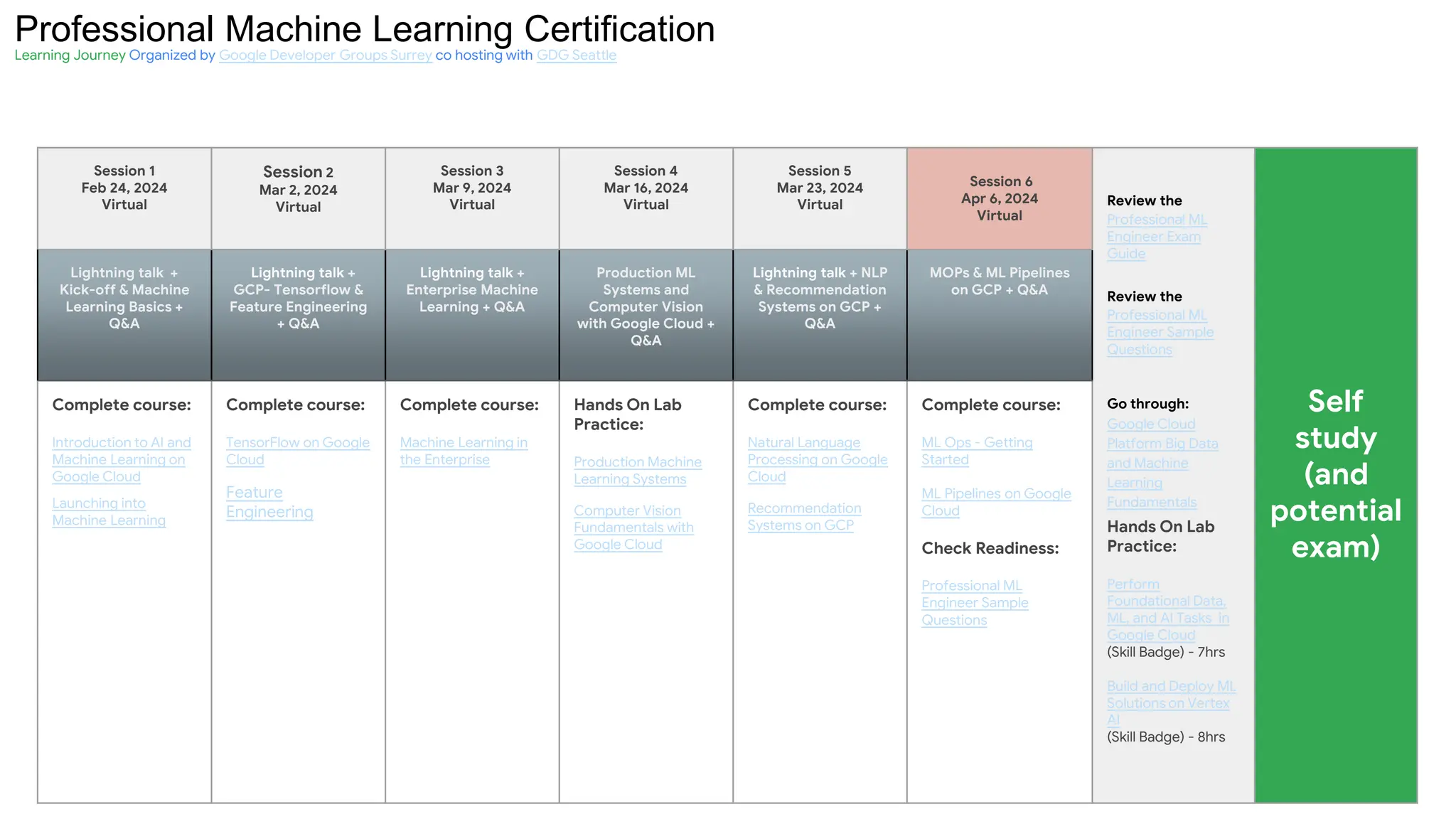
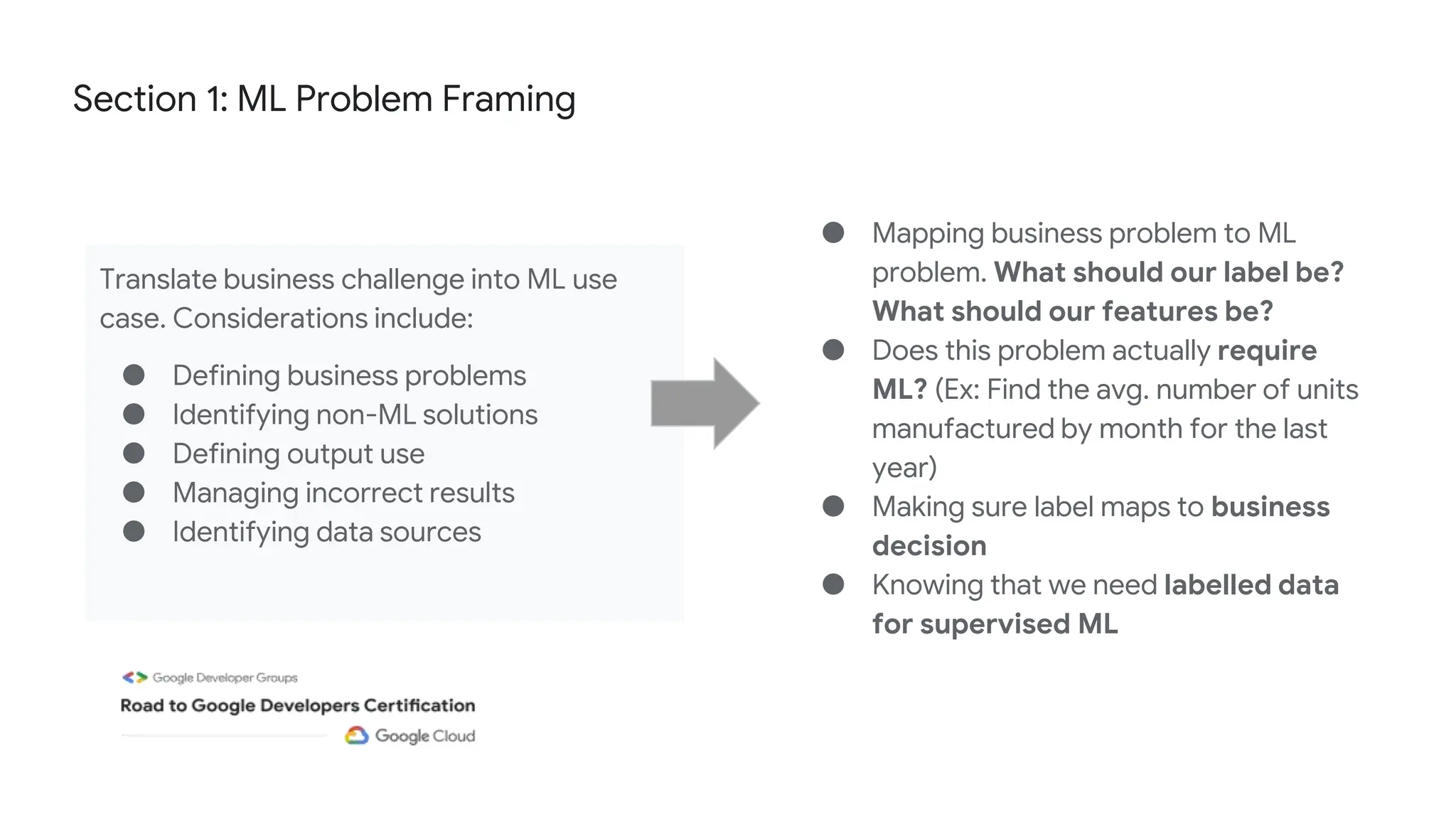
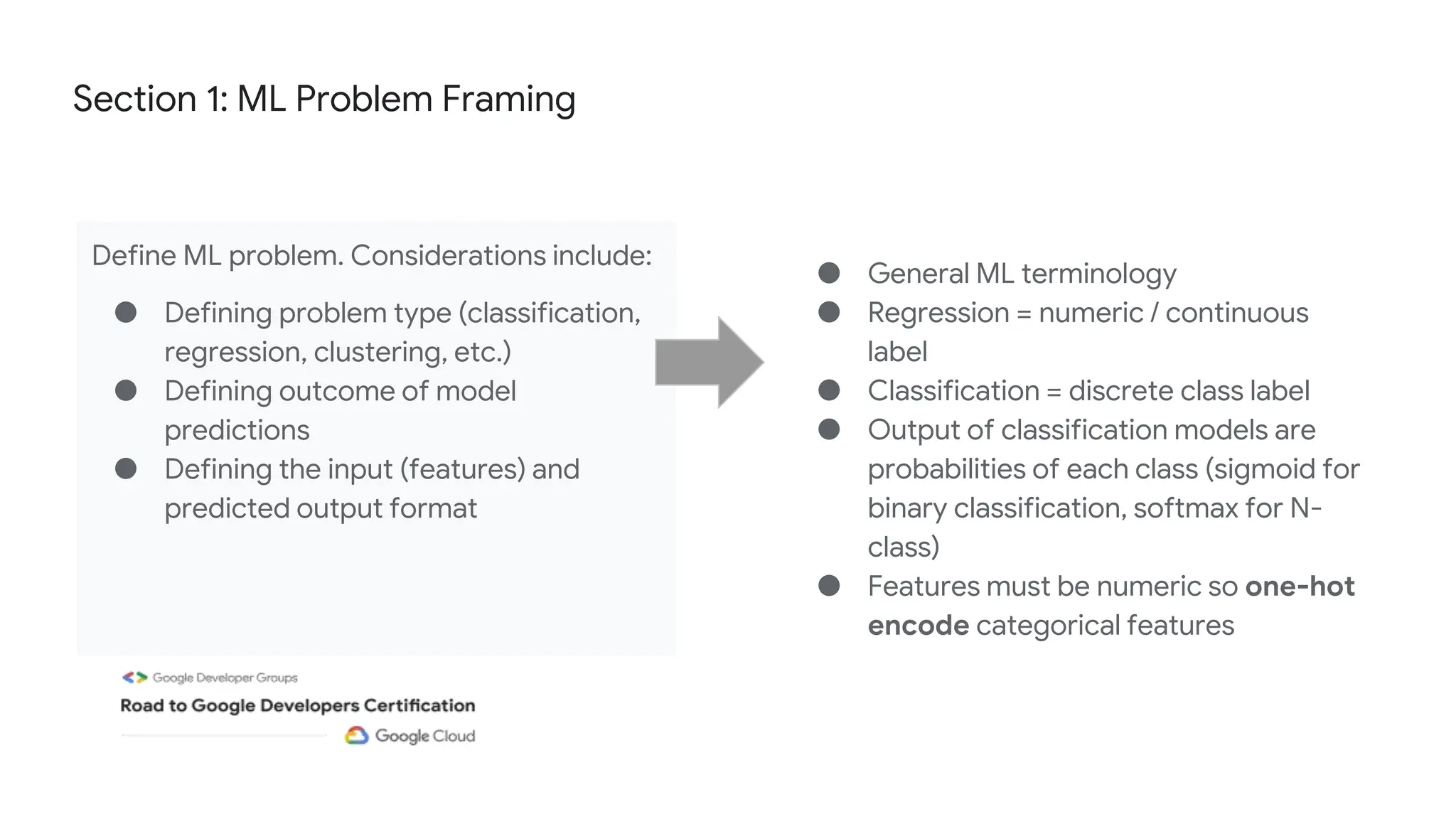
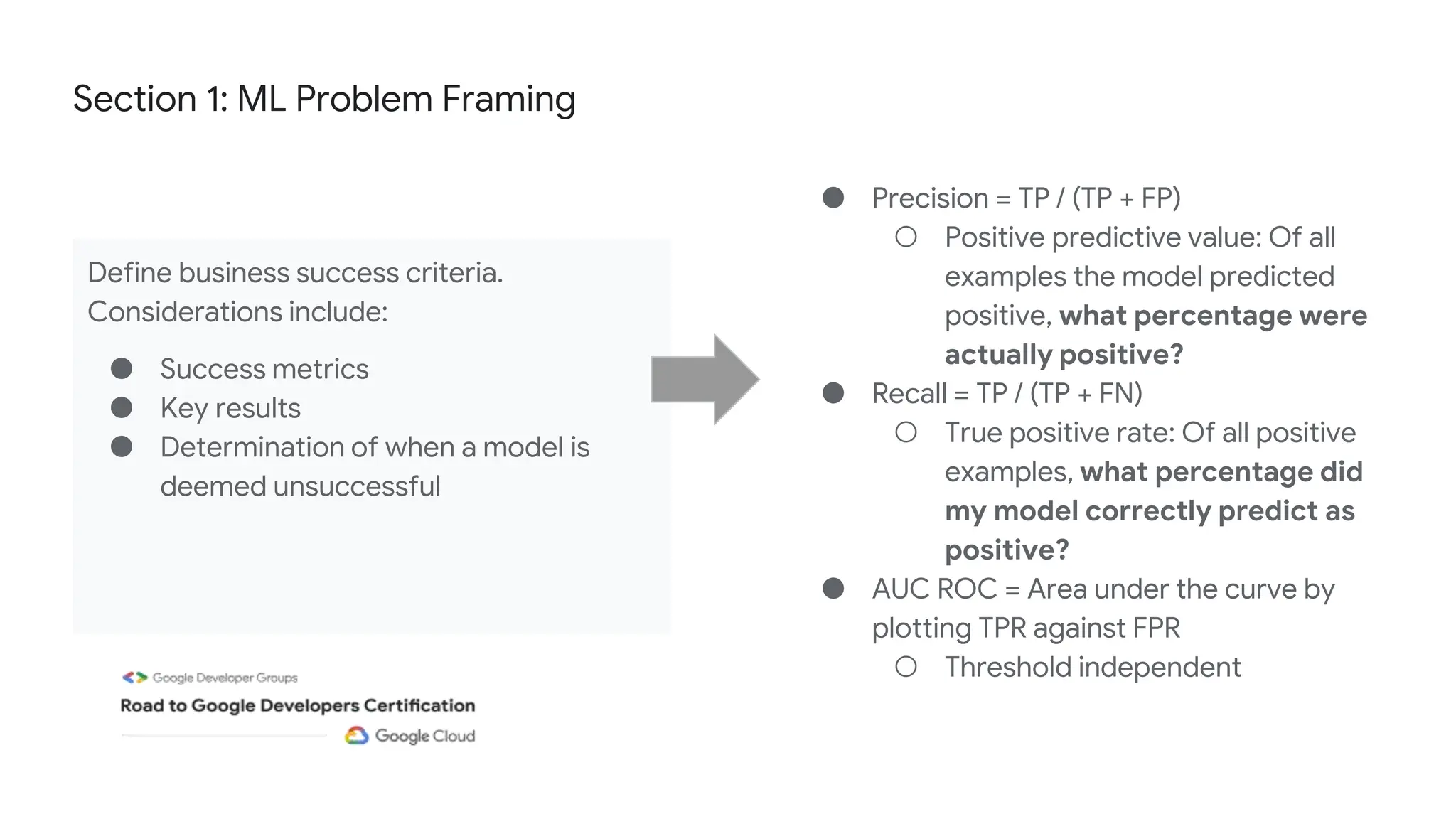
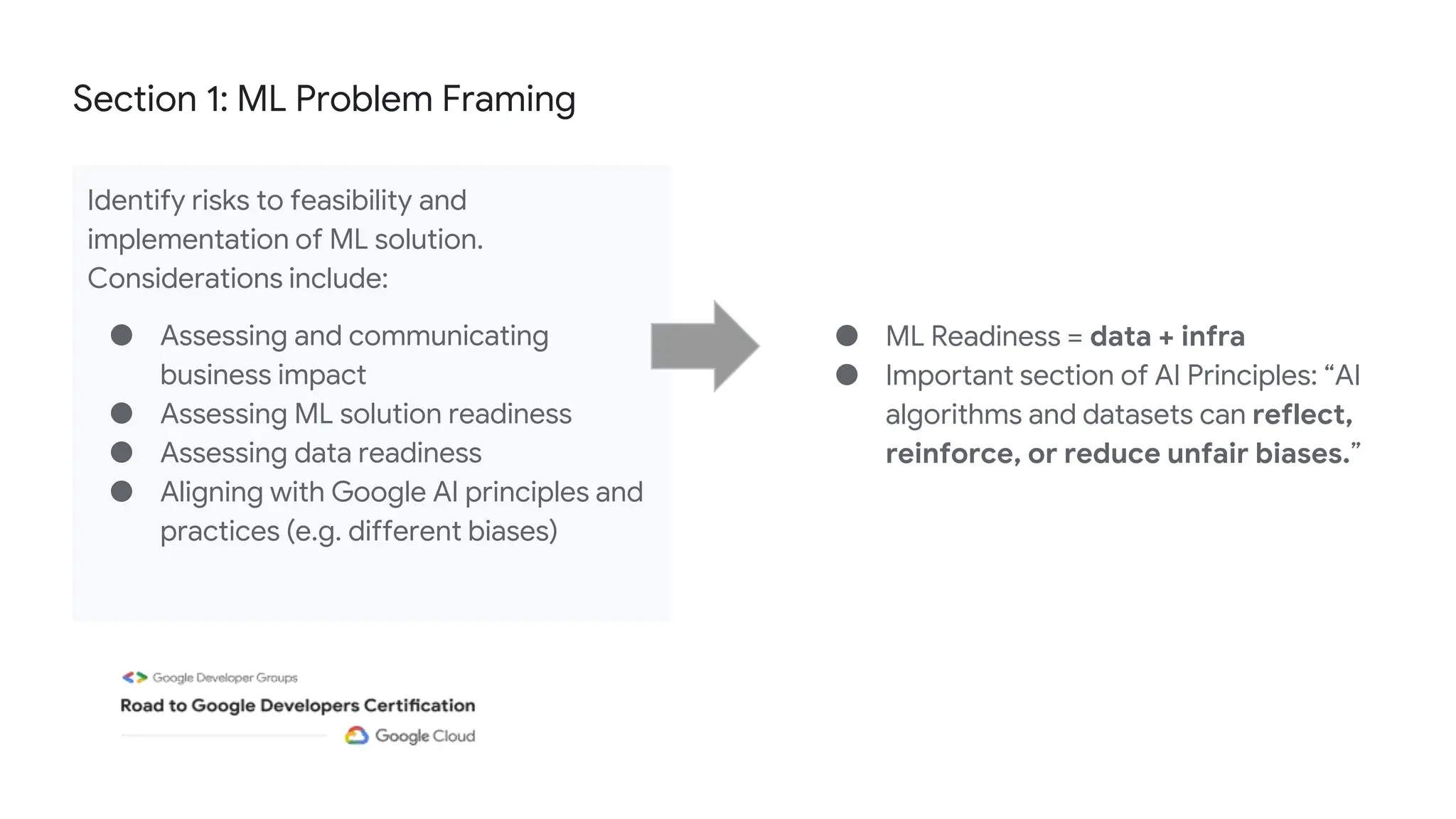
