





![Divide-and-Conquer: Constructing Decision TreesCalculations:Using the formulae for Information, initially we haveNumber of instances with class = Yes is 9 Number of instances with class = No is 5So we have P1 = 9/14 and P2 = 5/14Info[9/14, 5/14] = -9/14log(9/14) -5/14log(5/14) = 0.940 bitsNow for example lets consider Outlook attribute, we observe the following:](https://image.slidesharecdn.com/dataapplieddecision-100306091950-phpapp02/85/Data-Applied-Decision-Trees-7-320.jpg)
![Divide-and-Conquer: Constructing Decision TreesExample Contd.Gain by using Outlook for division = info([9,5]) – info([2,3],[4,0],[3,2]) = 0.940 – 0.693 = 0.247 bitsGain (outlook) = 0.247 bits Gain (temperature) = 0.029 bits Gain (humidity) = 0.152 bits Gain (windy) = 0.048 bitsSo since Outlook gives maximum gain, we will use it for divisionAnd we repeat the steps for Outlook = Sunny and Rainy and stop for Overcast since we have Information = 0 for it](https://image.slidesharecdn.com/dataapplieddecision-100306091950-phpapp02/85/Data-Applied-Decision-Trees-8-320.jpg)

![Divide-and-Conquer: Constructing Decision TreesHighly branching attributes: The problemInformation for such an attribute is 0info([0,1]) + info([0,1]) + info([0,1]) + …………. + info([0,1]) = 0It will hence have the maximum gain and will be chosen for branchingBut such an attribute is not good for predicting class of an unknown instance nor does it tells anything about the structure of divisionSo we use gain ratio to compensate for this](https://image.slidesharecdn.com/dataapplieddecision-100306091950-phpapp02/85/Data-Applied-Decision-Trees-10-320.jpg)
![Divide-and-Conquer: Constructing Decision TreesHighly branching attributes: Gain ratioGain ratio = gain/split infoTo calculate split info, for each instance value we just consider the number of instances covered by each attribute value, irrespective of the classThen we calculate the split info, so for identification code with 14 different values we have:info([1,1,1,…..,1]) = -1/14 x log1/14 x 14 = 3.807For Outlook we will have the split info:info([5,4,5]) = -1/5 x log 1/5 -1/4 x log1/4 -1/5 x log 1/5 = 1.577](https://image.slidesharecdn.com/dataapplieddecision-100306091950-phpapp02/85/Data-Applied-Decision-Trees-11-320.jpg)

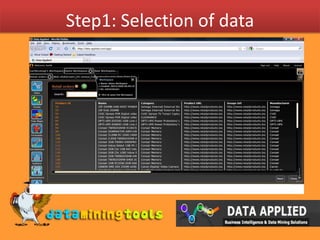
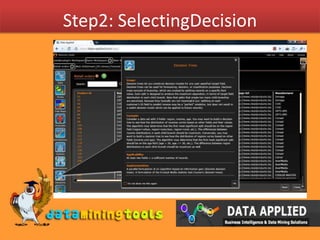



Decision trees are models that use divide and conquer techniques to split data into branches based on attribute values at each node. To construct a decision tree, an attribute is selected to label the root node using the maximum information gain approach. Then the process is recursively repeated on the branches. However, highly branching attributes may be favored. To address this, gain ratio is used which compensates for number of branches by considering split information. The example demonstrates calculating information gain and gain ratio to select the best attribute to split on at each node.


































































































