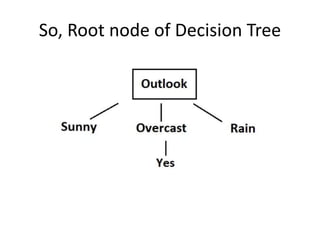
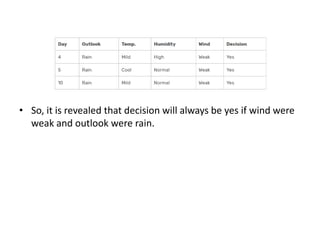
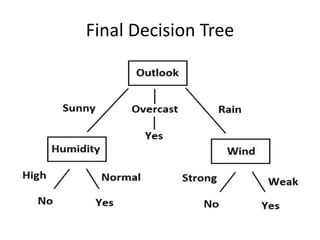
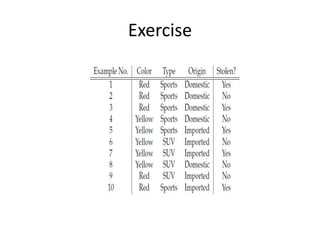
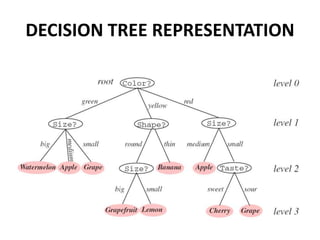
This document discusses decision tree learning algorithms. It begins with an introduction to decision trees, noting that they are widely used for inductive inference and represent learned functions as decision trees. It then discusses appropriate problems for decision tree learning, including instances represented by attribute-value pairs and discrete output values. The document provides examples of different decision tree algorithms like ID3, CART and C4.5 and explains the ID3 algorithm in detail. It also discusses concepts like entropy, information gain and using these measures to determine the best attribute to use at each node in growing the decision tree.








![Entropy and Information Gain
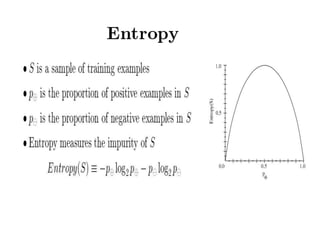
– Entropy(S) = ∑ – p(I) . log2p(I)
– Gain(S, A) = Entropy(S) – ∑ [ p(S|A) . Entropy(S|A) ]](https://image.slidesharecdn.com/decisiontree-240307123708-e0fb4080/85/Descision-making-descision-making-decision-tree-pptx-11-320.jpg)


![Wind factor on decision
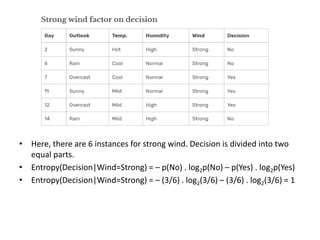
• Gain(Decision, Wind) = Entropy(Decision) – ∑ [ p(Decision|Wind) . Entropy(Decision|Wind) ]
• Wind attribute has two labels: weak and strong.
• Now, we need to calculate (Decision|Wind=Weak) and (Decision|Wind=Strong) respectively.
• . There are 8 instances for weak wind. Decision of 2 items are no and 6 items are yes.](https://image.slidesharecdn.com/decisiontree-240307123708-e0fb4080/85/Descision-making-descision-making-decision-tree-pptx-14-320.jpg)

![• Now compute Gain(Decision, Wind)
• Gain(Decision, Wind) =
Entropy(Decision) – [ p(Decision|Wind=Weak) . Entropy(Decision|Wind=Weak) ]
– [ p(Decision|Wind=Strong) . Entropy(Decision|Wind=Strong) ]
=0.940 – [ (8/14) . 0.811 ] – [ (6/14). 1] = 0.048
• Calculations for wind column is over. Now, we need to apply same calculations
for other columns to find the most dominant factor on decision.](https://image.slidesharecdn.com/decisiontree-240307123708-e0fb4080/85/Descision-making-descision-making-decision-tree-pptx-17-320.jpg)

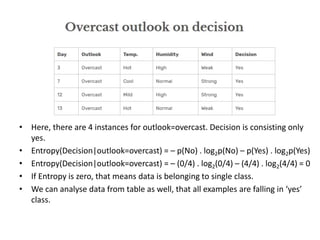
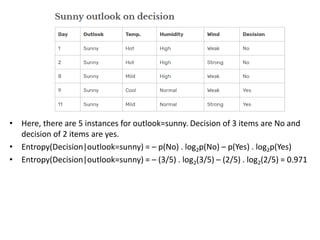
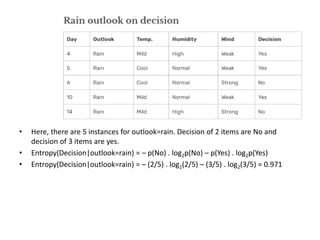
![• Now compute Gain(Decision, outlook)
• Gain(Decision, outlook) =
Entropy(Decision)
– [ p(Decision|outlook=overcast) . Entropy(Decision|outlook=overcast) ]
– [ p(Decision|outlook=sunny) . Entropy(Decision|outlook=sunny) ]
- [ p(Decision|outlook=rain) . Entropy(Decision|outlook=rain) ]
=0.940 – [ (4/14) . 0 ] – [ (5/14). 0.971] - [ (5/14). 0.971] = 0.246](https://image.slidesharecdn.com/decisiontree-240307123708-e0fb4080/85/Descision-making-descision-making-decision-tree-pptx-22-320.jpg)