Downloaded 35 times






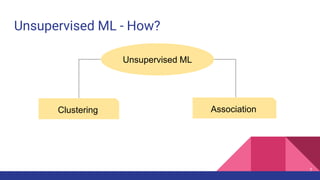
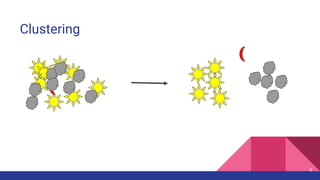
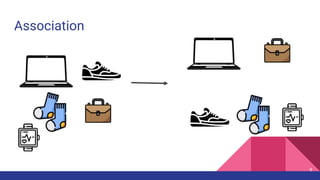

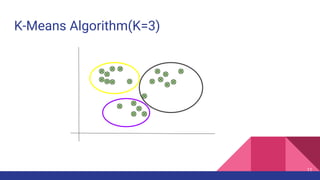
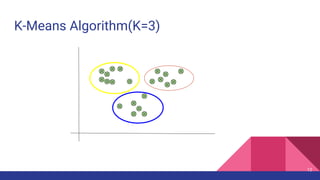



















The document provides an overview of unsupervised machine learning (ML), explaining its definition, importance, and various types, including supervised, unsupervised, and reinforcement learning. It discusses key algorithms such as k-means, hierarchical clustering, and the apriori association algorithm, along with their applications, advantages, and disadvantages. The document concludes with the pros and cons of unsupervised ML and contact information for Livares Technologies.























































































