Download to read offline




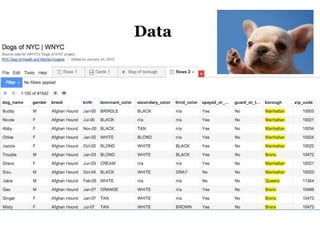


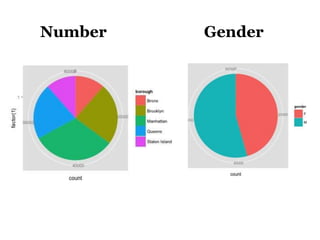
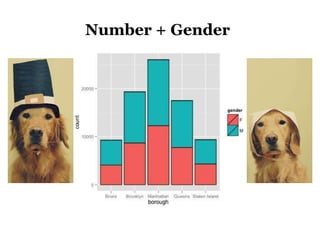
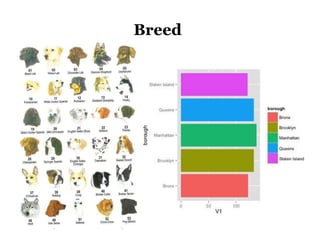
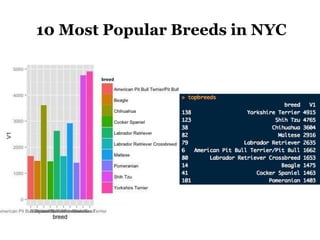

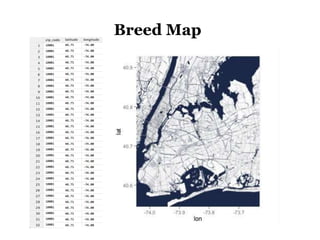
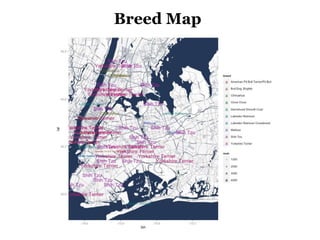
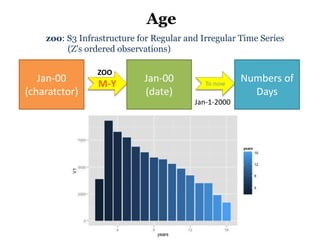
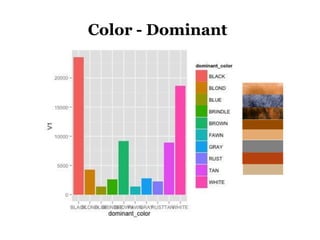
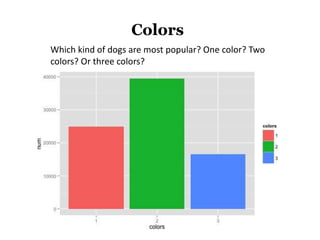
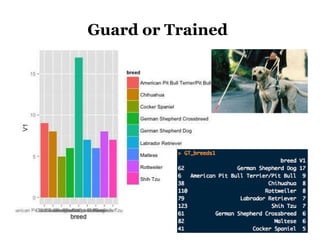

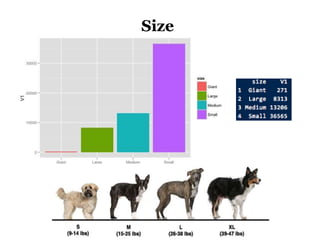



The document discusses the demographics and characteristics of dogs in New York City, focusing on aspects such as numbers, gender, breeds, age, color, and size. It lists the ten most popular dog breeds in NYC, including the Yorkshire Terrier and Shih Tzu, and mentions the use of data infrastructure for analyzing dog-related data. Additionally, it addresses the popularity of specific colors and sizes of dogs.


























