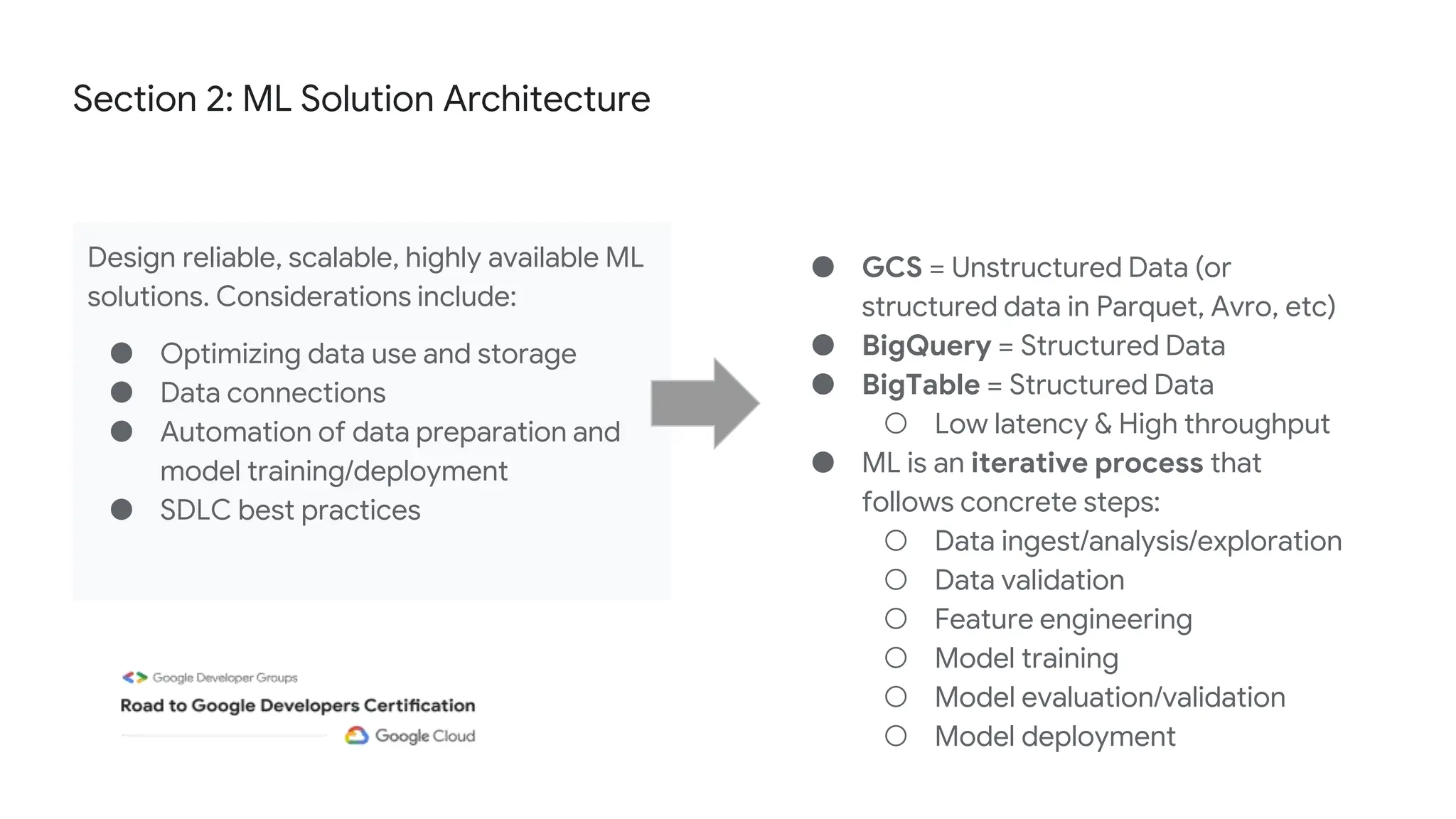
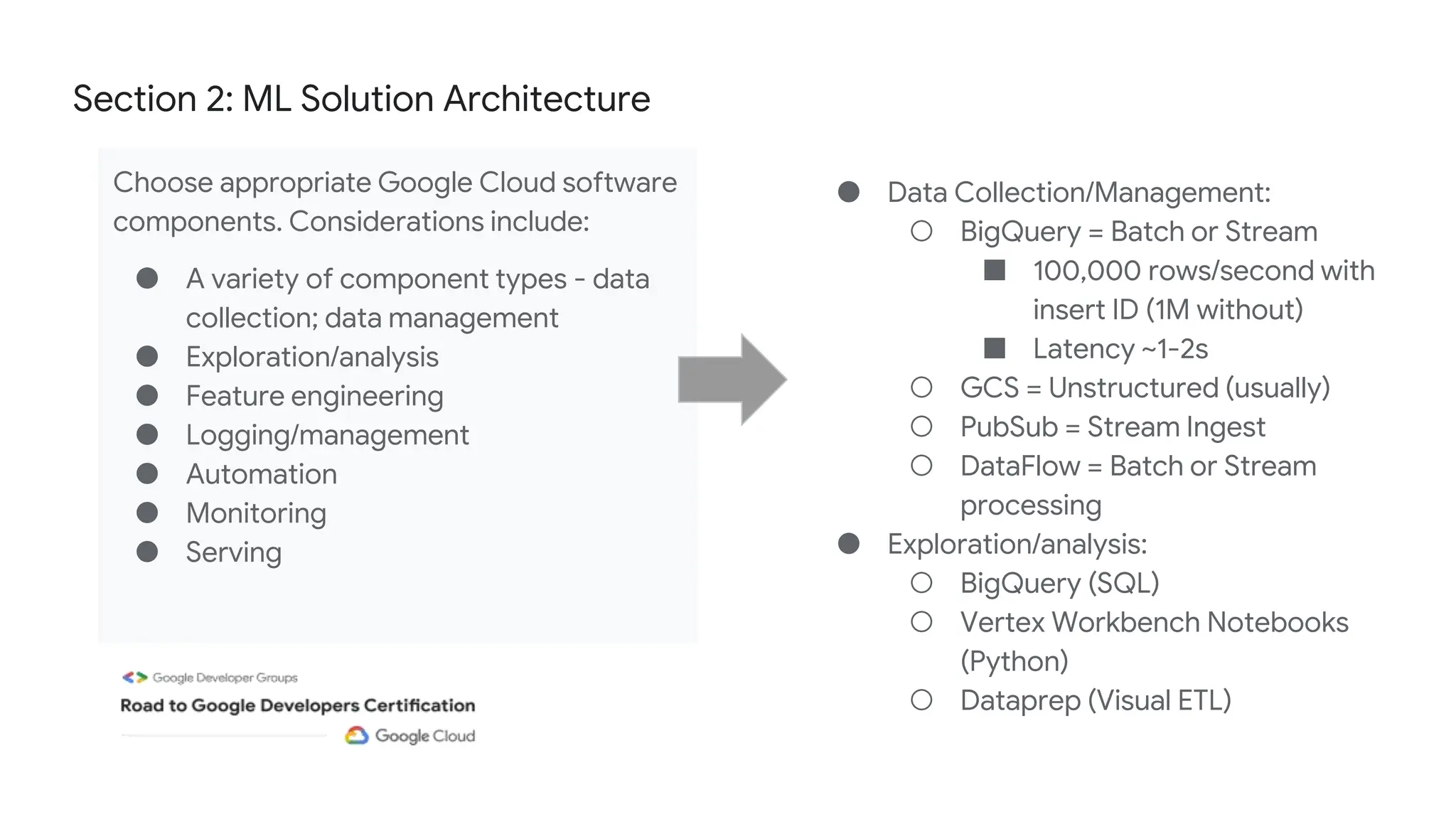
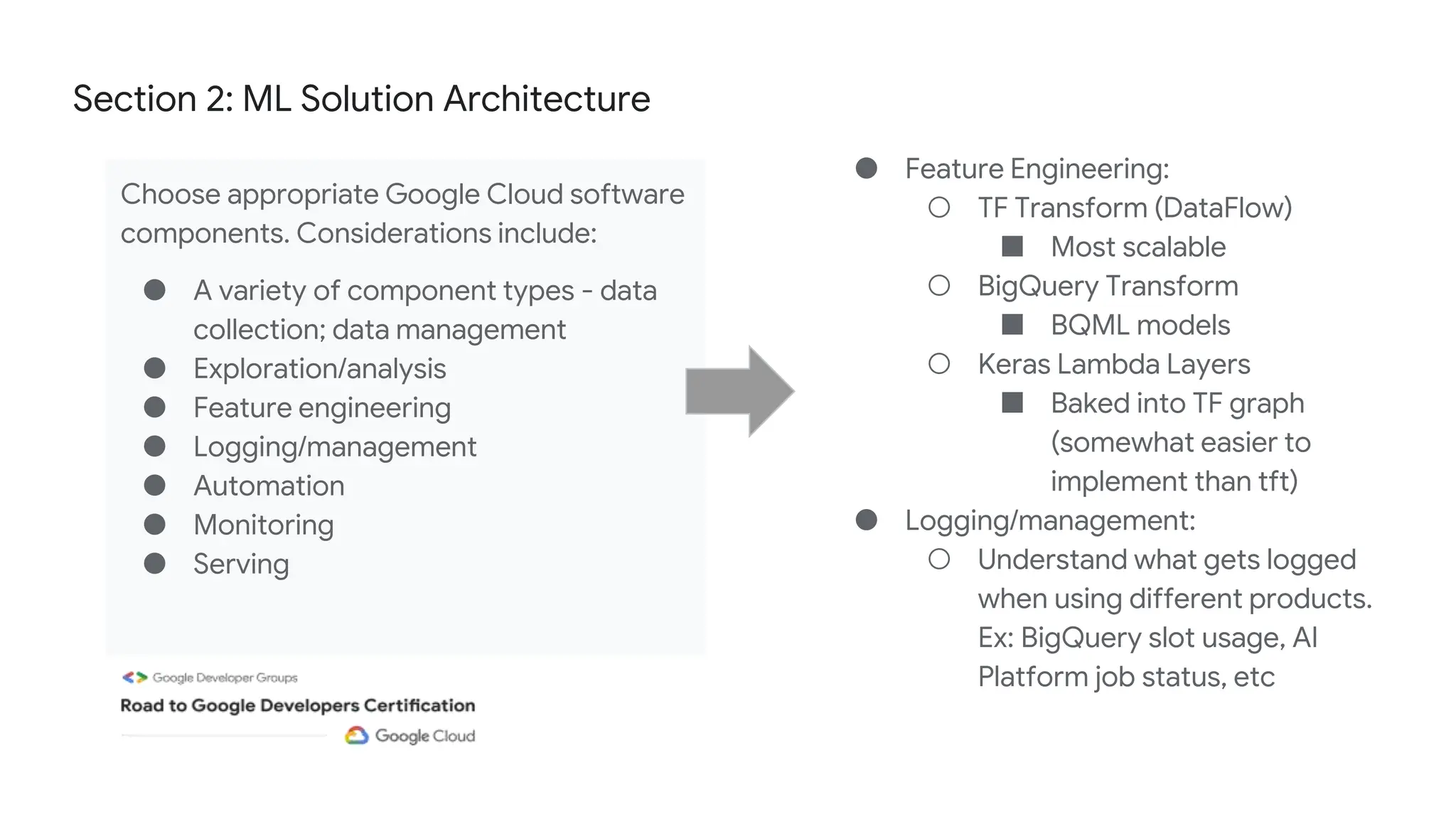
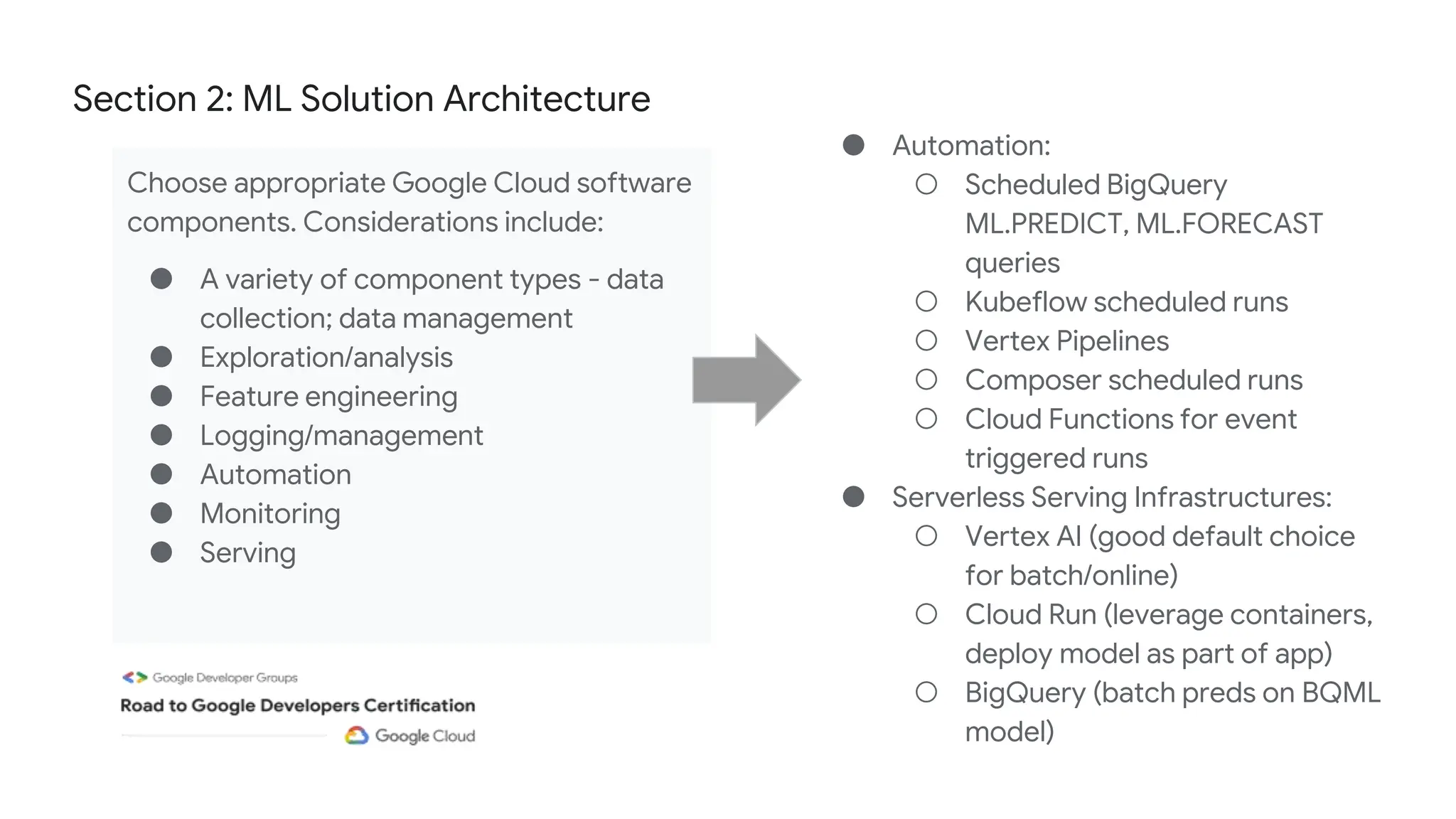
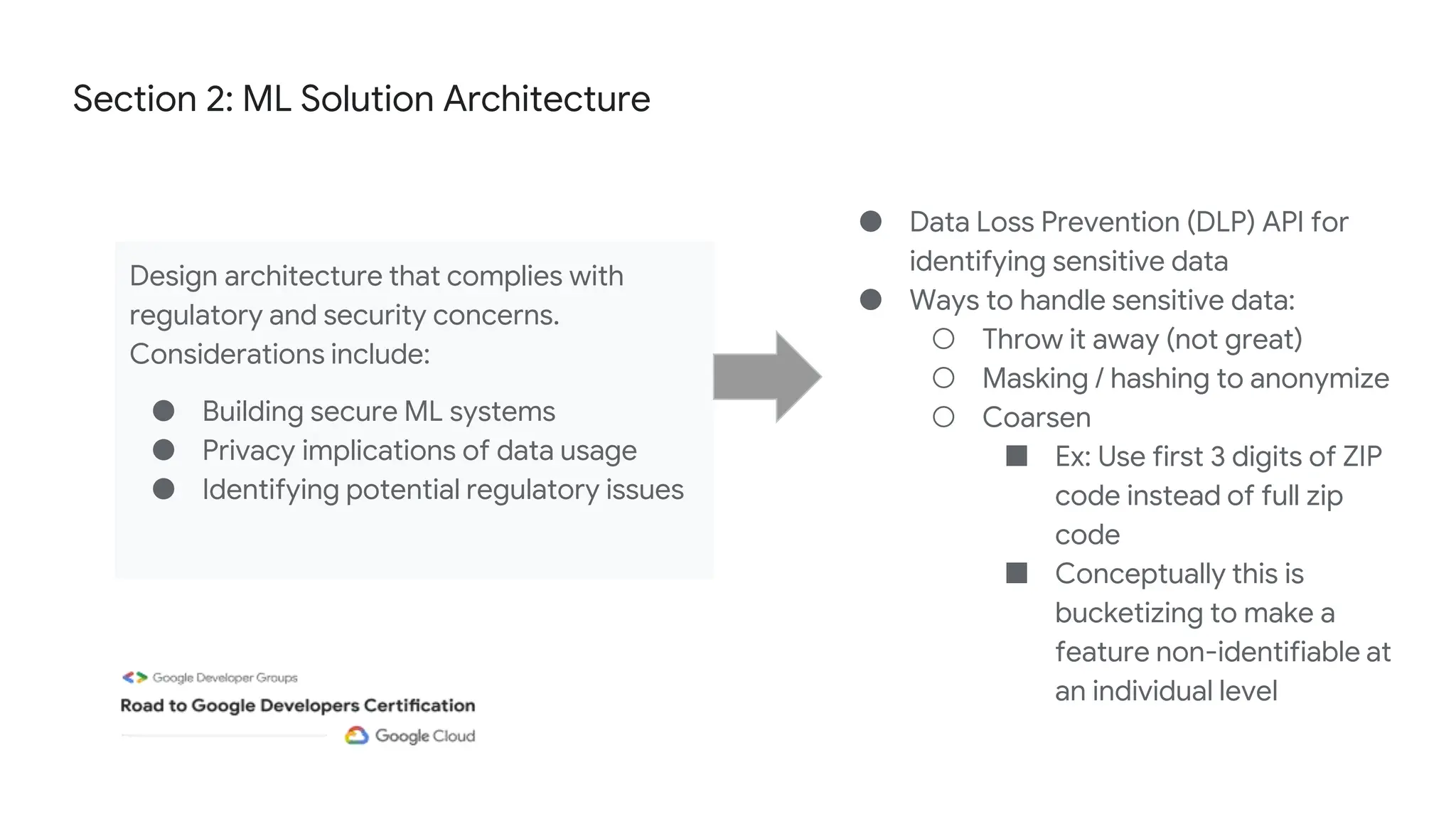
