Downloaded 21 times






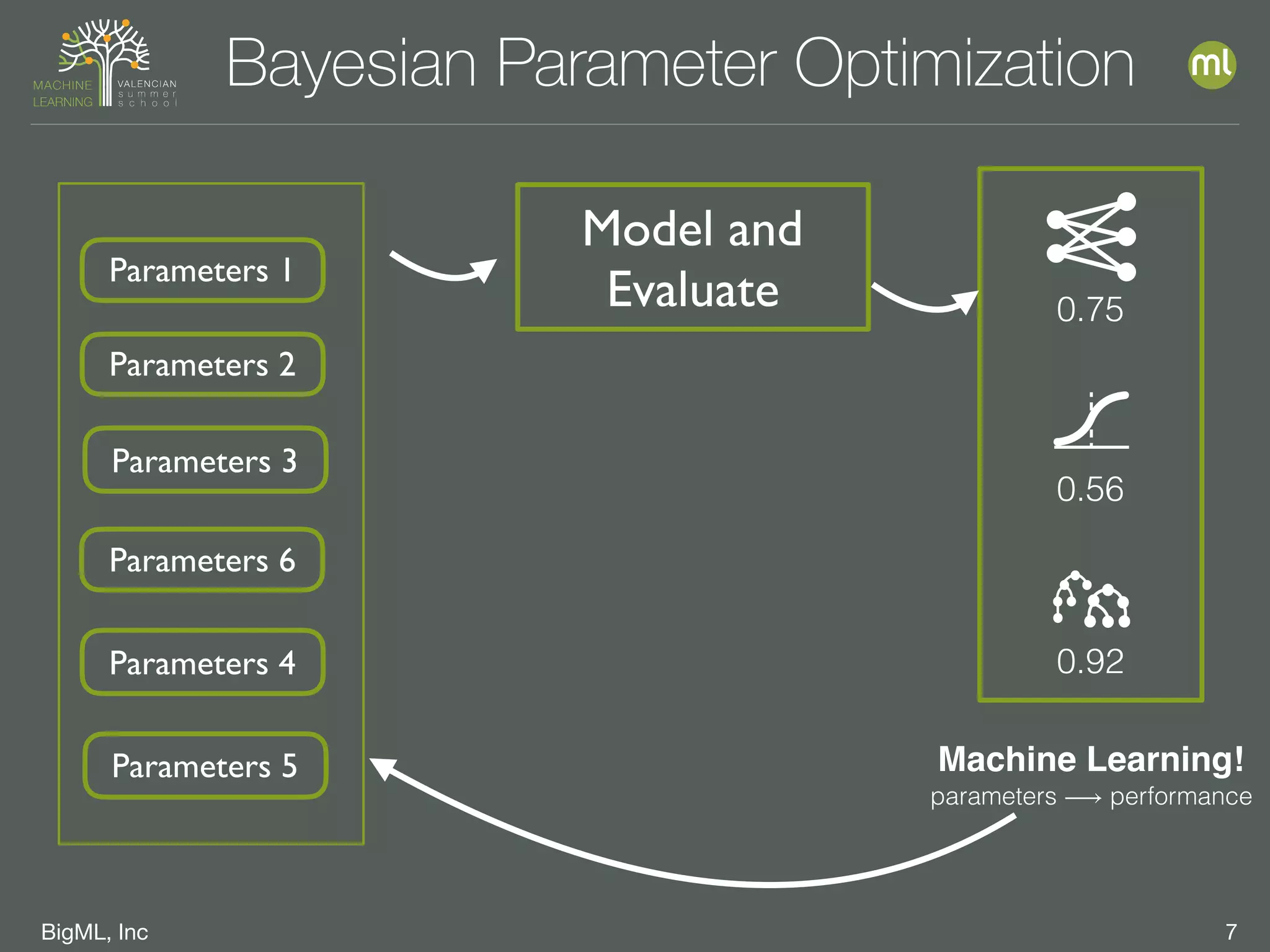


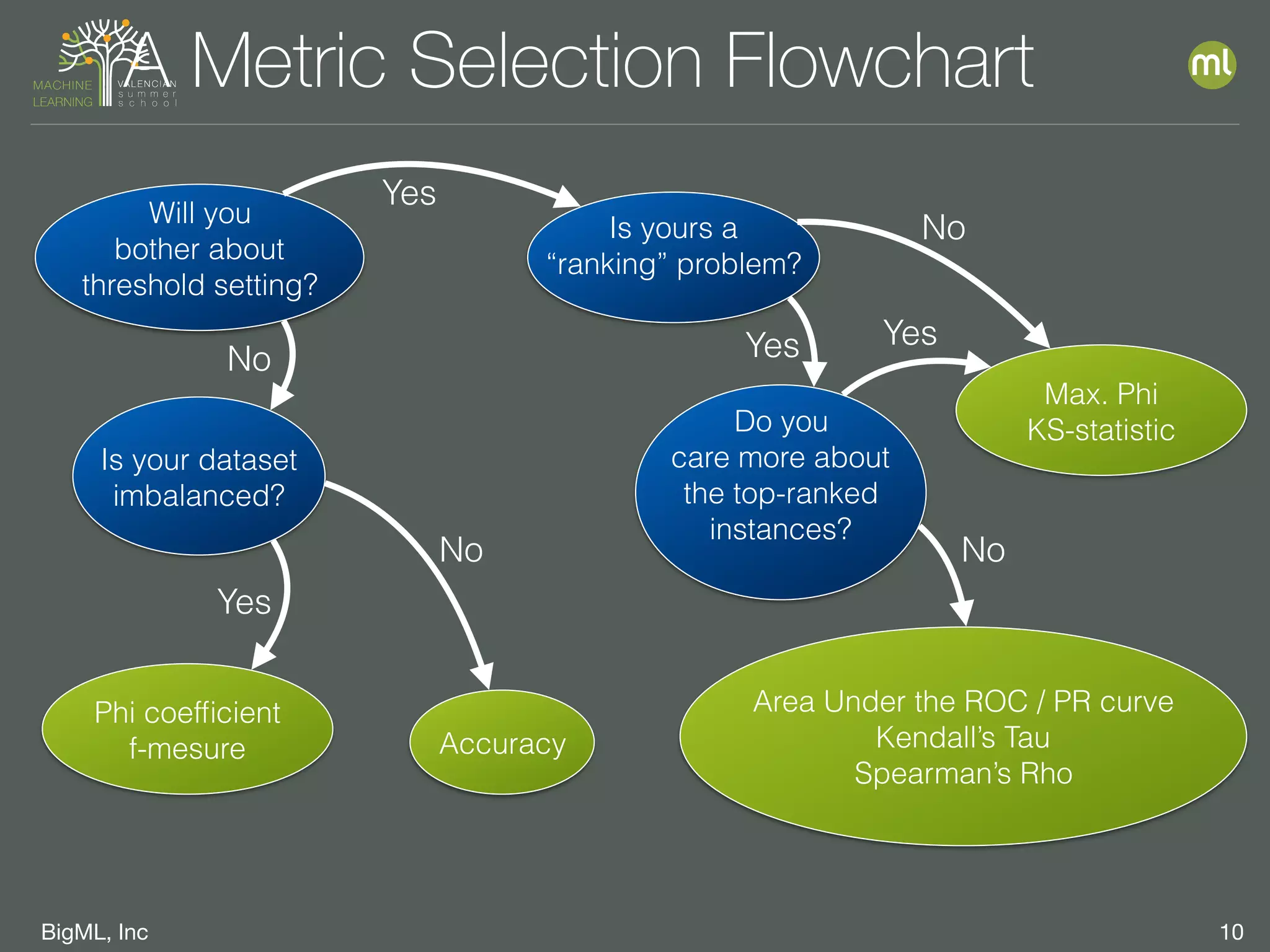
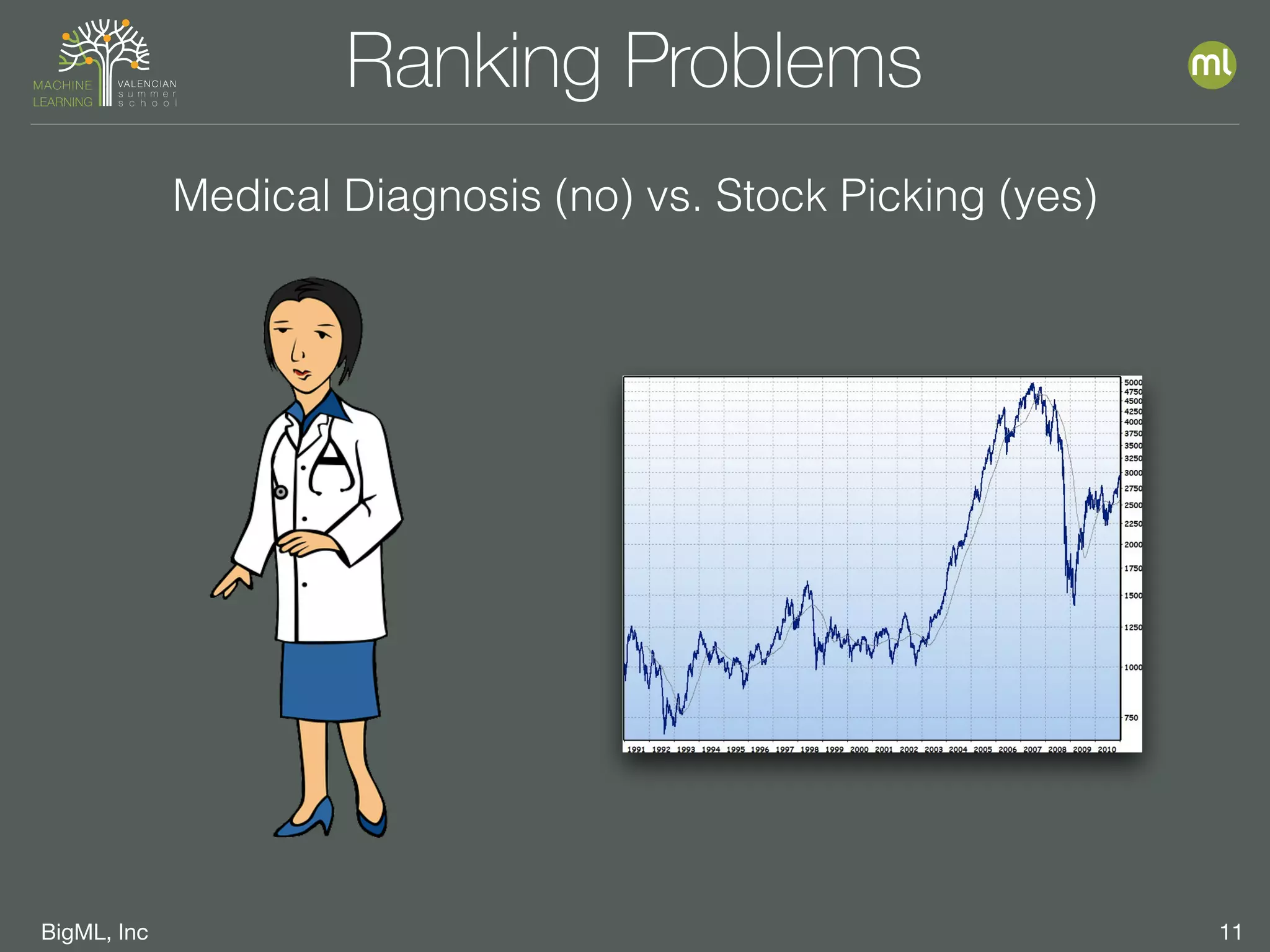








