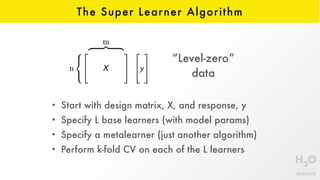
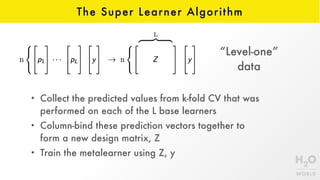
This document provides an introduction to stacking, an ensemble machine learning method. Stacking involves training a "metalearner" to optimally combine the predictions from multiple "base learners". The stacking algorithm was developed in the 1990s and improved upon with techniques like cross-validation and the "Super Learner" which combines models in a way that is provably asymptotically optimal. H2O implements an efficient stacking method called H2O Ensemble which allows for easily finding the best combination of algorithms like GBM, DNNs, and more to improve predictions.