The document discusses image segmentation techniques. It defines image segmentation as partitioning a digital image into multiple segments or regions that are similar in characteristics such as color or texture. The main goal of image segmentation is to simplify an image into meaningful parts for analysis. Common techniques discussed include thresholding, clustering, edge detection, region growing, and neural networks. Thresholding uses threshold values to separate pixels into multiple classes or objects. Clustering groups similar image pixels together while edge detection finds boundaries between objects. The document also provides an example of the split and merge segmentation method.












![16
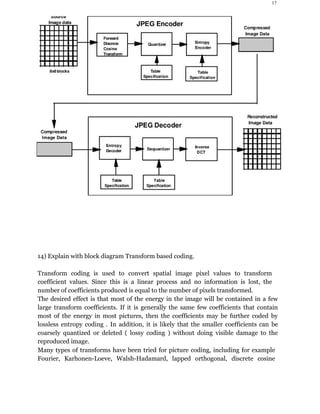
12) Block Diagram of JPEG encoder and Decoder.
1) Forward Discrete Cosine Transform (FDCT):
The still images are first partitioned into non-overlapping blocks of size 8x8 and the
image samples are shifted from unsigned integers with range [0, 2 p-1] to signed
integers
with range [-2 p-1, 2 p-1], where p is the number of bits (here,p=8 ).
To preserve freedom for innovation and customization within implementations, JPEG
neither specifies any unique FDCT algorithm, nor any unique IDCT algorithms.
2) Quantization:
Each of the 64 coefficients from the FDCT outputs of a block is uniformly quantized
according to a quantization table.
Since the aim is to compress the images without visible artifacts, each step-size
should be chosen as the perceptual threshold or for “just noticeable distortion”.
The quantized coefficients are zig-zag scanned.
The DC coefficient is encoded as a difference from the DC coefficient of the previous
block and the 63 AC coefficients are encoded into (run, level) pair.
3) Entropy Coder:
This is the final processing step of the JPEG encoder.
The JPEG standard specifies two entropy coding methods – Huffman and arithmetic
coding.
The baseline sequential JPEG uses Huffman only, but codecs with both methods are
specified for the other modes of operation.
Huffman coding requires that one or more sets of coding tables are specified by the
application.
The same table used for compression is used needed to decompress it.
The baseline JPEG uses only two sets of Huffman tables – one for DC and the other
for AC.](https://image.slidesharecdn.com/dipunit3-190502165305/85/TYBSC-CS-SEM-6-DIGITAL-IMAGE-PROCESSING-16-320.jpg)




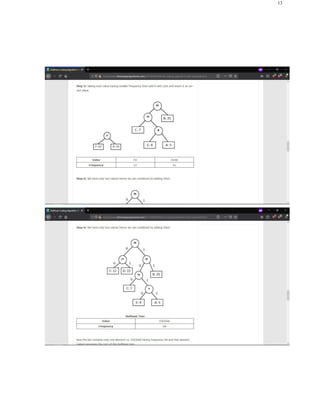
![23
5. Repeat the steps 3 and 4 for each part, until all the symbols are split into
individual subgroups.
25)How Arithmetic coding is used in image compression?
Arithmetic coding is a common algorithm used in both lossless and lossy data
compression algorithms.
It is an entropy encoding technique, in which the frequently seen symbols are encoded
with fewer bits than rarely seen symbols. It has some advantages over well-known
techniques such as Huffman coding.
The first thing to understand about arithmetic coding is what it produces.
Arithmetic coding takes a message (often a file) composed of symbols (nearly always
eight-bit characters), and converts it to a floating point number greater than or equal to
zero and less than one.
This floating point number can be quite long - effectively your entire output file is one
long number - which means it is not a normal data type that you are used to using in
conventional programming languages.
The implementation of the algorithm will have to create this floating point number
from scratch, bit by bit, and likewise read it in and decode it bit by bit.
This encoding process is done incrementally. As each character in a file is encoded, a
few bits will be added to the encoded message, so it is built up over time as the
algorithm proceeds.
The second thing to understand about arithmetic coding is that it relies on a model to
characterize the symbols it is processing. The job of the model is to tell the encoder
what the probability of a character is in a given message.
If the model gives an accurate probability of the characters in the message, they will be
encoded very close to optimally. If the model misrepresents the probabilities of symbols,
your encoder may actually expand a message instead of compressing it.
Arithmetic coding solves many limitations of Huffman coding.
i. Arithmetic encoders are better suited for adaptive models than Huffman coding.
ii. It is an entropy encoding technique, in which the frequently seen symbols are
encoded with fewer bits than lesser seen symbols.
iii. No assumption on encode source symbols one at a time.
iv. Sequences of source symbols are encoded together.
v. There is no one-to-one correspondence between source symbols and code words.
vi. Slower than Huffman coding but typically achieves better compression.
vii. A sequence of source symbols is assigned a single arithmetic code word which
corresponds to a sub-interval in [0,1].
viii. As the number of symbols in the message increases, the interval used to
represent it becomes smaller.
ix. Smaller intervals require more information units (i.e., bits) to be represented.](https://image.slidesharecdn.com/dipunit3-190502165305/85/TYBSC-CS-SEM-6-DIGITAL-IMAGE-PROCESSING-23-320.jpg)






































