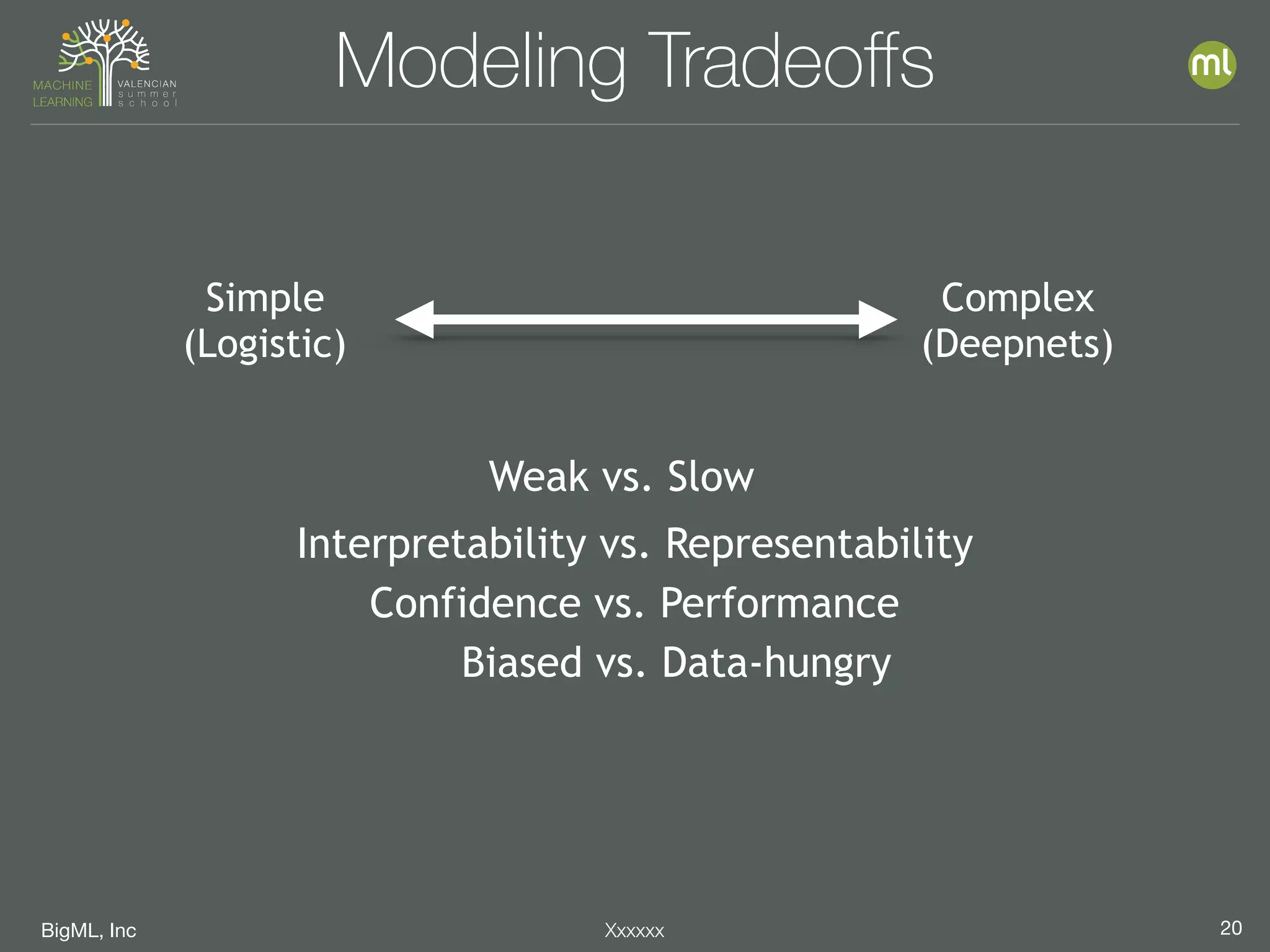







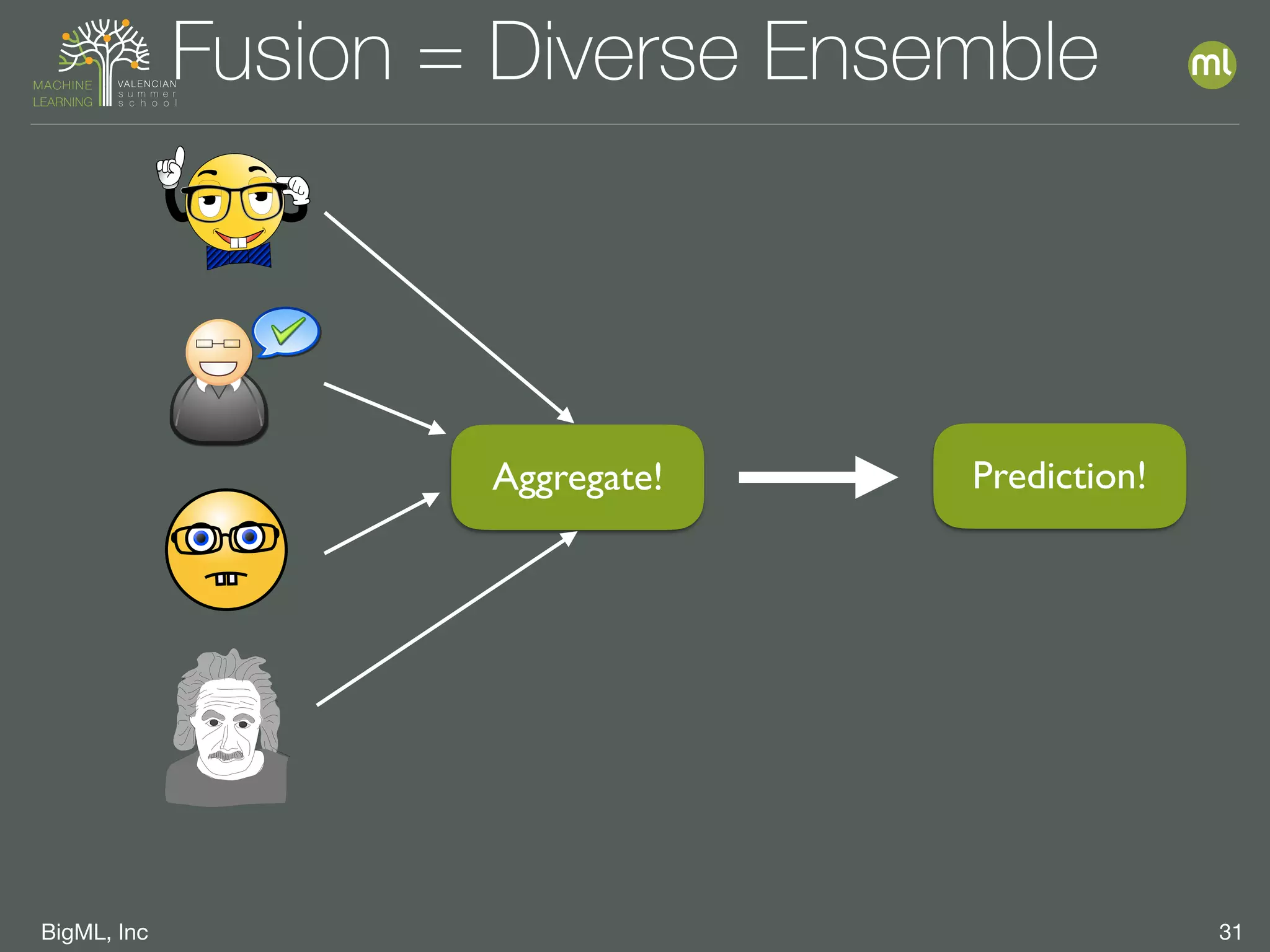
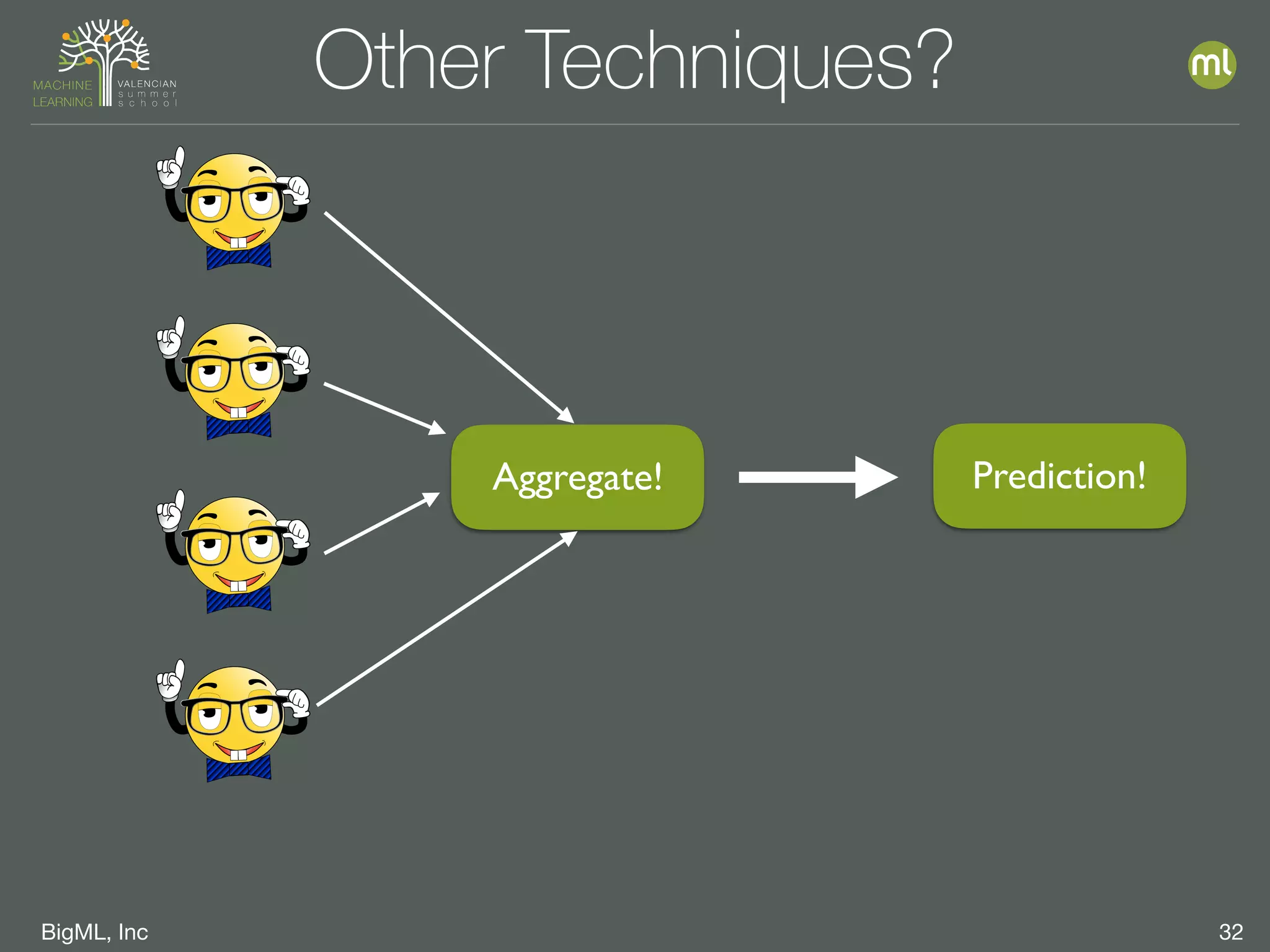
