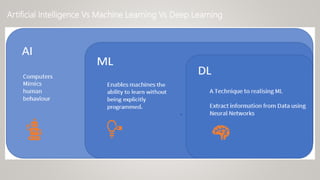
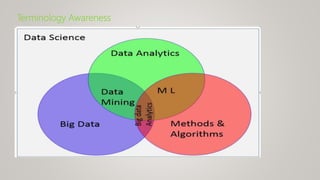


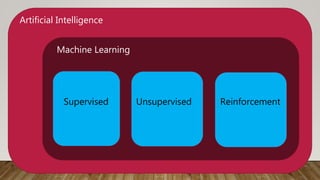


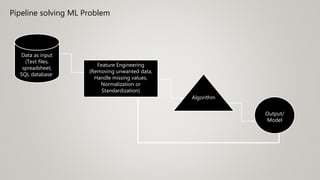
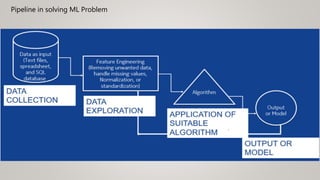





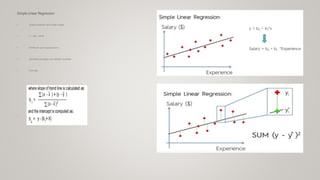
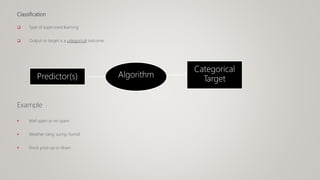






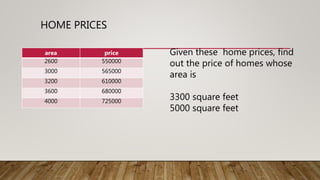
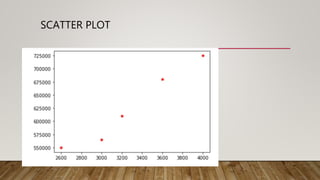
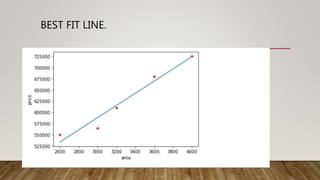
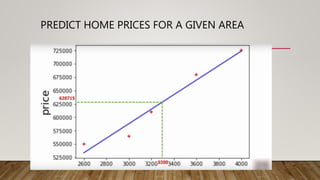
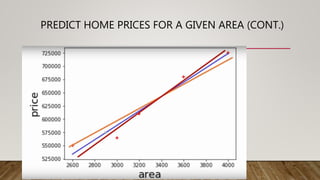
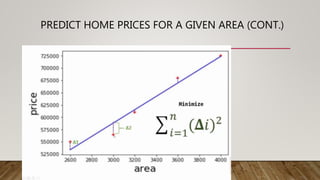





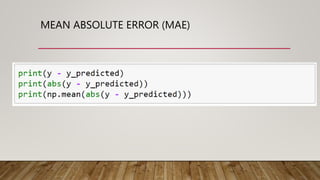



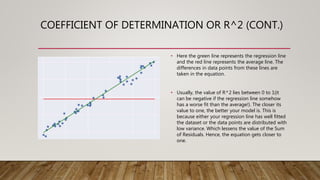


This document provides an overview of machine learning (ML) and its relationship with artificial intelligence (AI), defining key concepts such as supervised, unsupervised, and reinforcement learning. It covers various types of learning models, including regression and classification, and discusses their applications in real-world scenarios like self-driving cars and healthcare diagnostics. Additionally, the document addresses data processing techniques, feature engineering, and performance evaluation metrics for machine learning models.