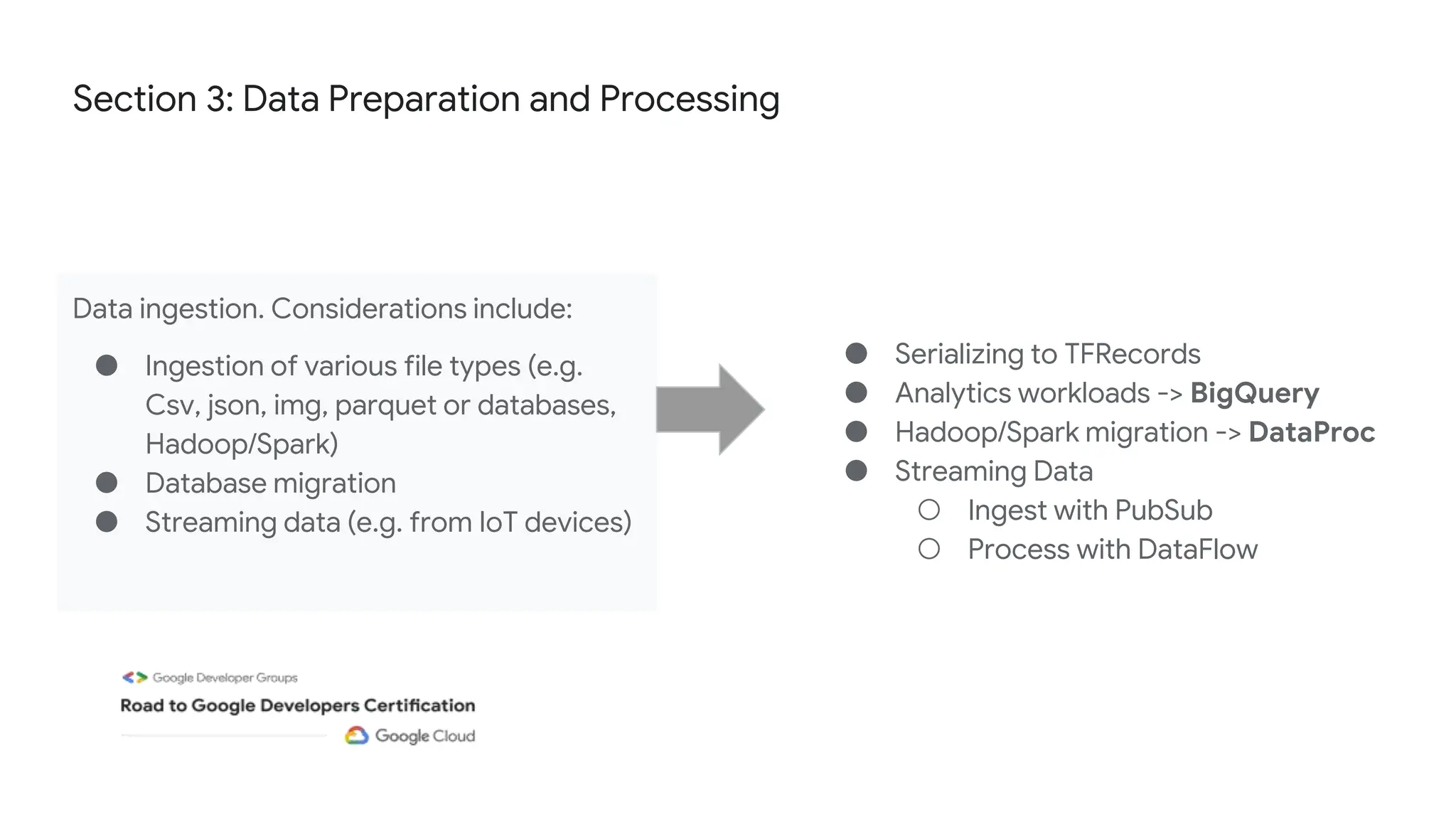
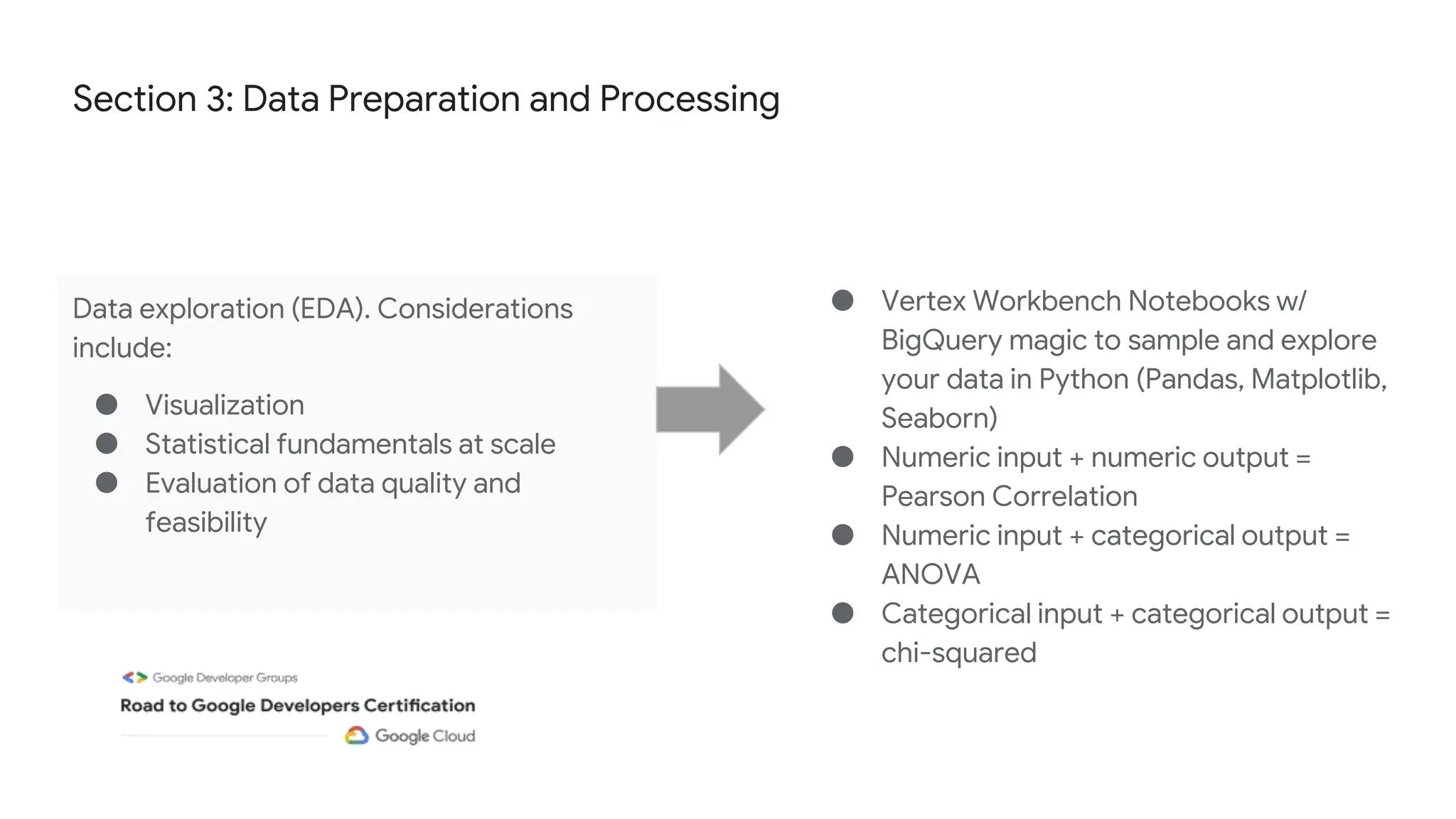
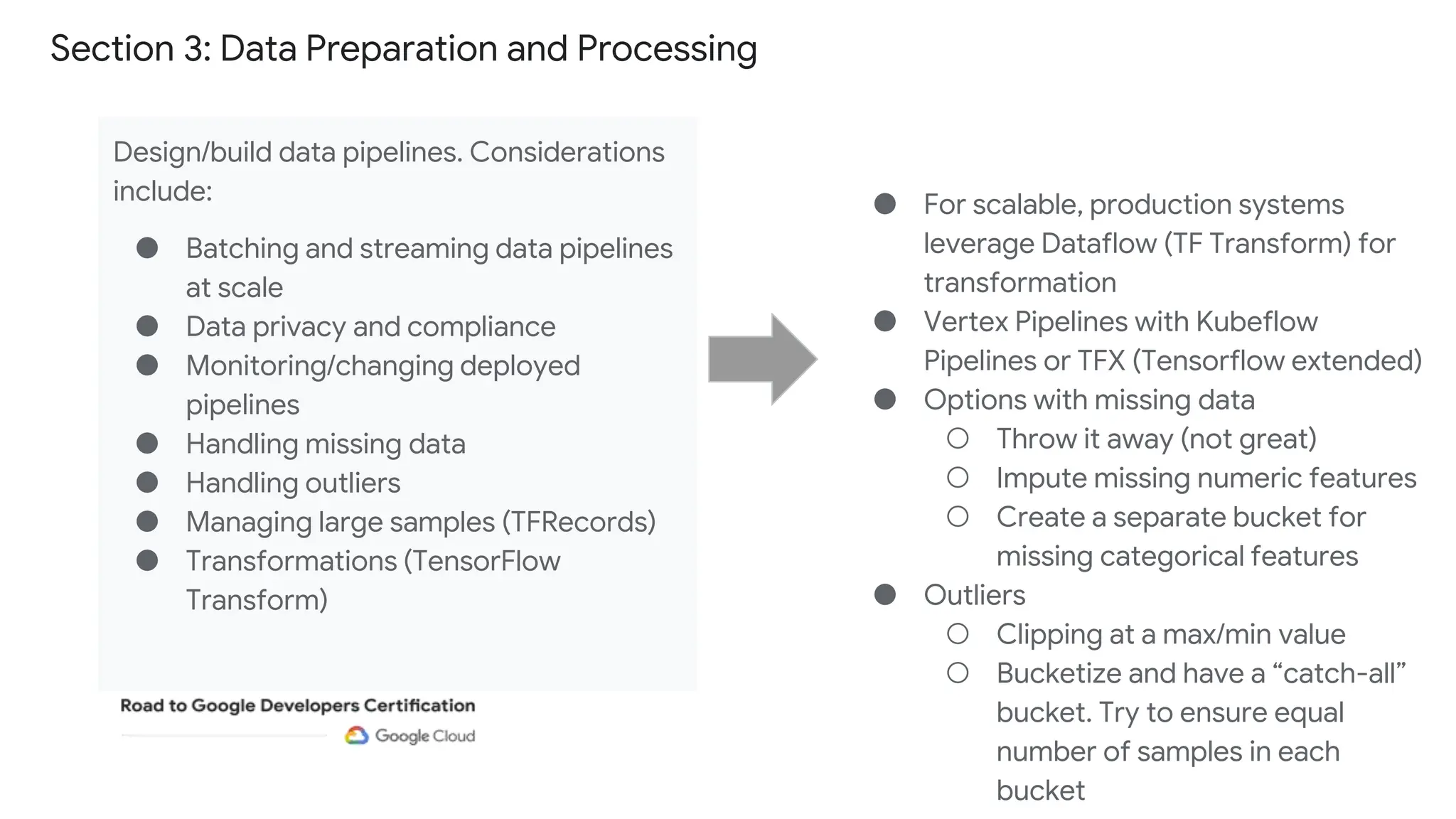
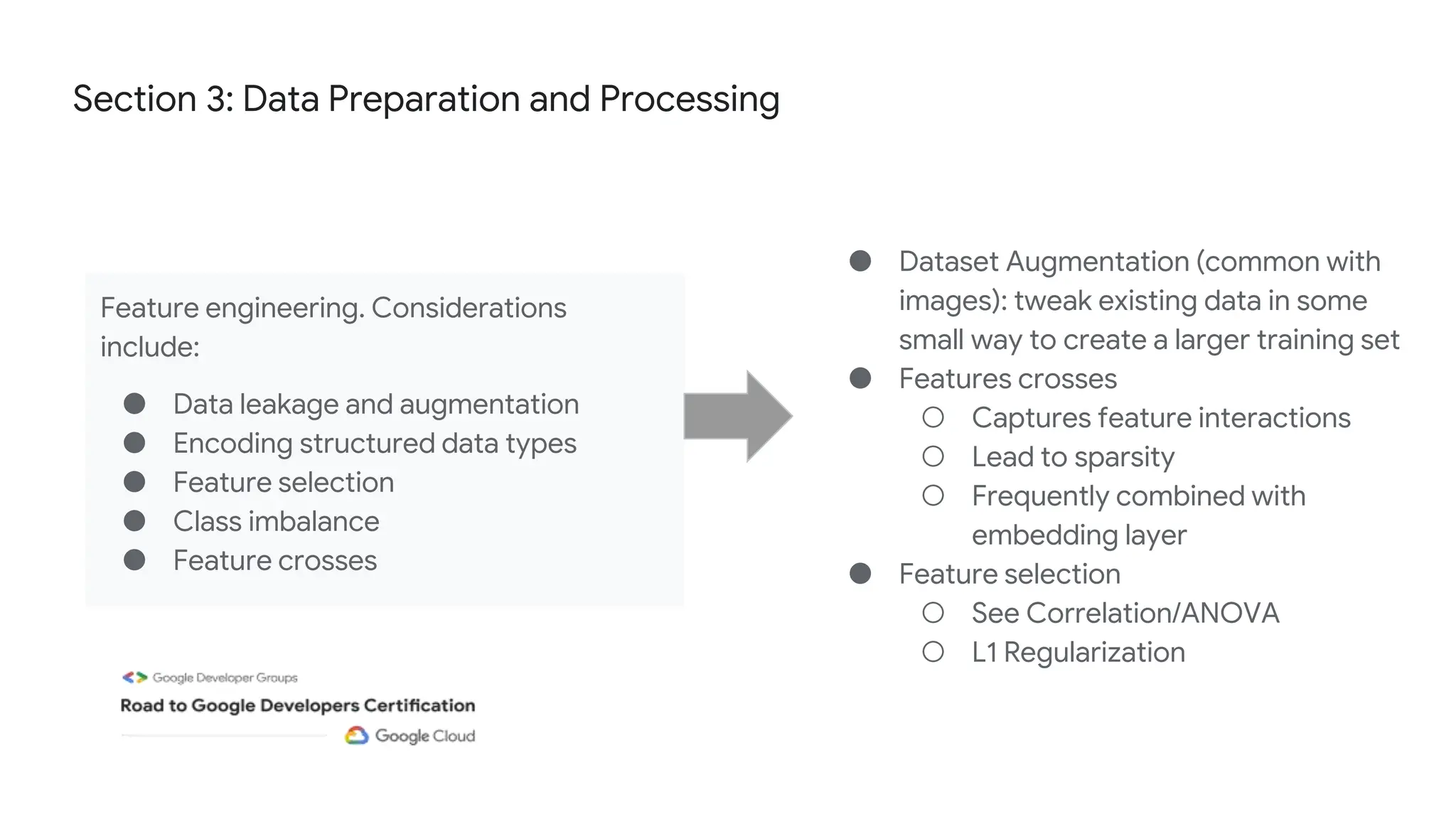
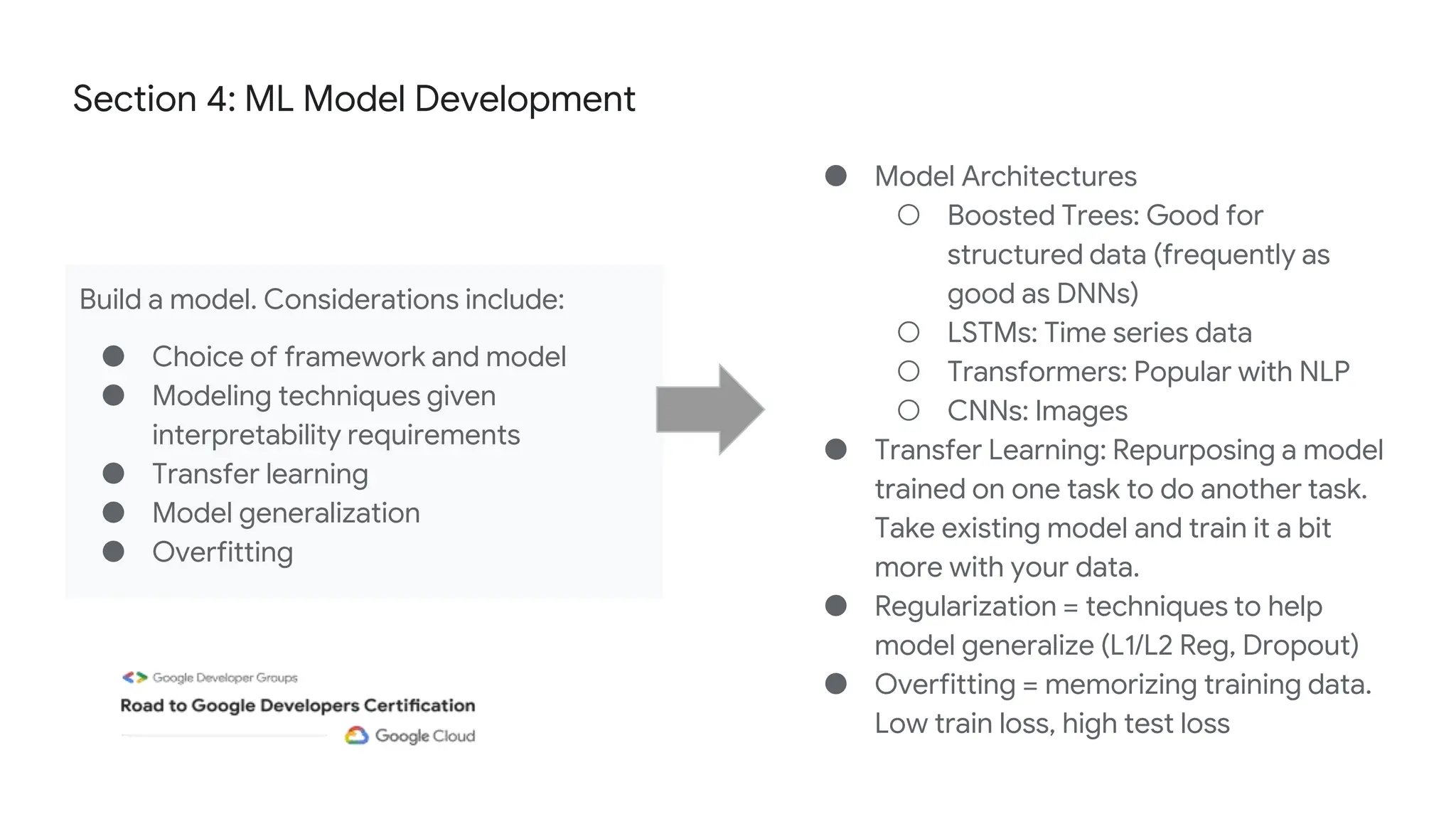
