Download as PDF, PPTX




![Features (Variables/Attributes) in ML
• Vector - collection / array of numbers in similar data type
• Feature Vector is an n-dimensional vector of
numerical features that represent some object.
• Eg. Length of 3 tables in feet
𝐿[1]
𝐿[2]
𝐿[3]
=
5
7
3](https://image.slidesharecdn.com/machinelearning-210424062923/85/Machine-learning-Introduction-7-320.jpg)







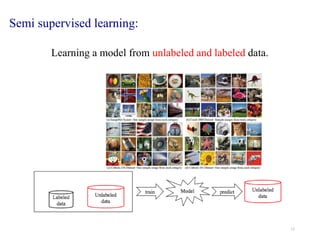








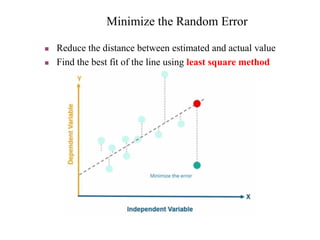



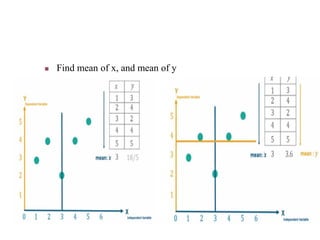






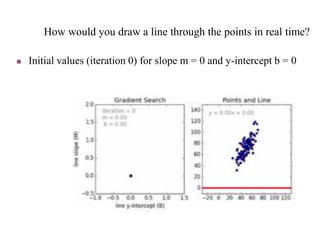









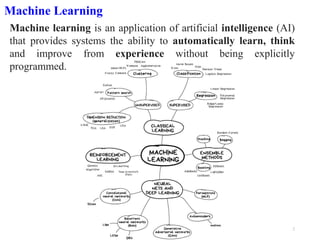
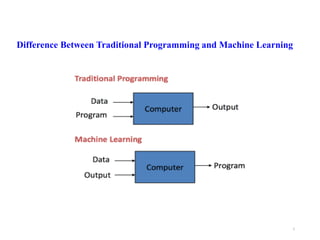
Machine learning is a form of artificial intelligence that allows systems to learn from data and improve automatically without being explicitly programmed. It works by building mathematical models based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to perform the task. Linear regression is a commonly used machine learning algorithm that allows predicting a dependent variable from an independent variable by finding the best fit line through the data points. It works by minimizing the sum of squared differences between the actual and predicted values of the dependent variable. Gradient descent is an optimization algorithm used to train machine learning models by minimizing a cost function relating predictions to ground truths.























































































