




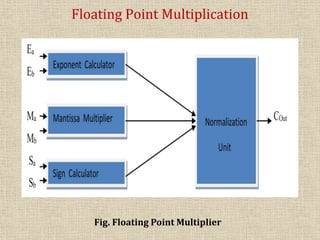





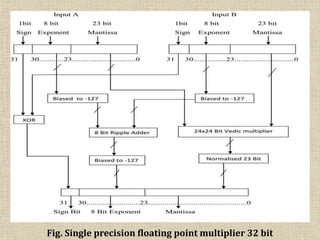










This seminar report summarizes the design and implementation of a floating point multiplier using Vedic multiplication techniques on an FPGA. It describes the key components of a floating point multiplier, reviews existing multiplication algorithms, and introduces the ancient Vedic multiplication method. The report outlines the design of a proposed 32-bit floating point Vedic multiplier, including mantissa, exponent, and sign calculation units. Experimental results show the Vedic multiplier utilizes 9% of slices on the target FPGA and has a maximum delay of 18.872ns, demonstrating its advantages over other multipliers in terms of speed and area efficiency.























































