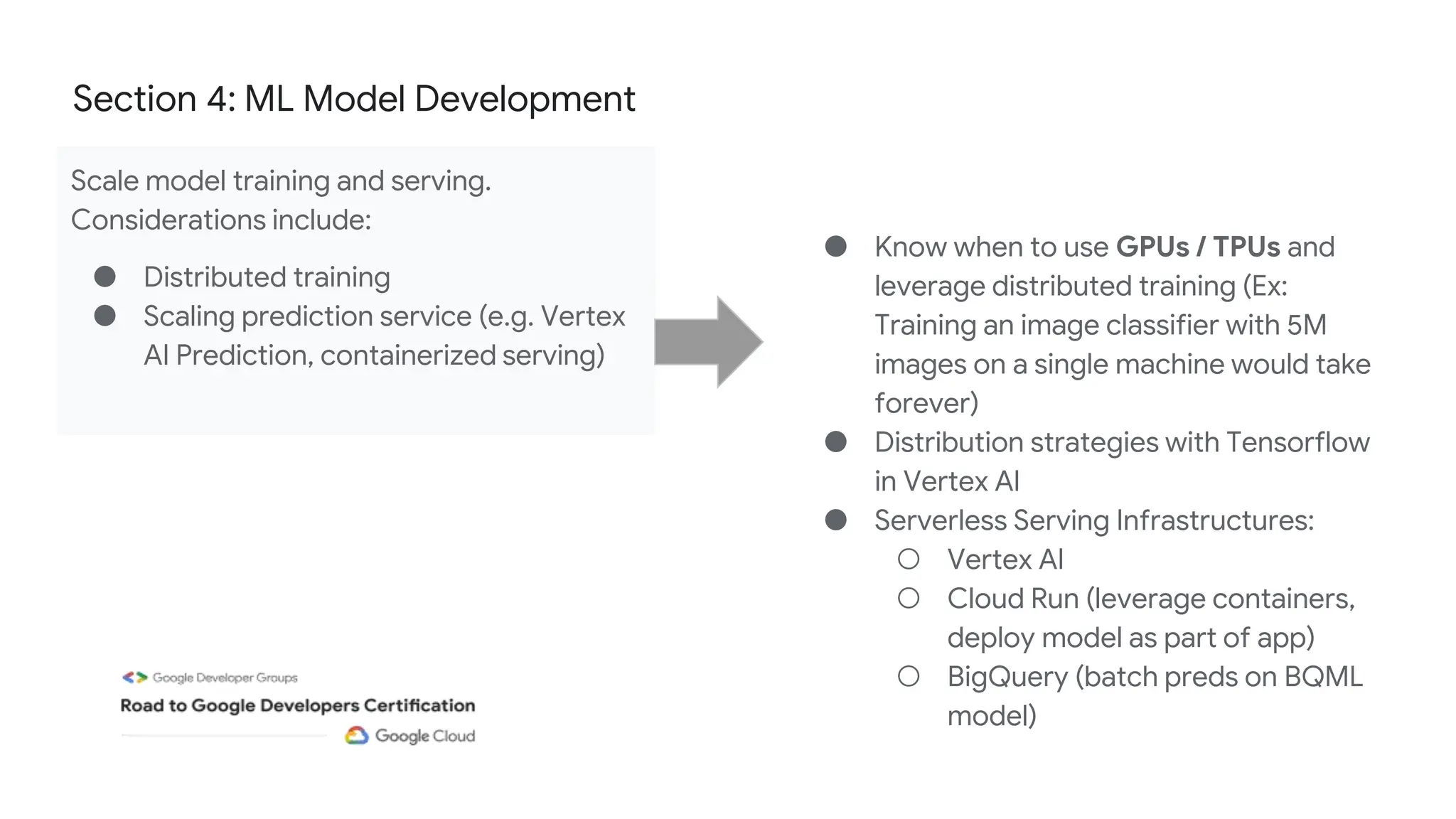
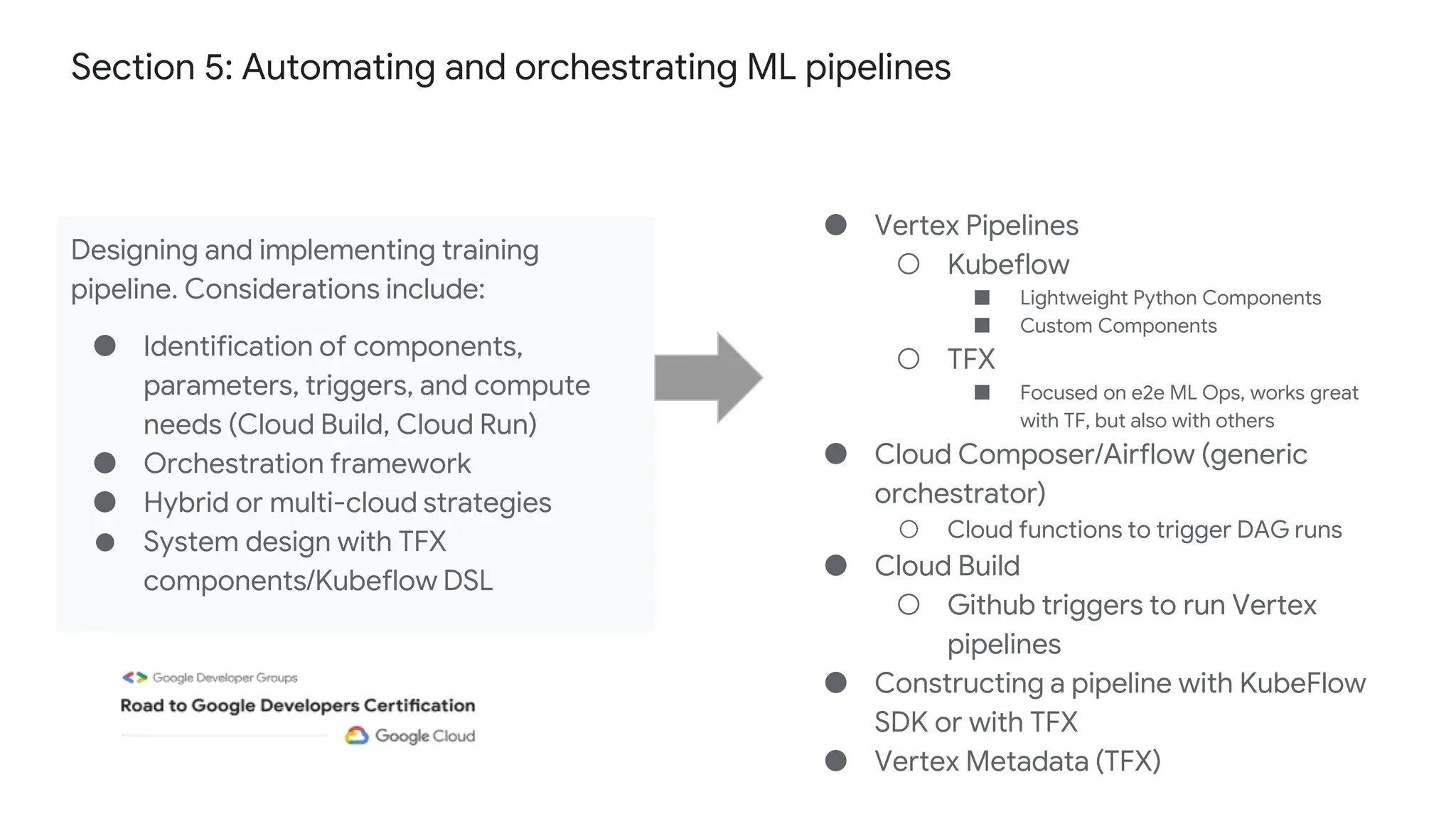
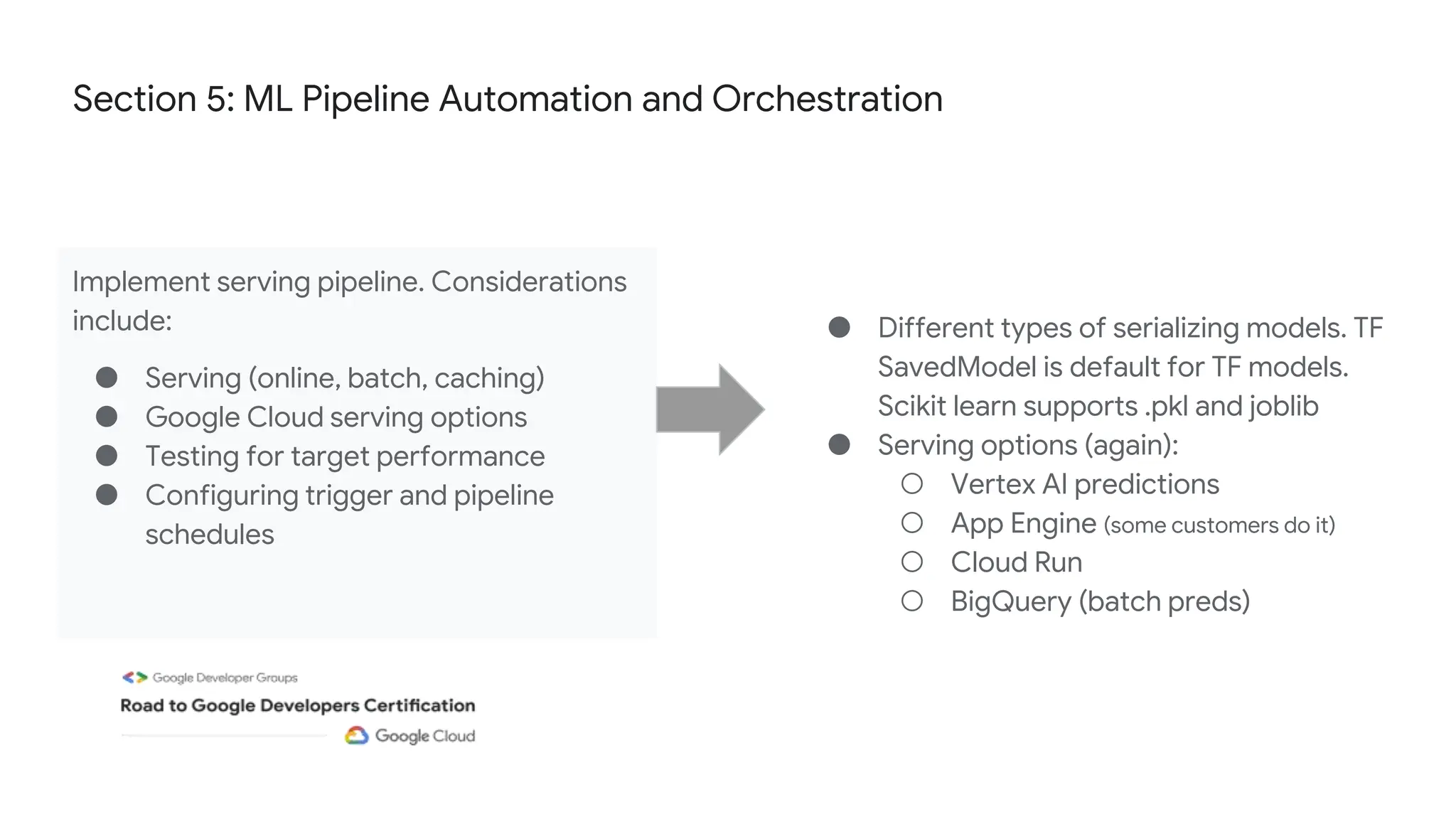
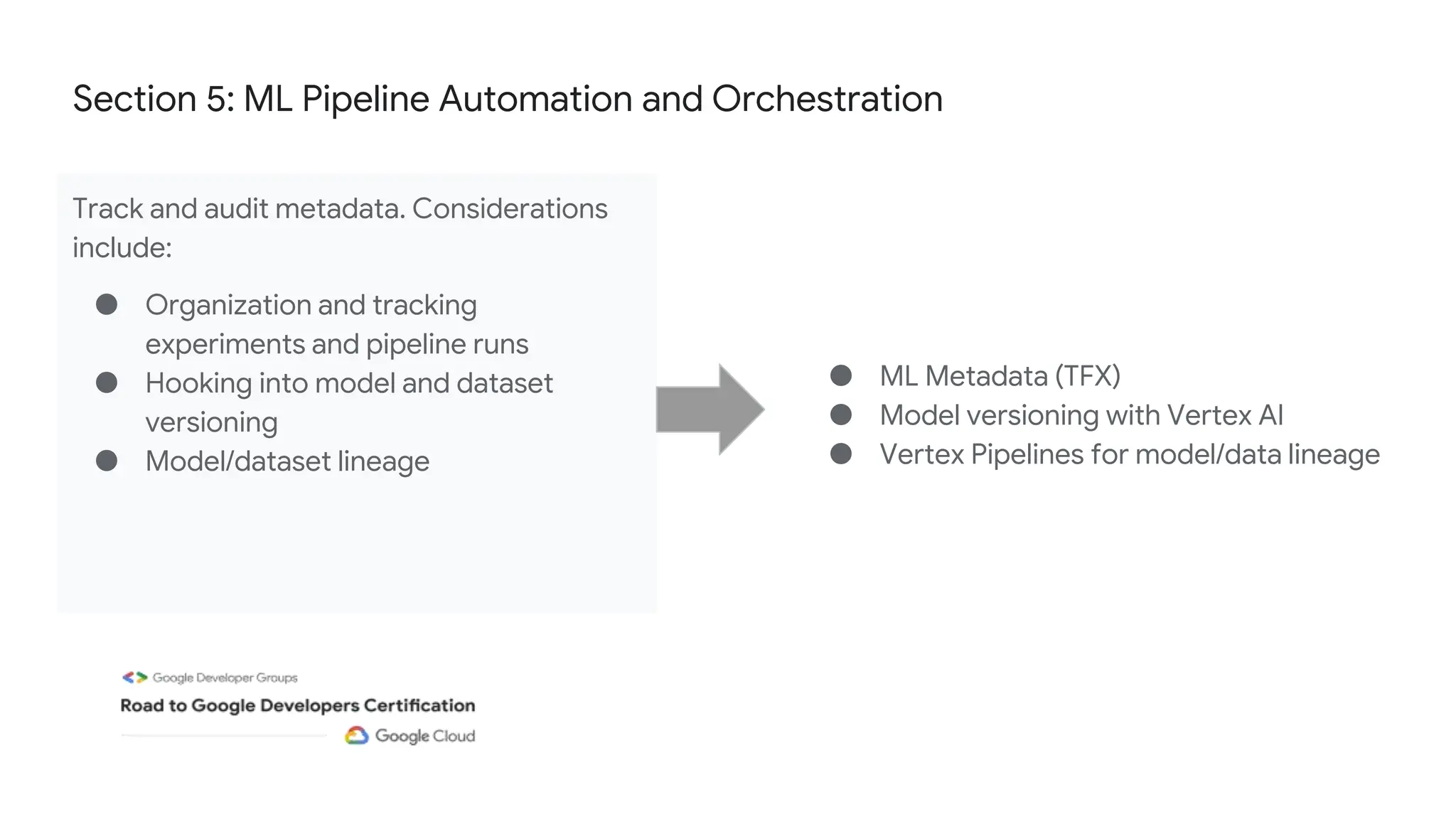
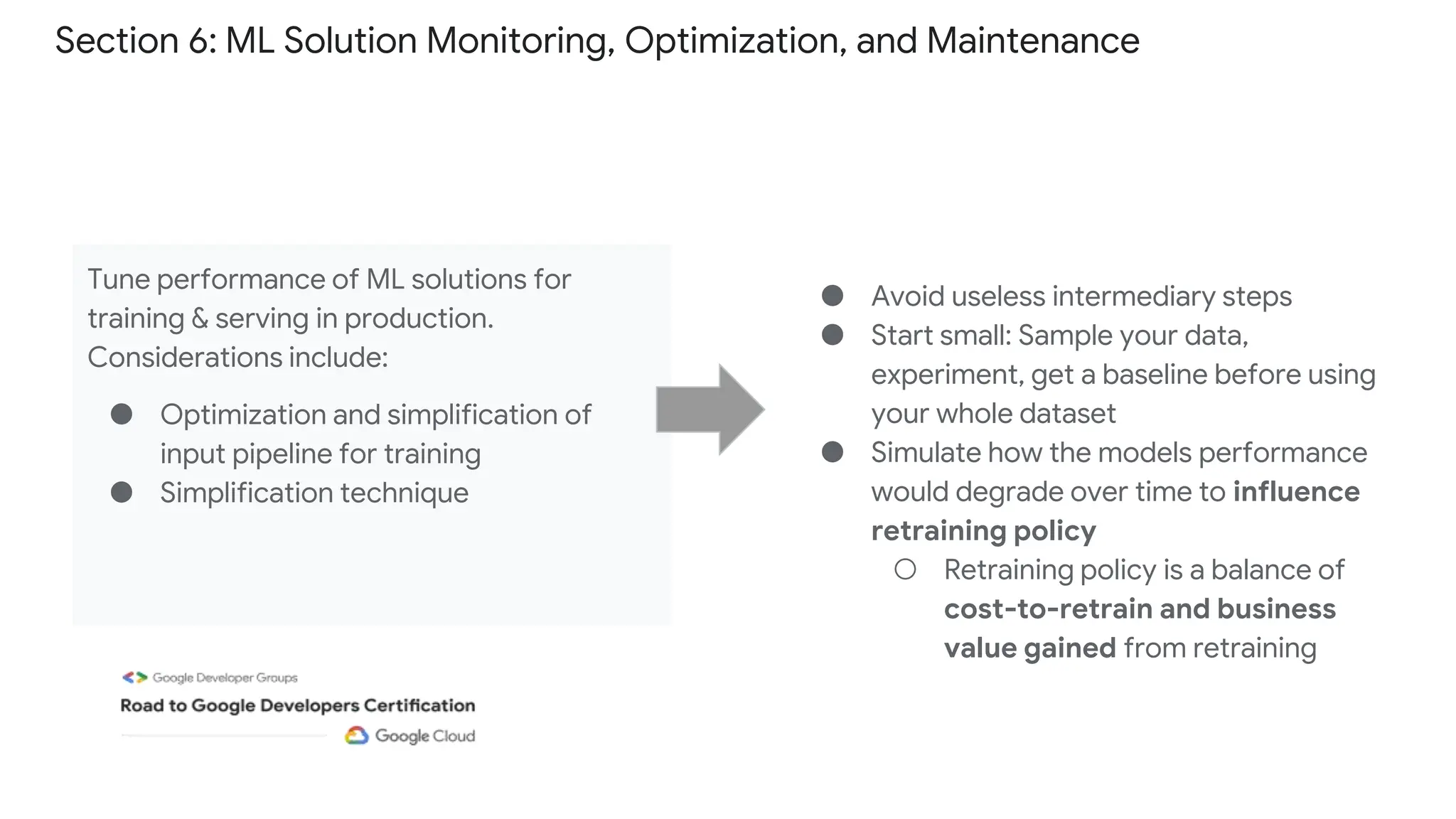
