Download as PDF, PPTX



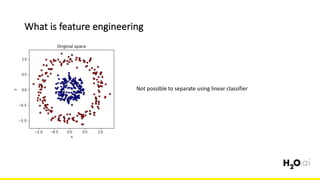




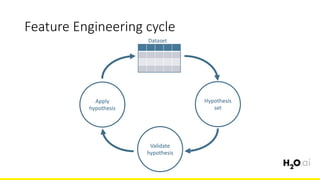
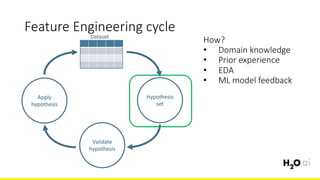
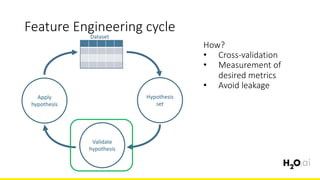



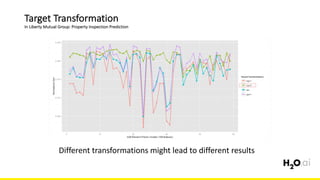



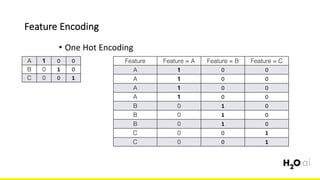
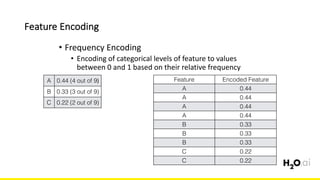
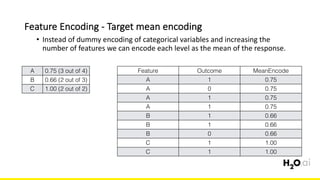

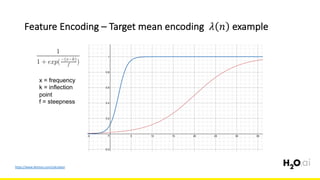
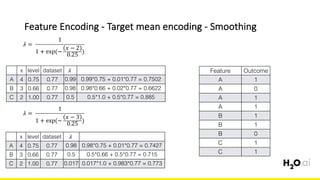
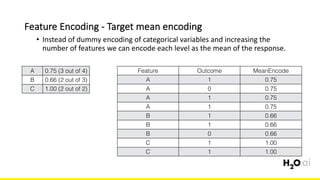
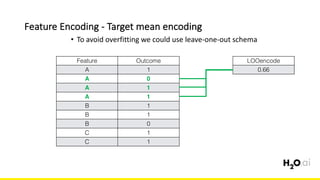
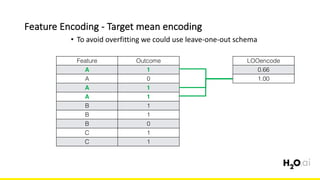
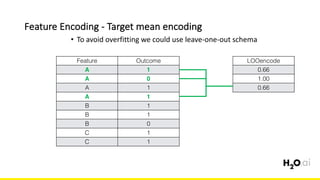
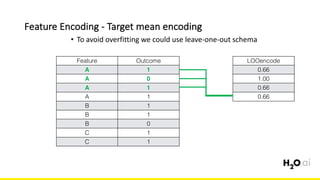

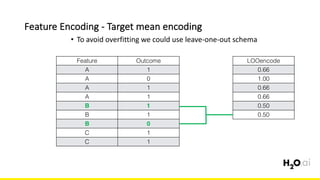

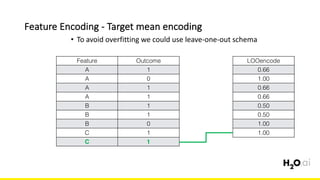
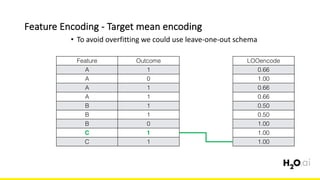

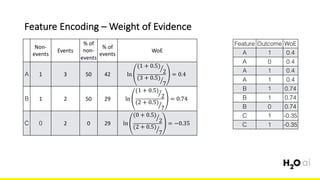



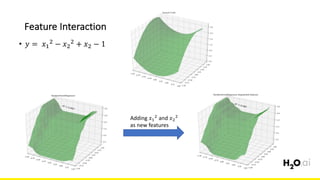






The document discusses the importance of feature engineering in machine learning, emphasizing its critical role in project success and better predictions. It outlines various techniques such as target transformation, feature encoding methods (like one-hot and label encoding), and the challenges faced during the feature engineering process, including data cleaning and domain knowledge requirements. Additionally, it covers advanced concepts like target mean encoding, weight of evidence, and feature interaction, illustrating the process of extracting new features from existing data for improved model performance.

















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