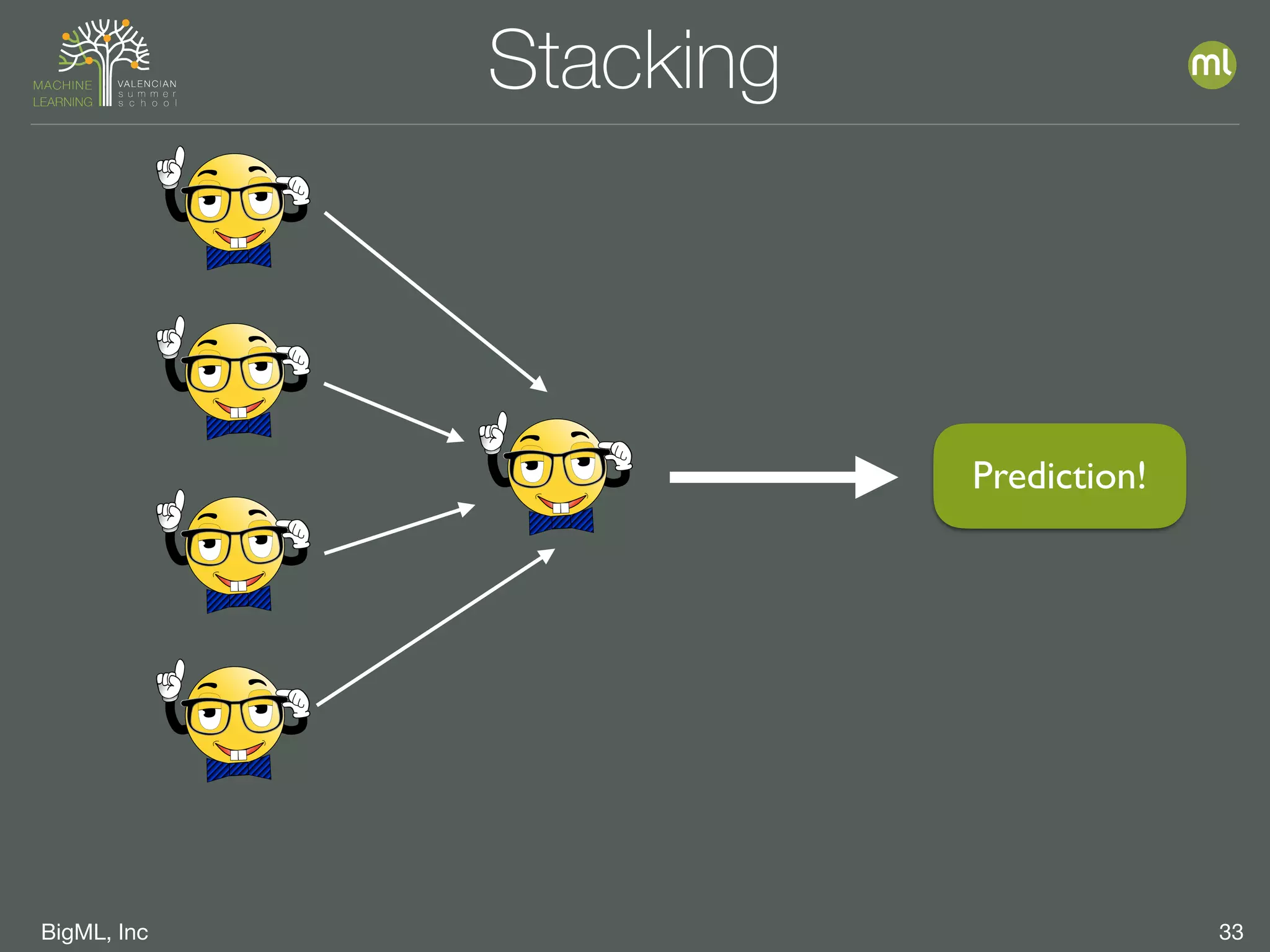
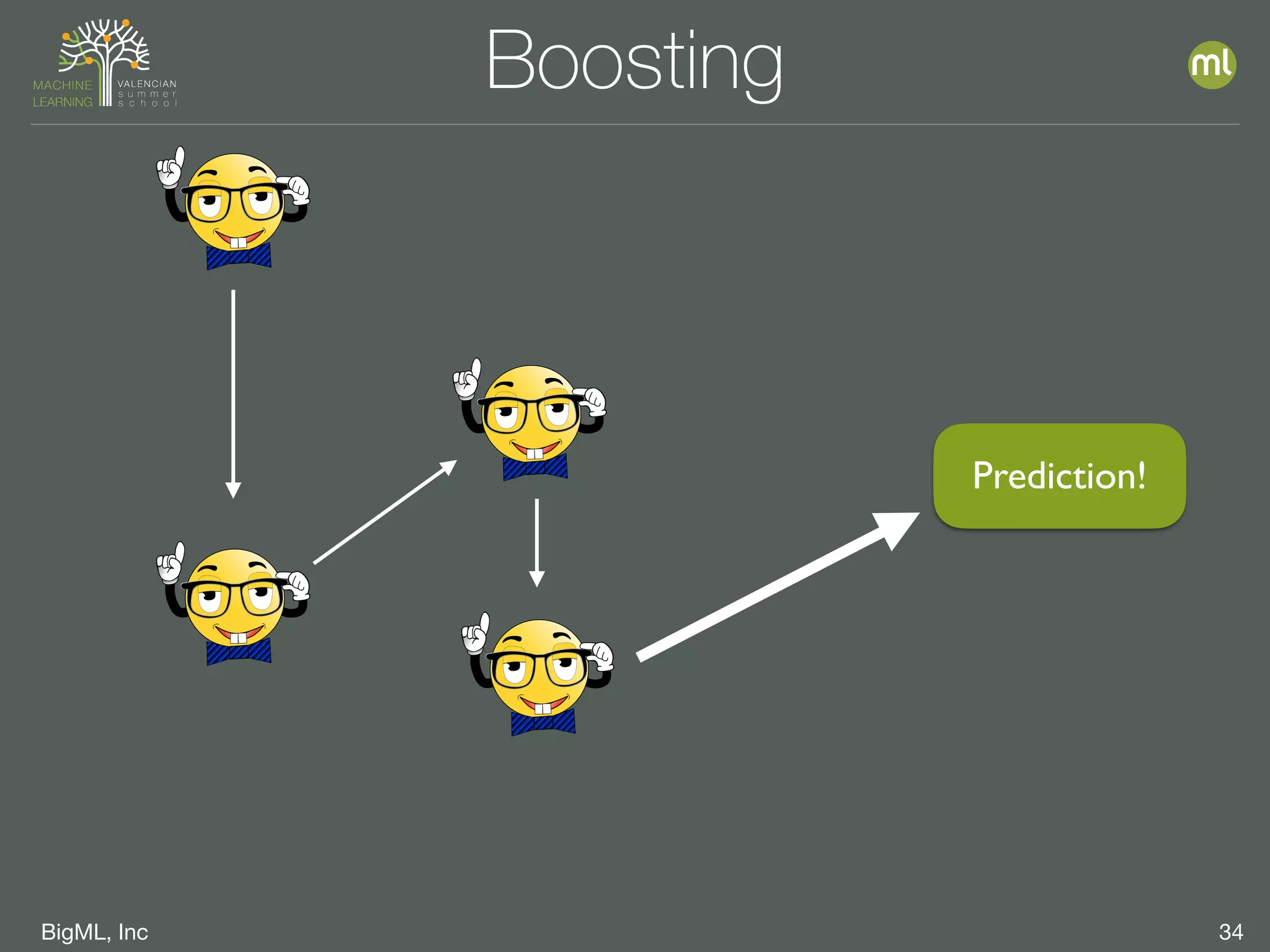





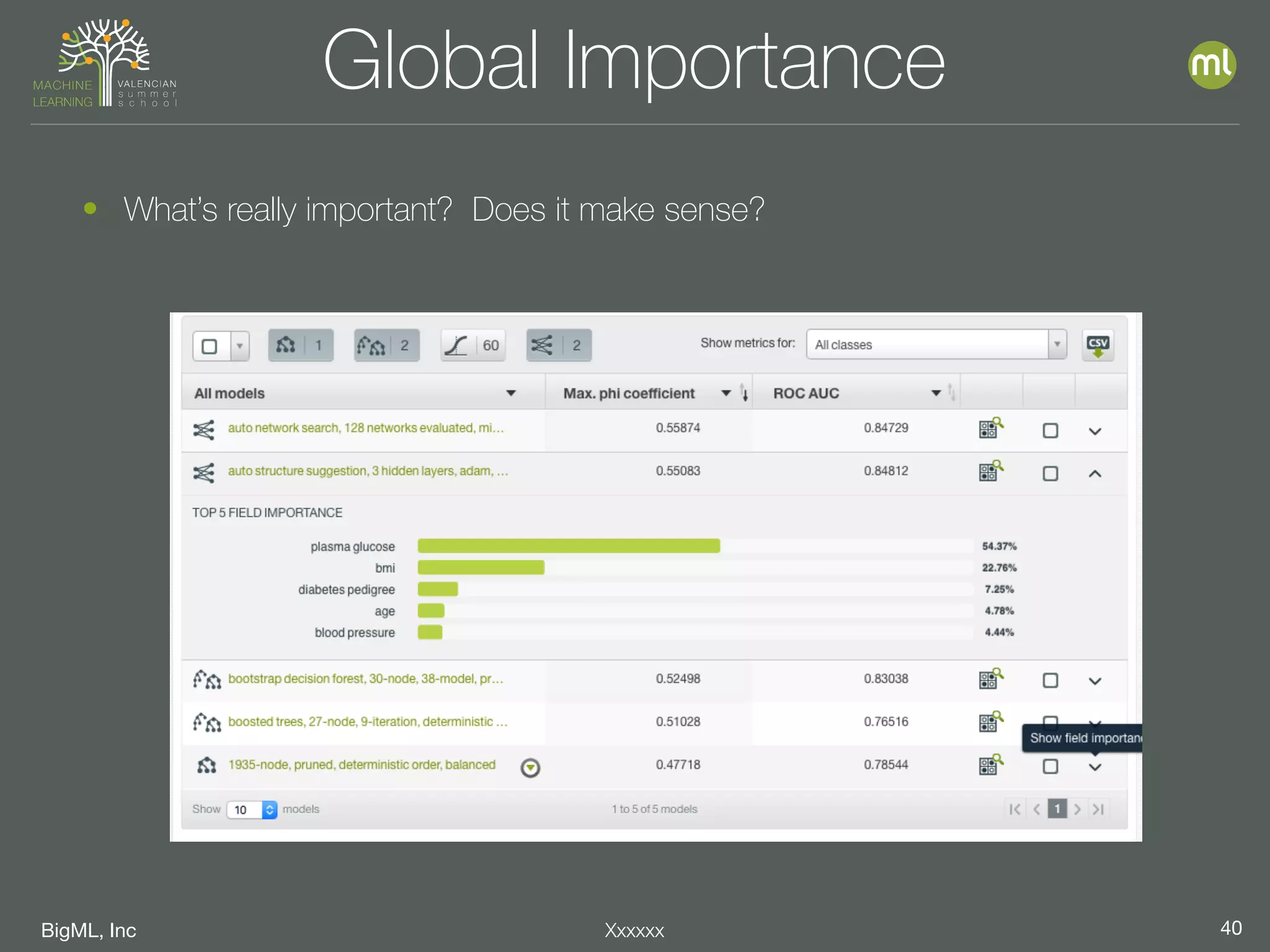
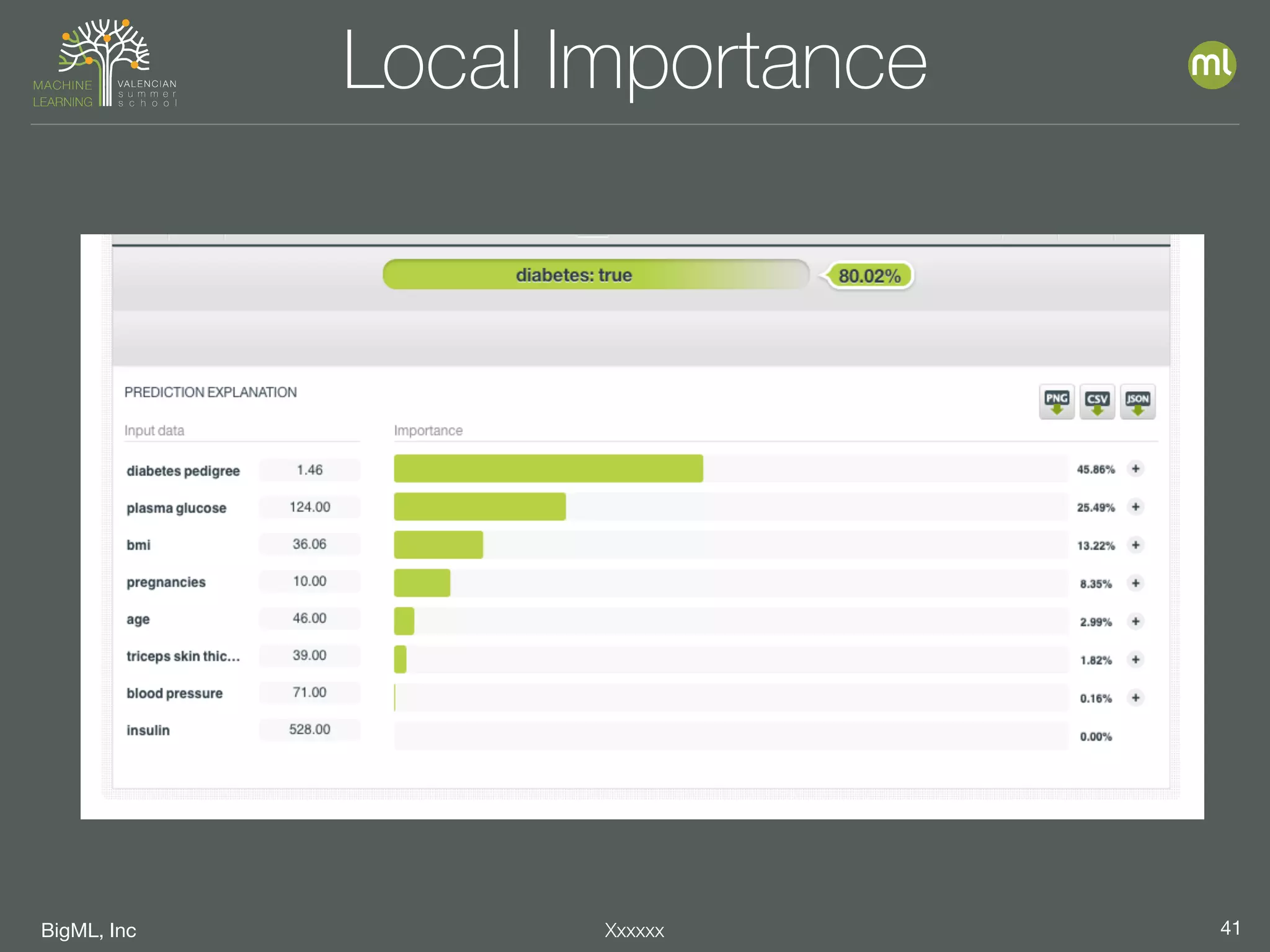


