Downloaded 73 times







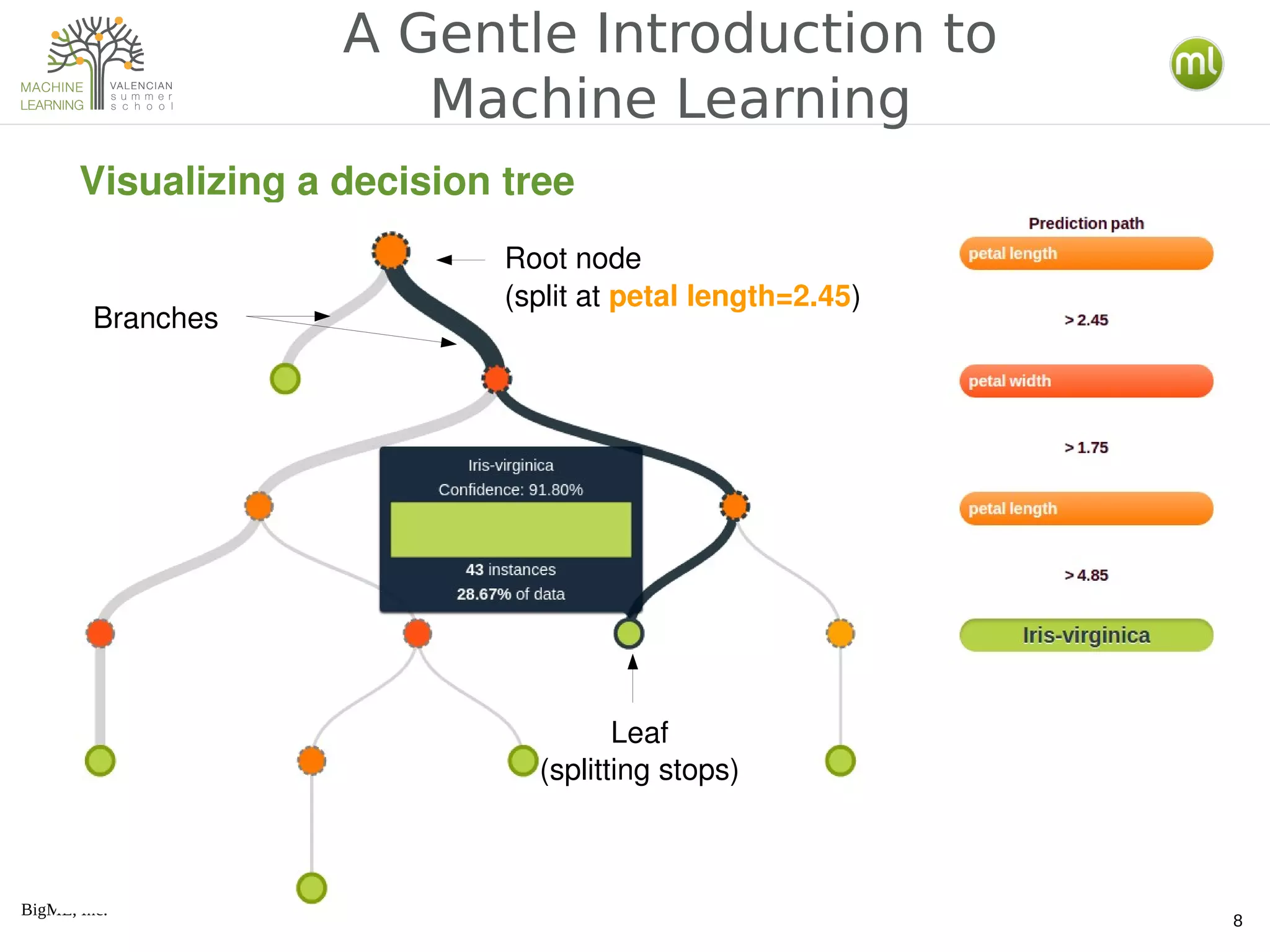


















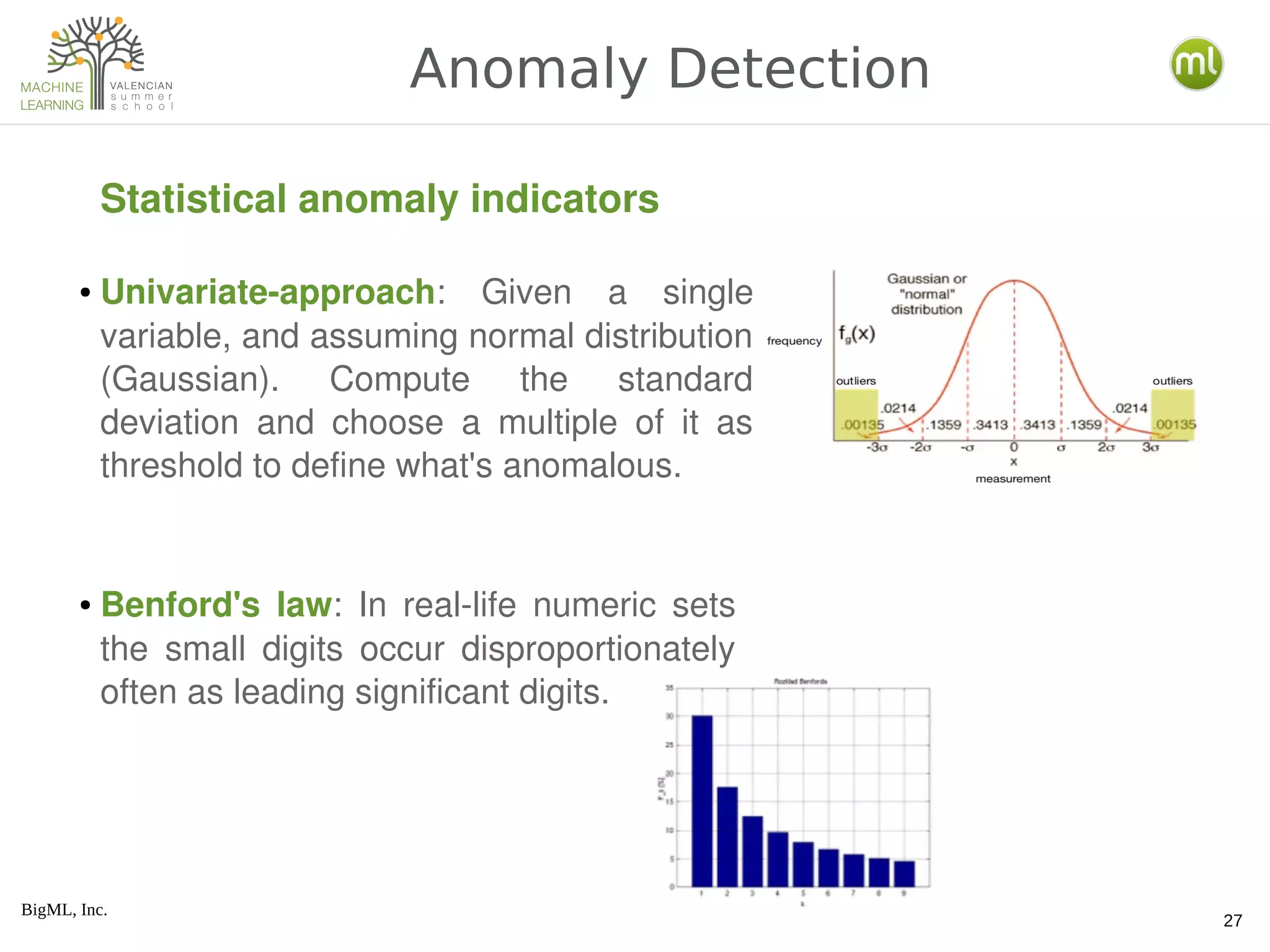





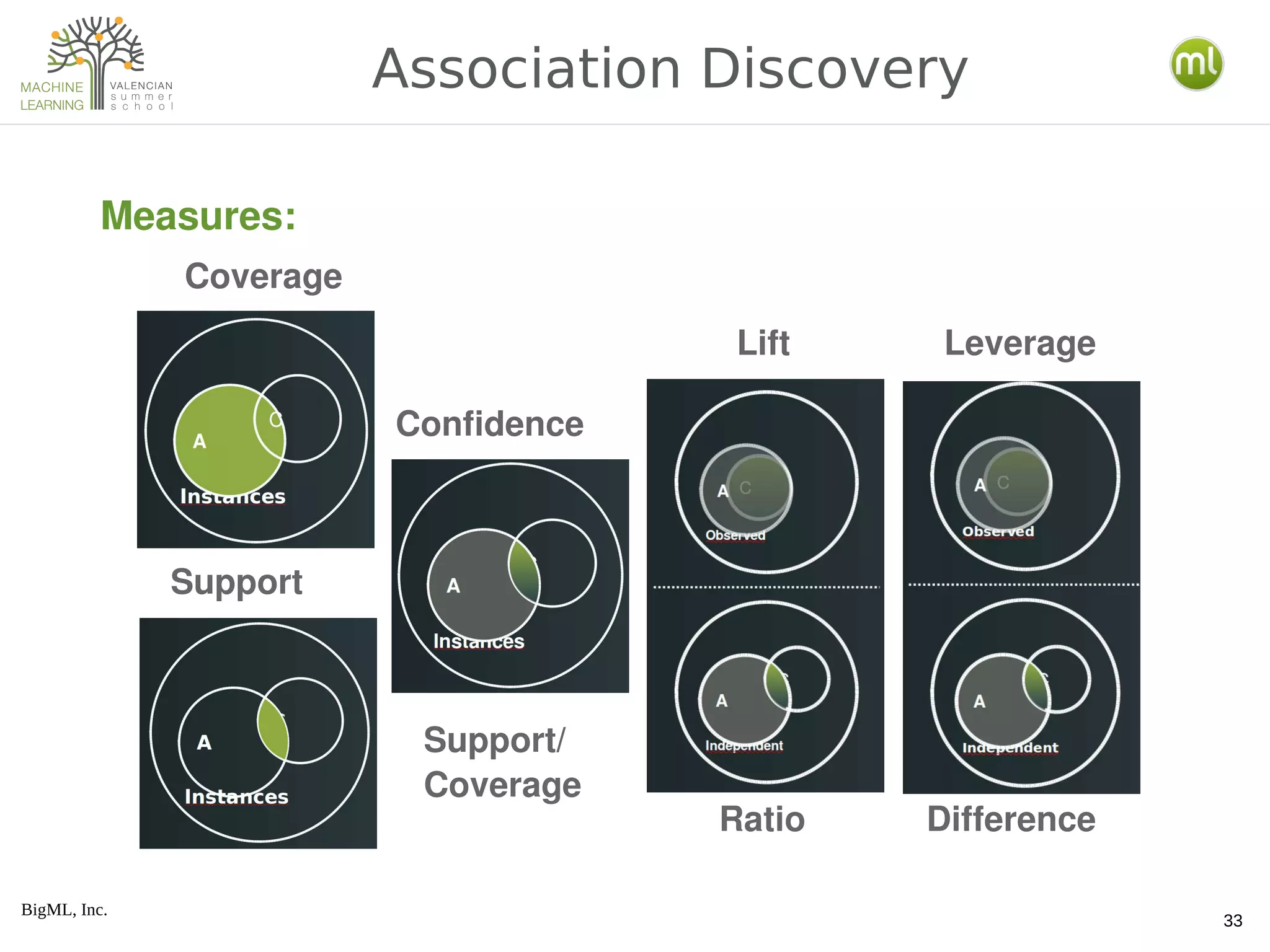
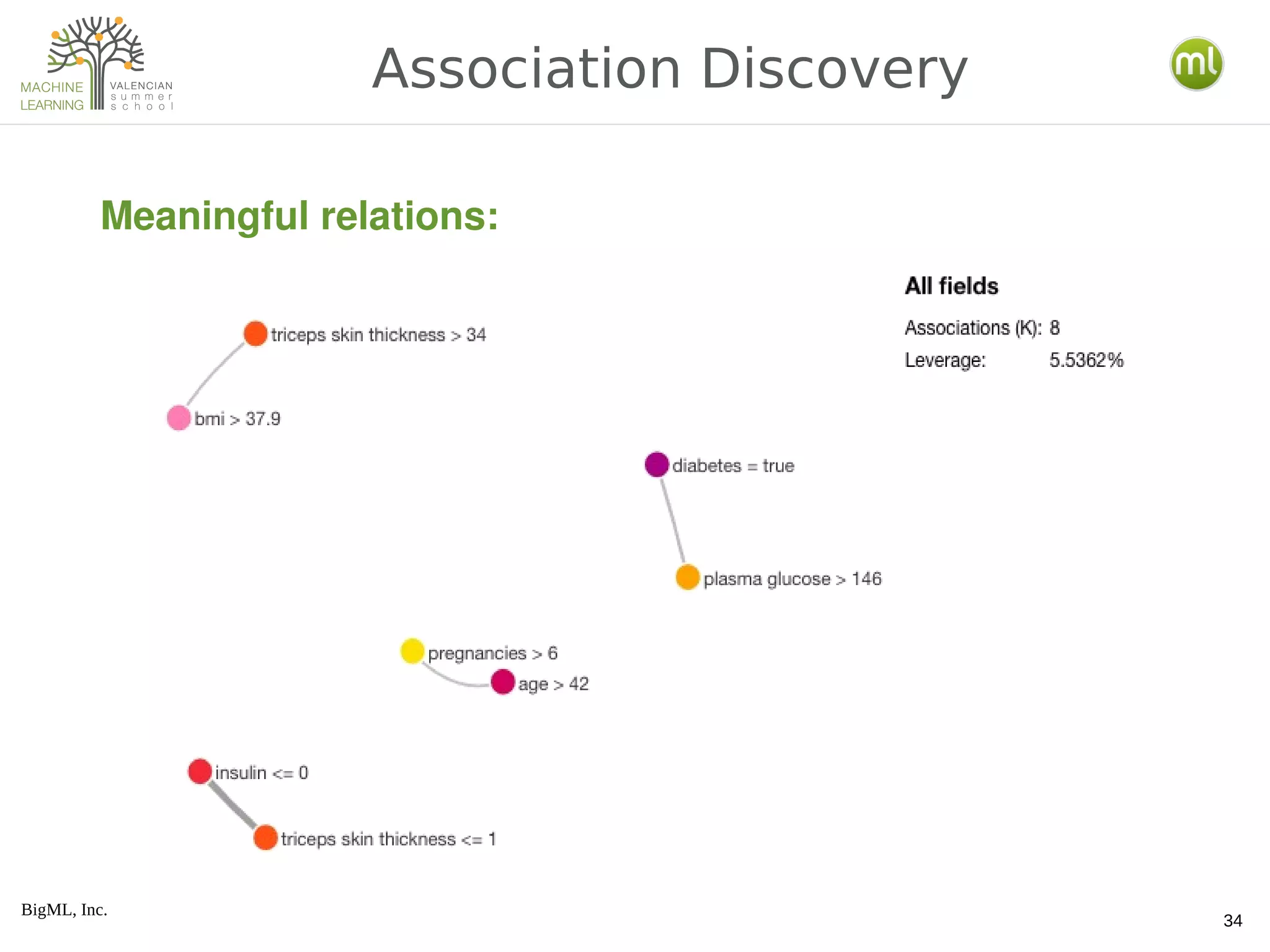





The document provides an overview of machine learning concepts including the distinction between expert-driven and data-driven decisions, the process of creating machine learning models, and various algorithms like decision trees and logistic regression. It also covers methods for model evaluation, the use of ensembles, clustering techniques, anomaly detection, and association discovery, explaining their practical applications and underlying principles. Additionally, the document discusses the differences between generative and discriminative models and introduces latent Dirichlet allocation for document analysis.






























































































