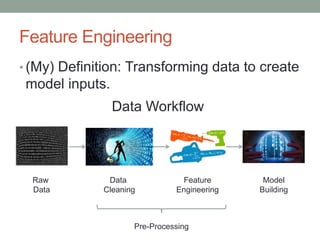
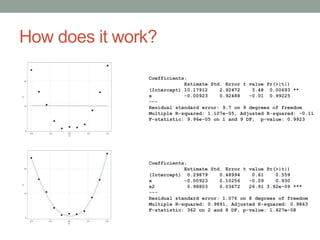
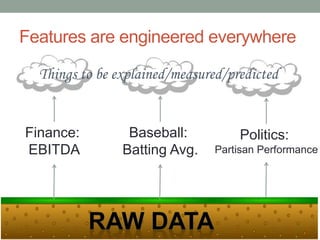
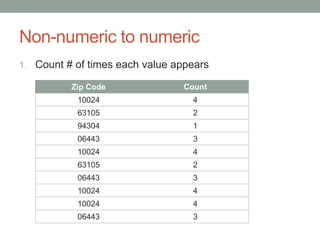
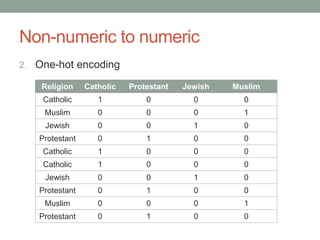
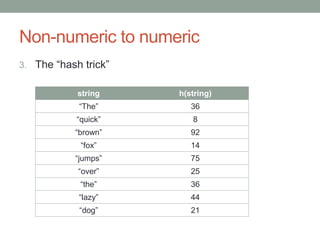
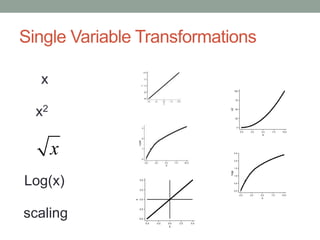
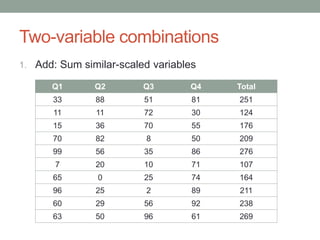
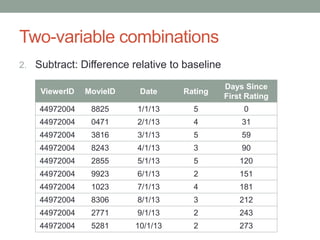
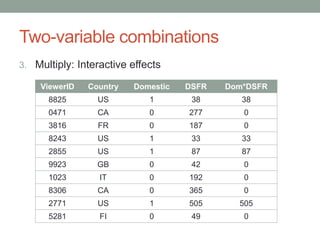
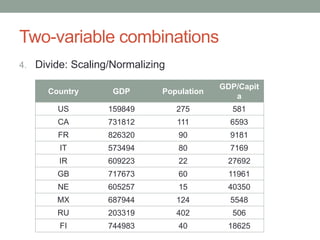
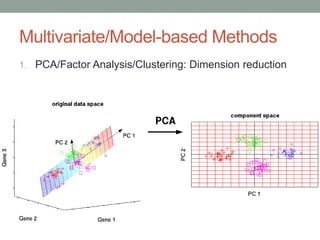
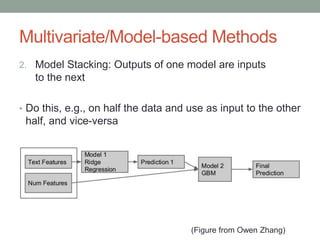
David Epstein's presentation on feature engineering at the Open Data Science Conference emphasizes its importance in transforming raw data into model inputs. He discusses the limits of feature engineering, such as overfitting and the challenge of selecting optimal feature sets, suggesting a systematic approach combining domain knowledge and standard techniques. The talk concludes that improvements in data science will largely stem from thoughtful feature engineering, which vitalizes the modeling process.