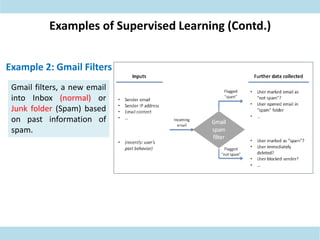
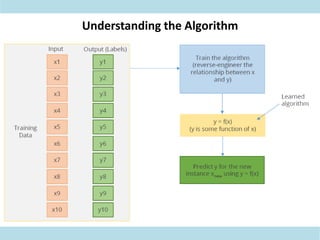
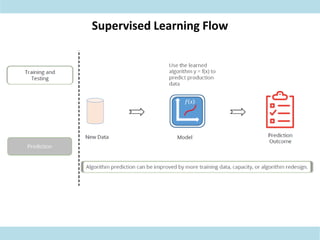
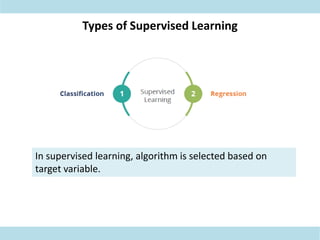
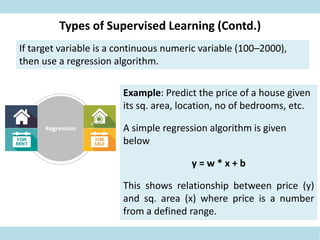
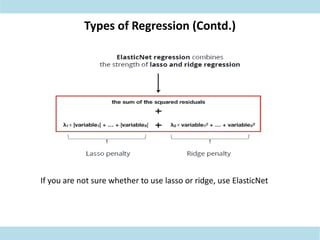
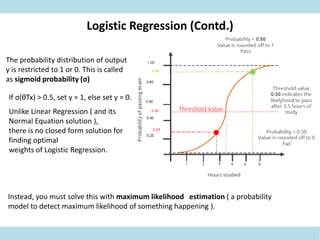
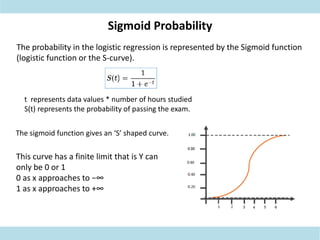
This document discusses supervised learning. Supervised learning uses labeled training data to train models to predict outputs for new data. Examples given include weather prediction apps, spam filters, and Netflix recommendations. Supervised learning algorithms are selected based on whether the target variable is categorical or continuous. Classification algorithms are used when the target is categorical while regression is used for continuous targets. Common regression algorithms discussed include linear regression, logistic regression, ridge regression, lasso regression, and elastic net. Metrics for evaluating supervised learning models include accuracy, R-squared, adjusted R-squared, mean squared error, and coefficients/p-values. The document also covers challenges like overfitting and regularization techniques to address it.