sample_raw , re.UNICODE ))
70
Following /u/:
len(re.findall(ur’[ u09c1u09c2 ][ u09b6u09b7u09b8]’,
assamese_sample_raw , re.UNICODE ))
10](https://image.slidesharecdn.com/nlpwpmeetuppres-140822104734-phpapp02/85/Natural-Language-Processing-SupStat-Inc-31-320.jpg)



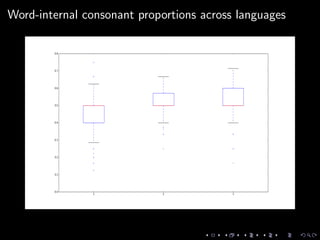
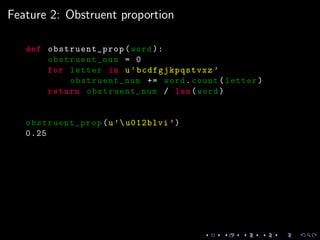
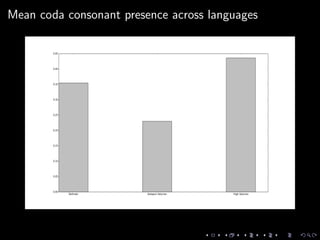
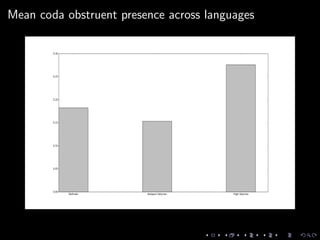
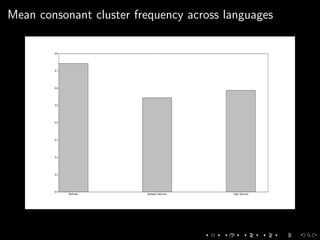
This document discusses natural language processing tasks related to analyzing fictional languages from the book series A Song of Ice and Fire. It presents code samples in Python using the NLTK library to process text samples in Dothraki, Astapori Valyrian, and High Valyrian: cleaning and tokenizing text, calculating word frequencies, and extracting phonological features to compare across the languages. It also analyzes a sample of Assamese text to determine positional restrictions and frequency of certain sounds. The document concludes with proposals for further work incorporating the phonological features into language classifiers.






































