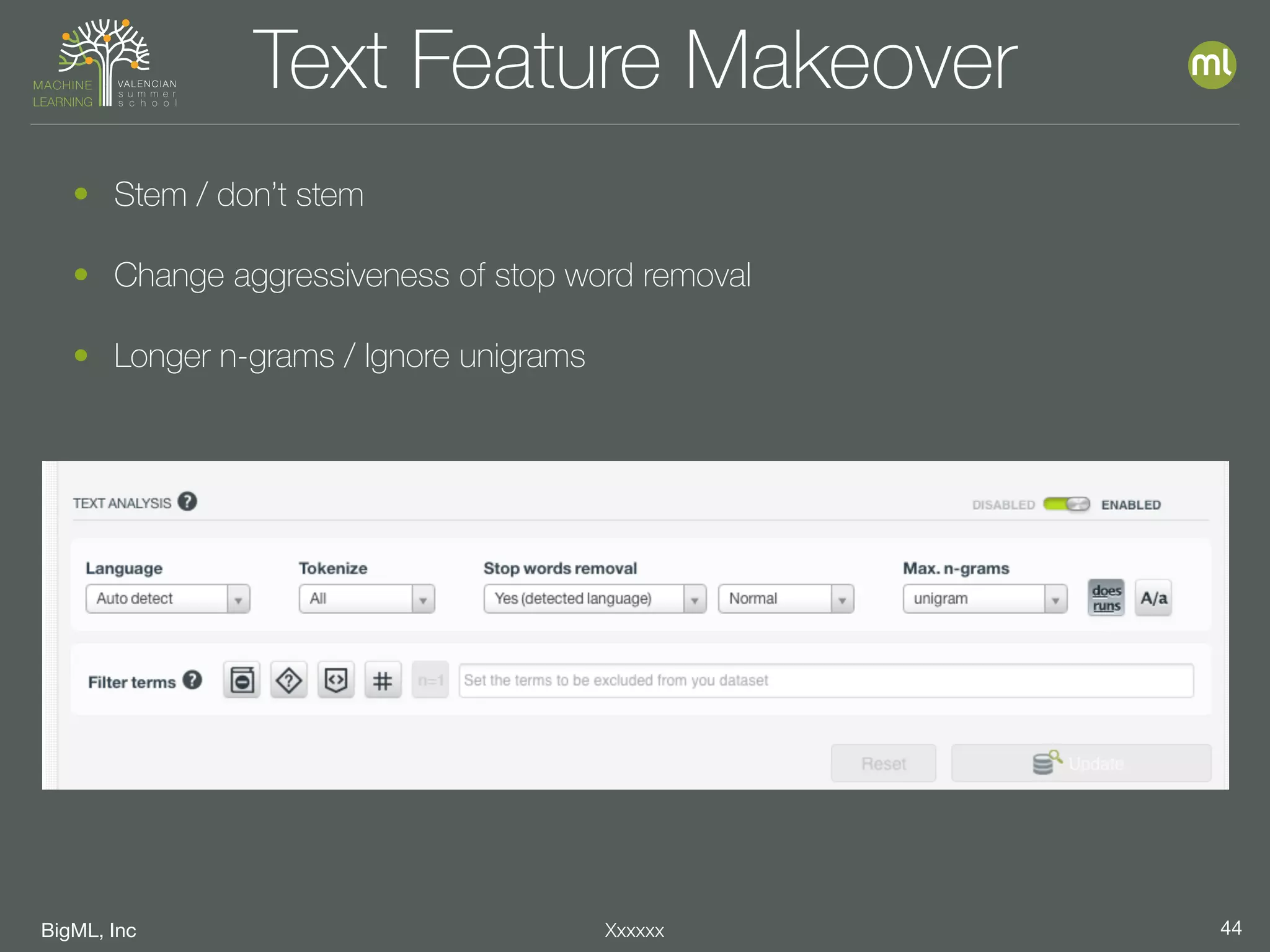


The document discusses parameter optimization and machine learning techniques for tuning models. It covers using machine learning to predict the performance of parameter configurations before training models on them, called Bayesian parameter optimization. It also discusses dangers of naive cross-validation and how to select the best model by considering factors beyond just performance like retraining needs and prediction speed. The document advocates creating diverse ensembles through techniques like fusions to improve stability and importance profiles.



















































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


