

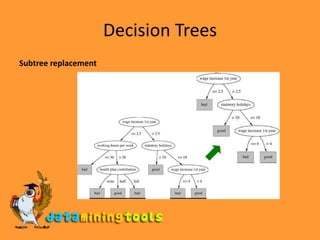
![Decision TreesExampleSplit on temperature attribute: 64 65 68 69 70 71 72 72 75 75 80 81 83 85 Yes No Yes YesYes No No Yes YesYes No Yes Yes Notemperature < 71.5: yes/4, no/2temperature > 71.5: yes/5, no/3Info([4,2],[5,3])= 6/14 info([4,2]) + 8/14 info([5,3]) = 0.939 bits](https://image.slidesharecdn.com/practicalmachinelearningtoolsandtechniques-100203234708-phpapp02/85/WEKA-Practical-Machine-Learning-Tools-And-Techniques-3-320.jpg)



![Classification rulesCriteria for choosing tests:p/t ratioMaximizes the ratio of positive instances with stress on accuracyp[log(p/t) – log(p/t)]Maximizes the number of positive instances with lesser accuracy](https://image.slidesharecdn.com/practicalmachinelearningtoolsandtechniques-100203234708-phpapp02/85/WEKA-Practical-Machine-Learning-Tools-And-Techniques-8-320.jpg)





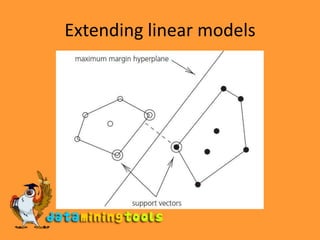









This document discusses several machine learning techniques including decision trees, classification rules, support vector machines, multilayer perceptrons, clustering, and the EM algorithm. It provides examples and explanations of how each technique works, such as how decision trees deal with numeric attributes by evaluating information gain to determine split points, and how the EM algorithm iterates between expectation and maximization steps to estimate cluster probabilities and distribution parameters.















































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
























