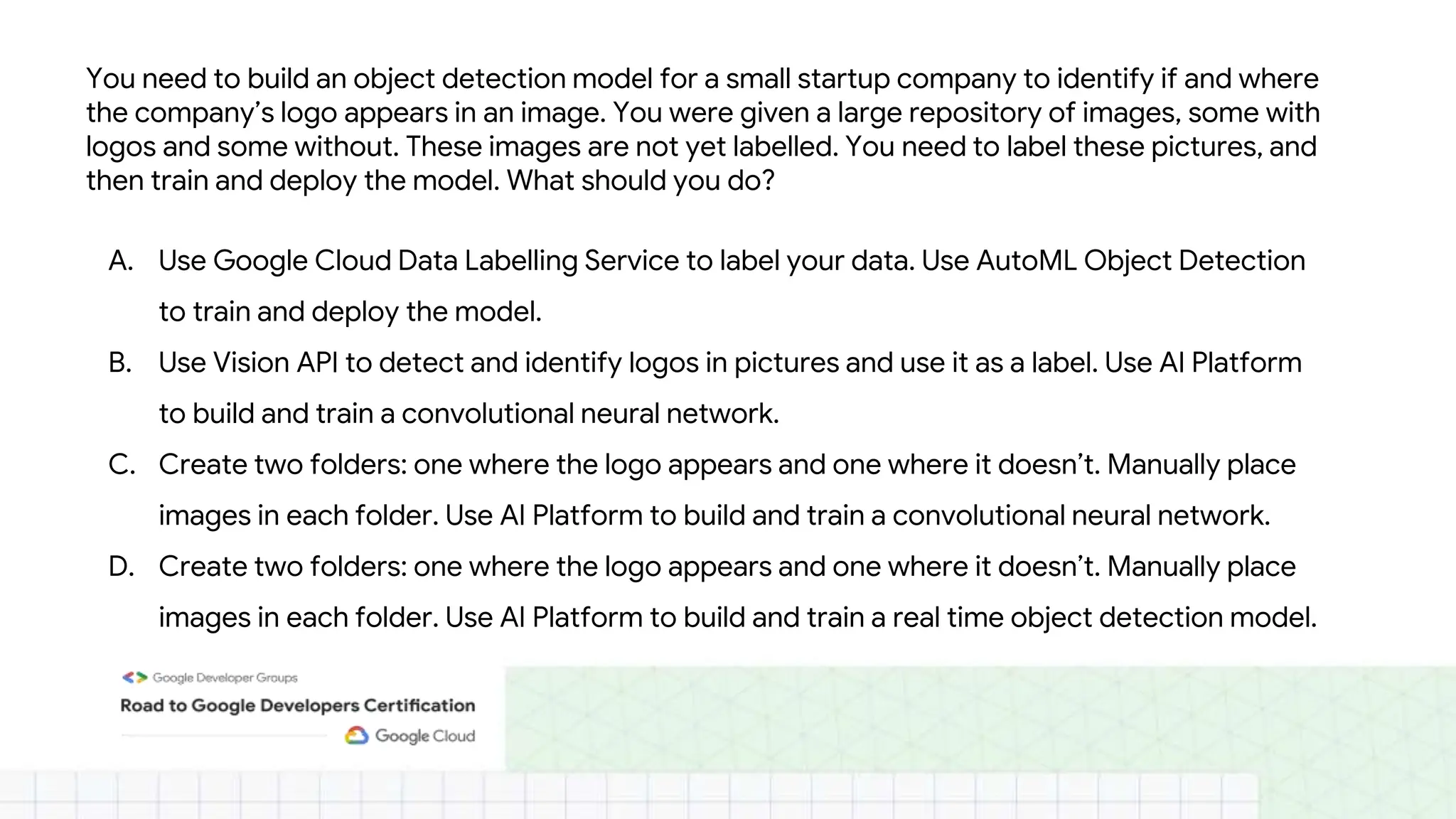
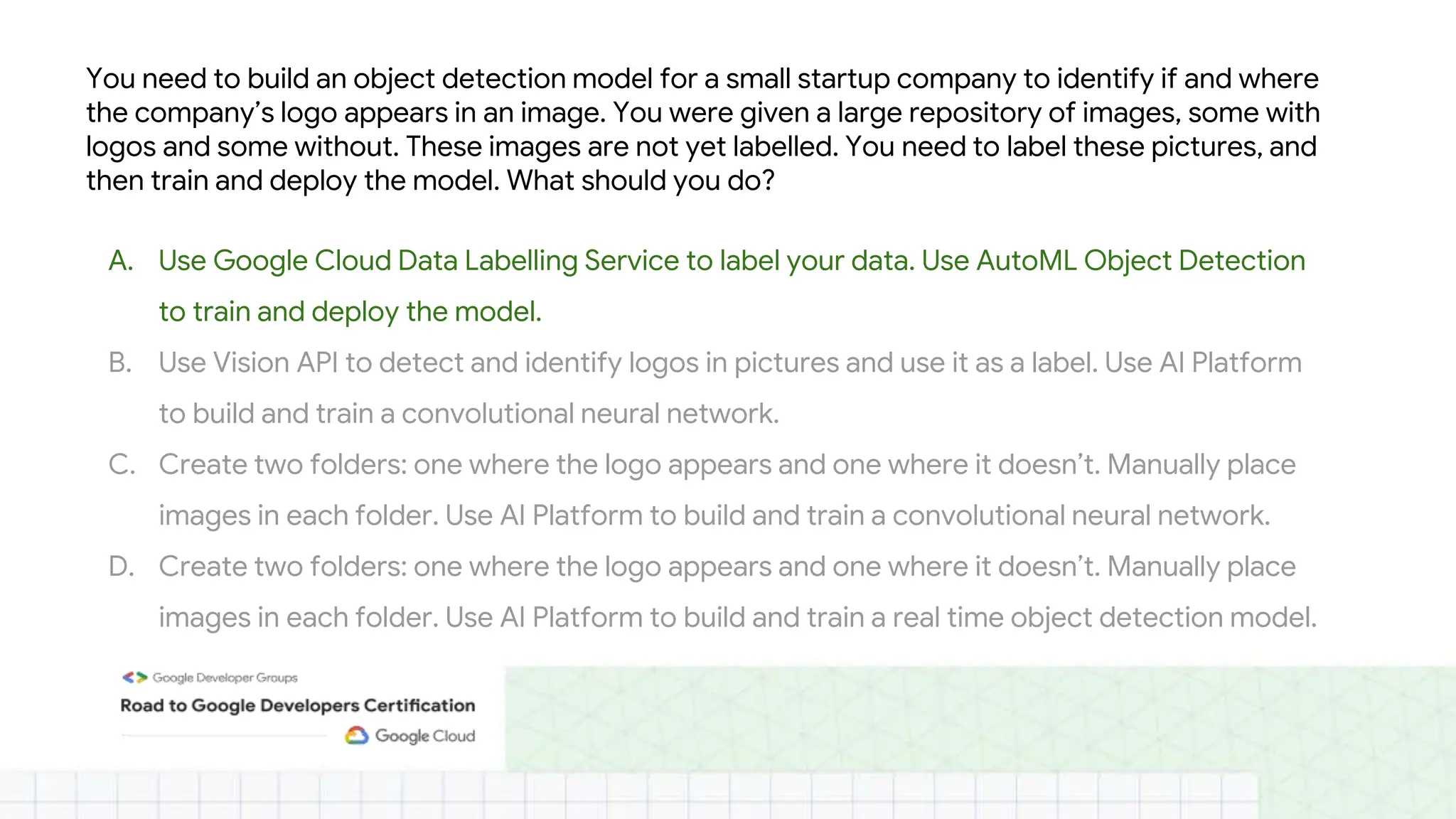
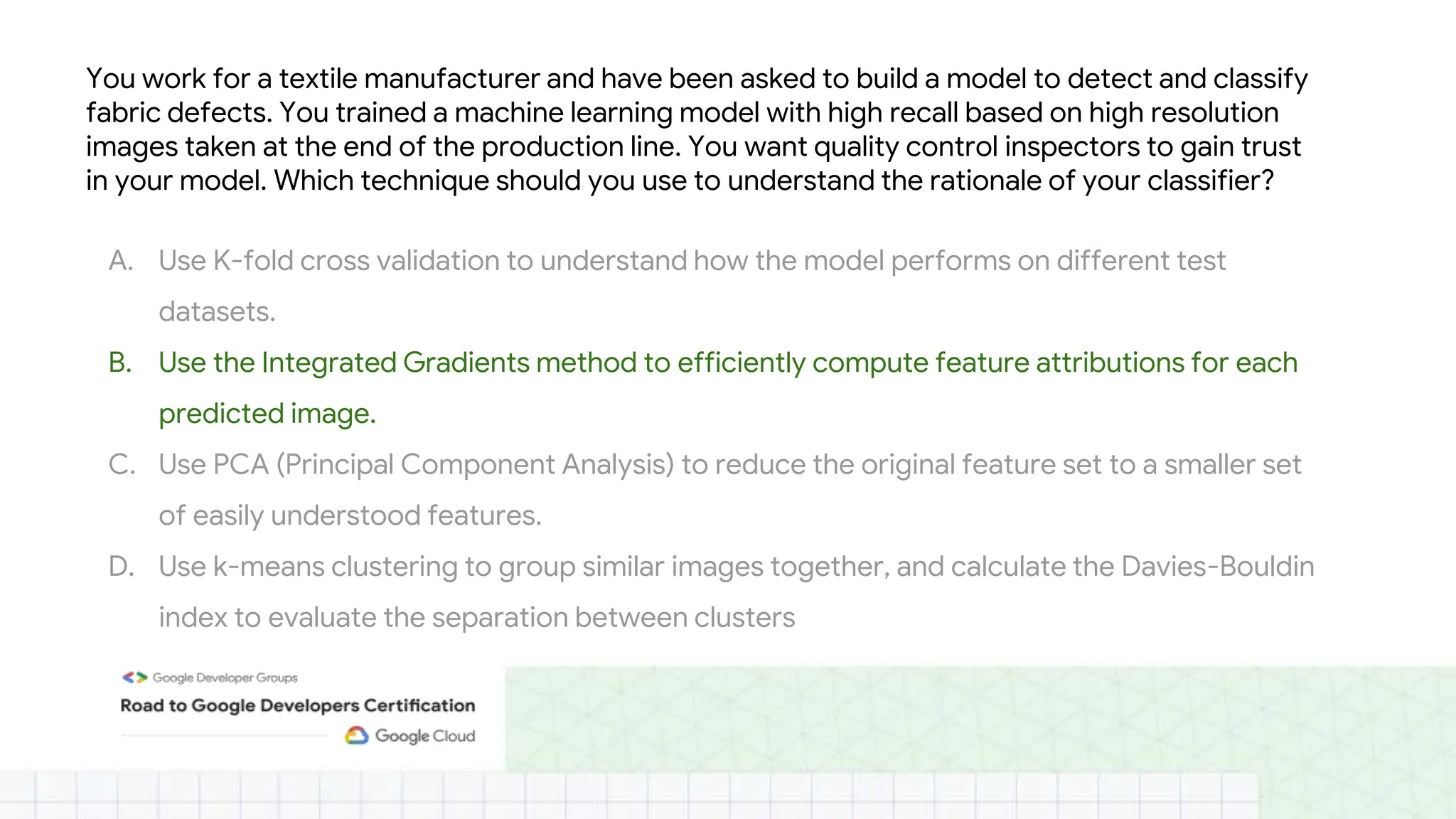
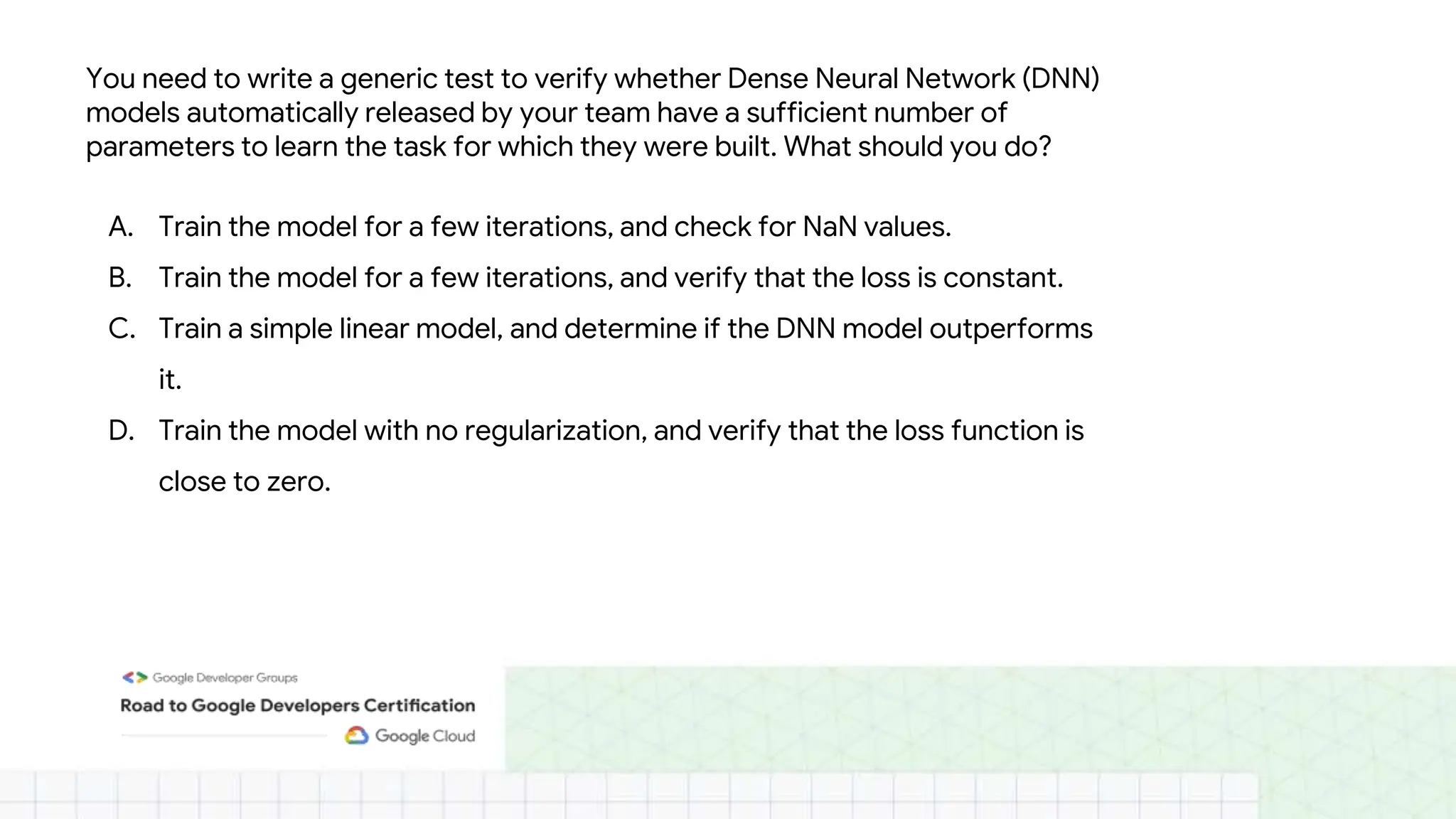
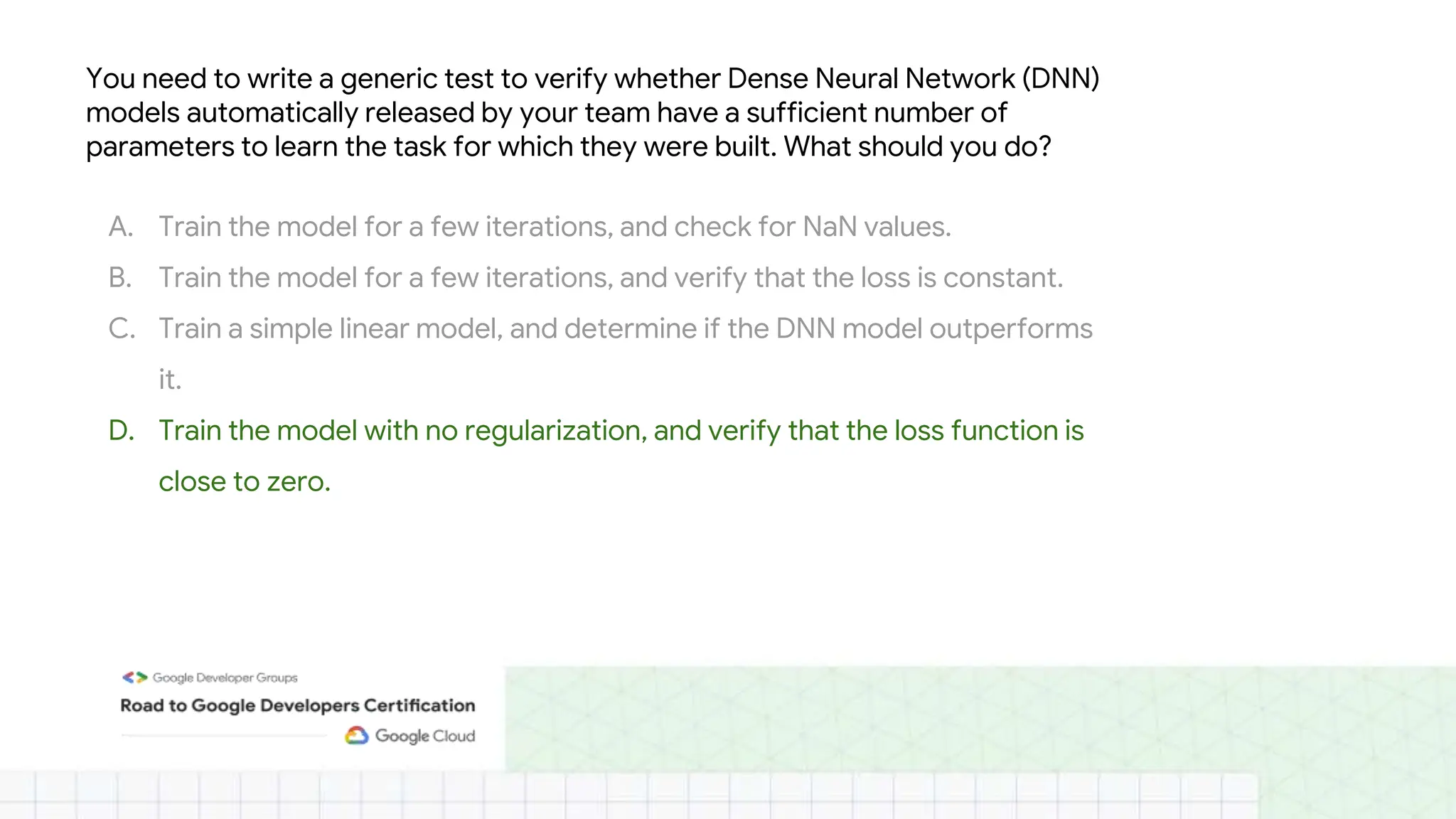
