This document provides a tutorial on support vector machines (SVM) for binary classification. It outlines the key concepts of SVM including linear separable and non-separable cases, soft margin classification, solving the SVM optimization problem, kernel methods for non-linear classification, commonly used kernel functions, and relationships between SVM and other methods like logistic regression. Example code for using SVM from the scikit-learn Python package is also provided.









![The Tutorial Routine Some Topics Packages
Solving SVM: Lagrangian Dual
Constraint optimization → Lagrangian Dual
Primal form:
min
w,b,ξ
1
2
||w||2
+ C
m
i=1
ξi
s.t. yi ((w · xi) + b) ≥ 1 − ξi , i = 1, 2, ..., m
ξi ≥ 0
(7)
The Primal Lagrangian:
L(w, b, ξ, α, µ) =
1
2
||w||2
+C
i
ξi −
i
αi {yi (w·x+b−1−ξi )}−
i
µi ξi
Because [7] is convex, Karush-Kuhn-Tucker conditions hold.](https://image.slidesharecdn.com/main-150203011416-conversion-gate01/85/A-Simple-Review-on-SVM-12-320.jpg)




![The Tutorial Routine Some Topics Packages
Conditions of Kernel Functions
Necessity: Kernel Matrix K = [k(xi , xj )]m×m must be positive
semidefinite:
tT
Kt =
i,j
ti tj k(xi , xj ) =
i,j
ti tj < Φ(xi ), Φ(xj ) >
=<
i
ti Φ(xi ),
j
tj Φ(xj ) >= |
i
ti Φ(xi )|2
≥ 0
Sufficiency in Continuous Form: Mercer’s Condition:
For any symmetric function k : X × X → R which is square
integrable in X × X, if it satisfies
X×X
k(x, x )f (x)f (x )dxdx ≥ 0 for all f ∈ L2(X)
there exist functions φi : X → R and numbers λi ≥ 0 that,
k(x, x ) =
i
λi φi (x)φi (x ) for all x, x in X](https://image.slidesharecdn.com/main-150203011416-conversion-gate01/85/A-Simple-Review-on-SVM-19-320.jpg)


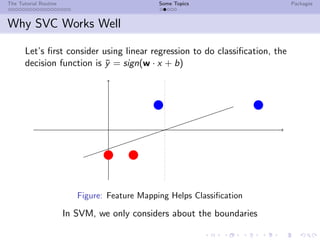


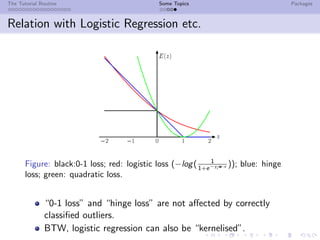
![The Tutorial Routine Some Topics Packages
Commonly Used Packages
libsvm(liblinear), svmlight and sklearn (python wrap-up of
libsvm)
Code example in sklearn
import numpy as np
X = np . a r r a y ([[ −1 , −1] , [ −2 , −1] , [ 1 , 1 ] , [ 2 , 1 ] ] )
y = np . a r r a y ( [ 1 , 1 , 2 , 2 ] )
from s k l e a r n . svm import SVC
c l f = SVC()
c l f . f i t (X, y )
c l f . p r e d i c t ([[ −0.8 , −1]])](https://image.slidesharecdn.com/main-150203011416-conversion-gate01/85/A-Simple-Review-on-SVM-26-320.jpg)



































