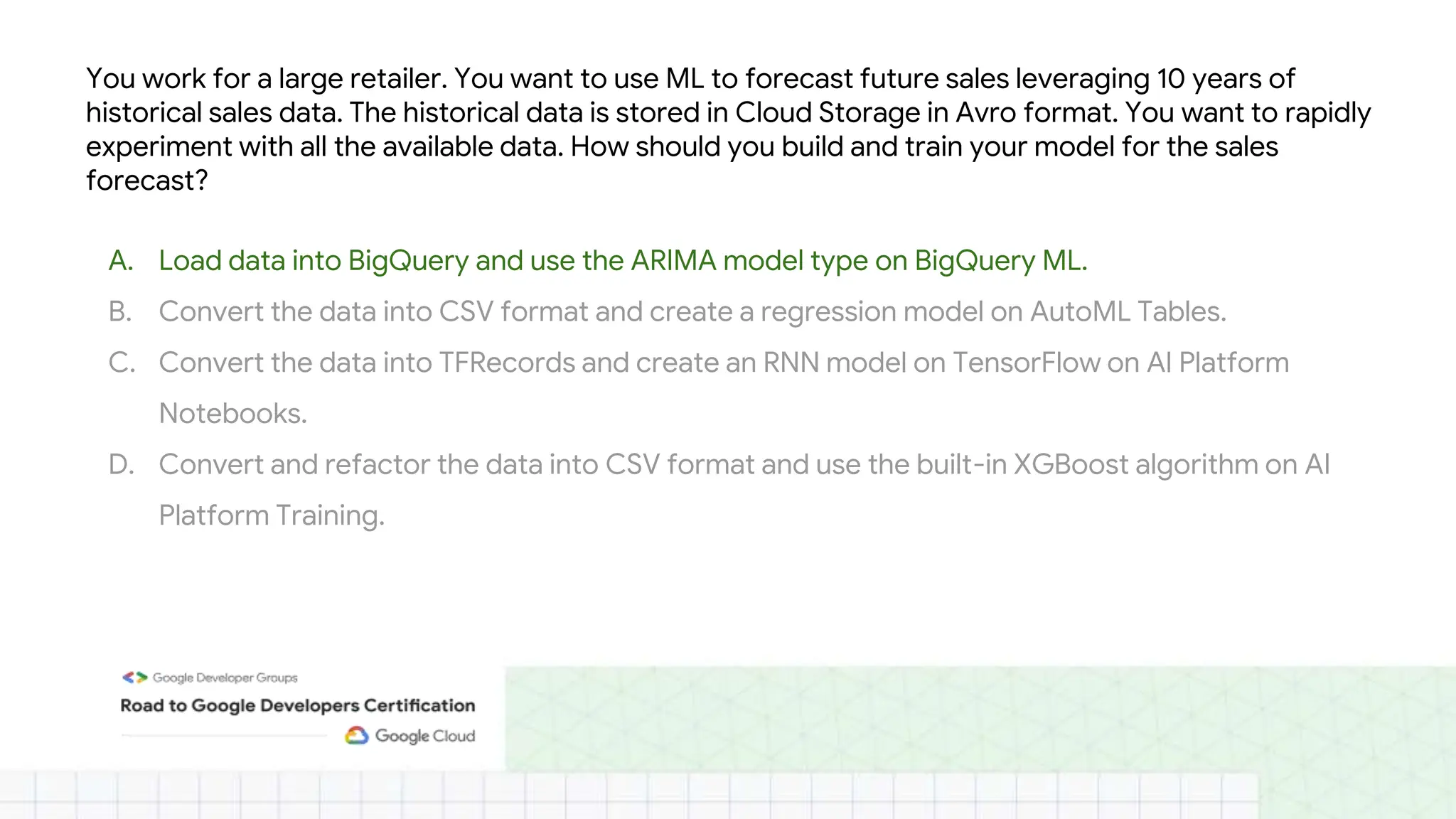
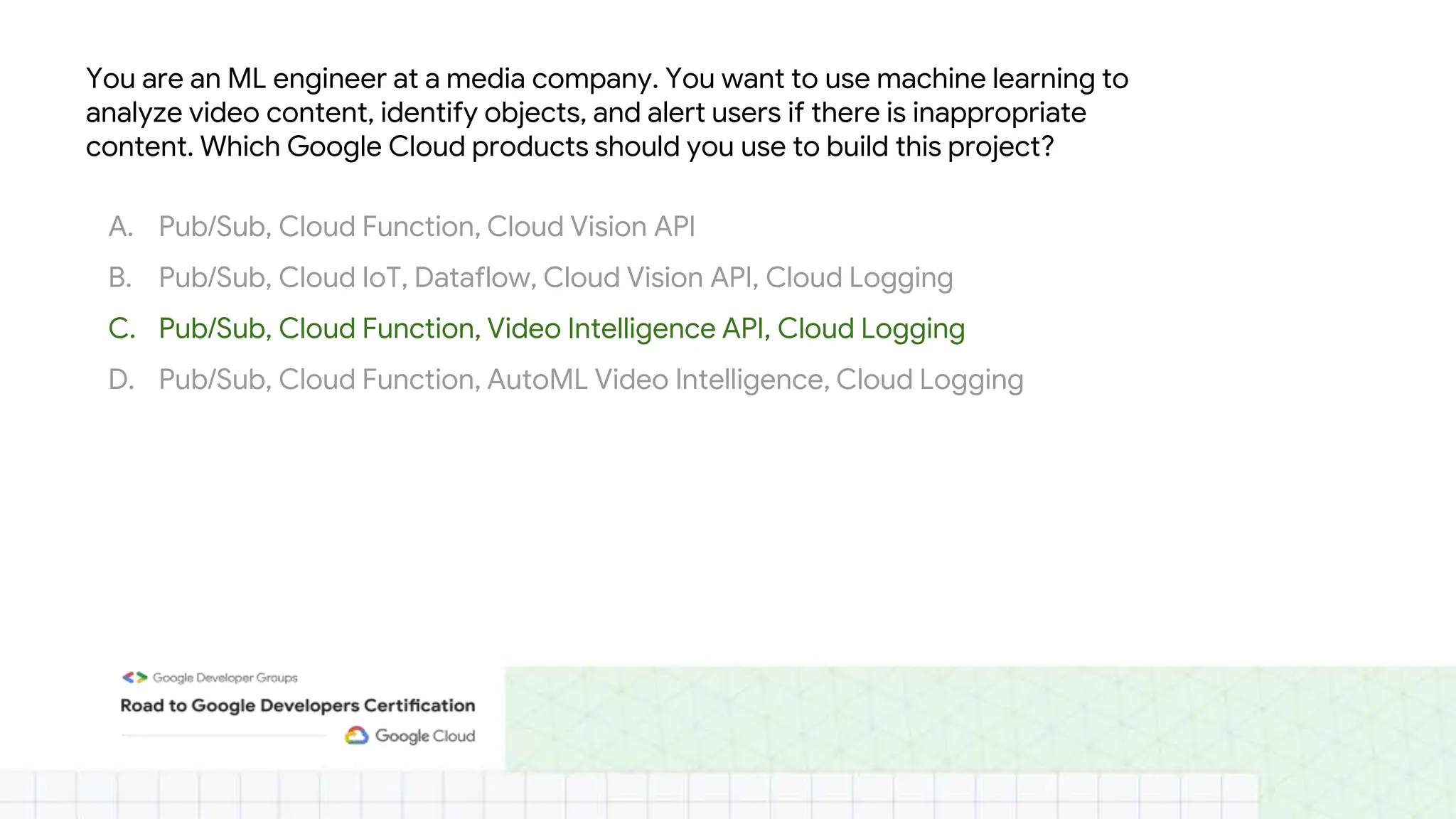
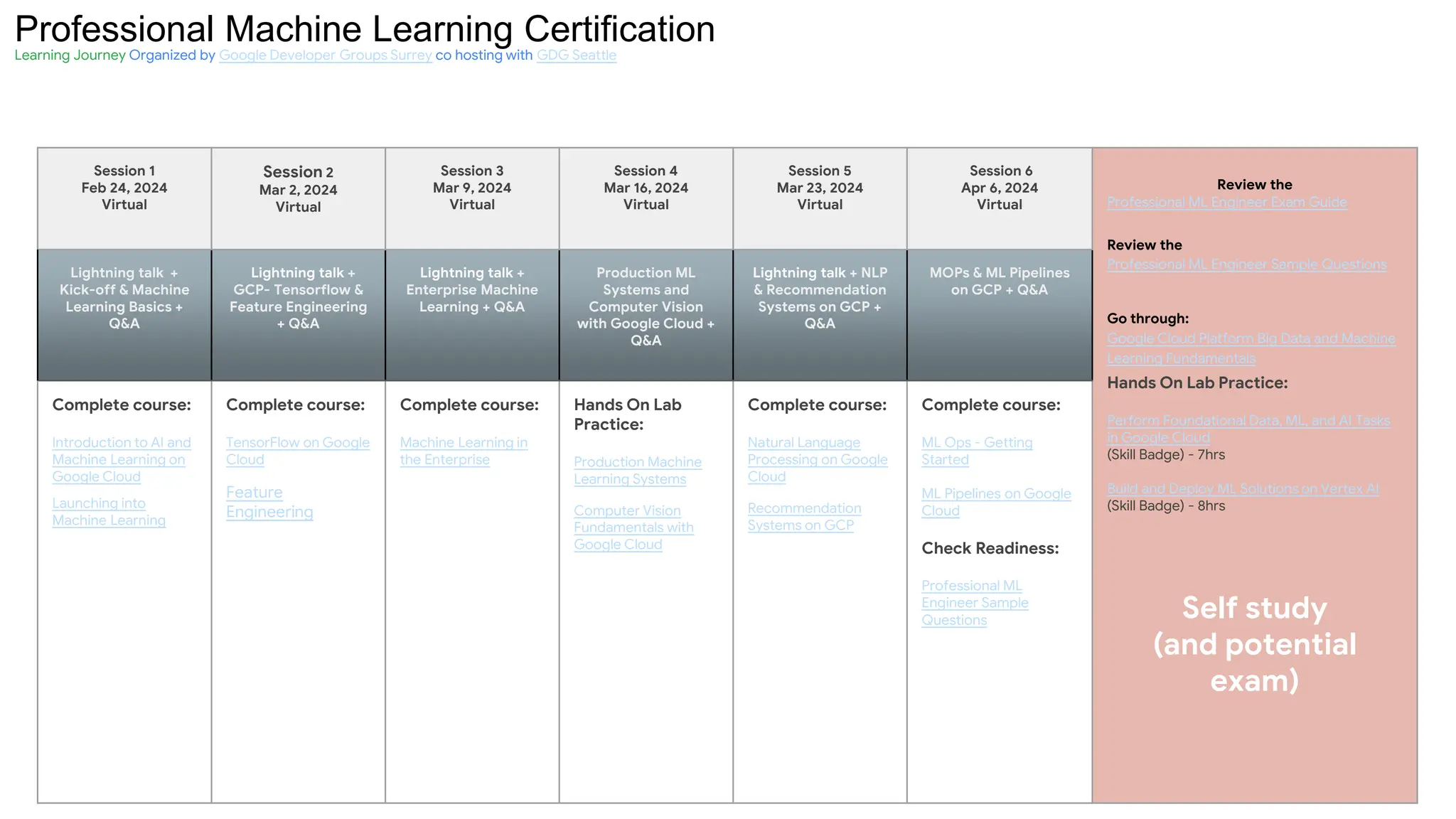
The document outlines the content and structure of session 6 of the Professional Machine Learning Engineer learning journey hosted by Google Developer Groups, detailing a timeline for sessions, key topics for review, and exam information. It covers essential aspects of machine learning including problem framing, solution architecture, data preparation, model development, and solution monitoring. Additionally, it provides sample exam questions and tips for effective preparation and test-taking strategies.