Download as PDF, PPTX



























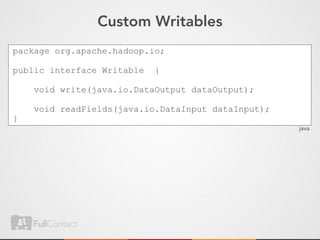
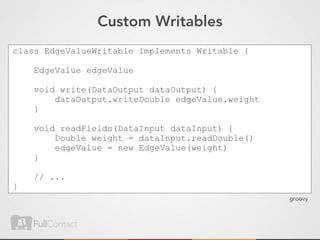
![Don’t get fancy with byte[]
class EdgeValueWritable implements Writable {
EdgeValue edgeValue
byte[] toBytes() {
// use strings if you can help it
}
static EdgeValueWritable fromBytes(byte[] bytes) {
// use strings if you can help it
}
}
groovy](https://image.slidesharecdn.com/storingandmanipulatinggraphsinhbase-updated-120524173208-phpapp02/85/Storing-and-manipulating-graphs-in-HBase-41-320.jpg)
![Querying by vertex
def get = new Get(vertexKeyBytes)
get.addFamily(edgesFamilyBytes)
Result result = table.get(get);
result.noVersionMap.each {family, data ->
// construct edge objects as needed
// data is a Map<byte[],byte[]>
}](https://image.slidesharecdn.com/storingandmanipulatinggraphsinhbase-updated-120524173208-phpapp02/85/Storing-and-manipulating-graphs-in-HBase-42-320.jpg)
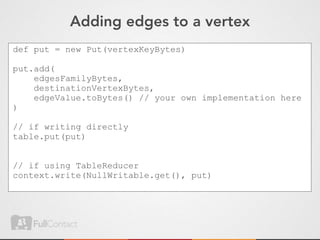
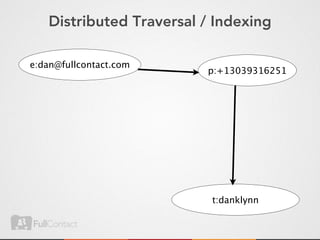




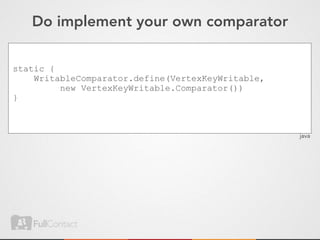
![Do implement your own comparator
public static class Comparator
extends WritableComparator {
public int compare(
byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
// .....
}
}
java](https://image.slidesharecdn.com/storingandmanipulatinggraphsinhbase-updated-120524173208-phpapp02/85/Storing-and-manipulating-graphs-in-HBase-59-320.jpg)
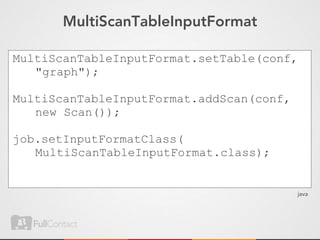




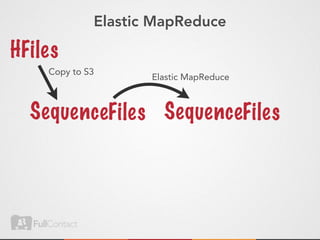
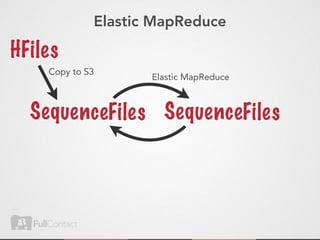
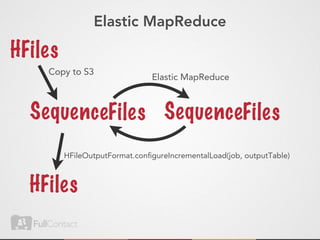
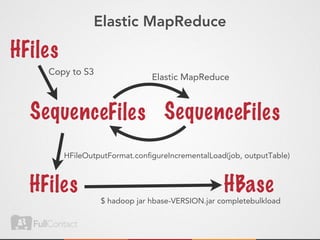



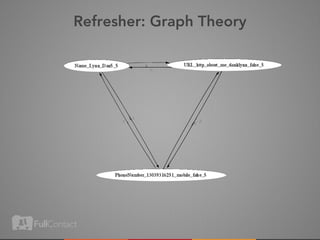
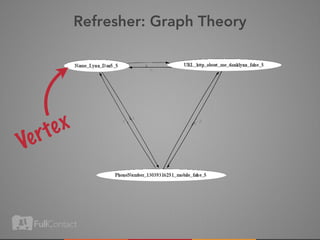
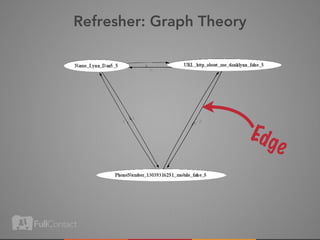
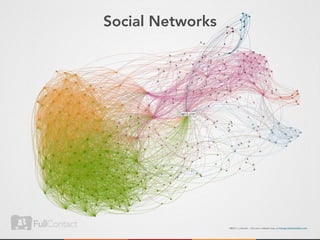
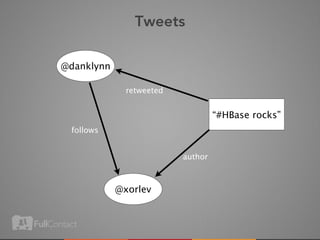
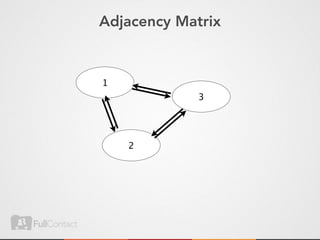
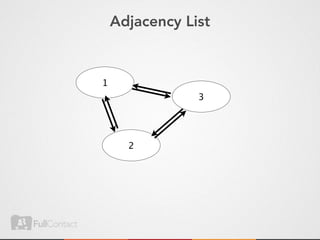
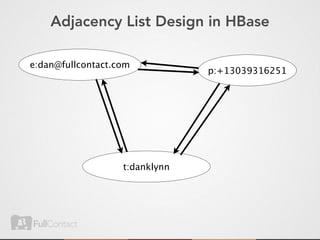
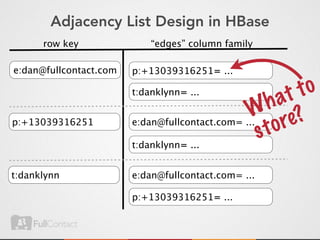
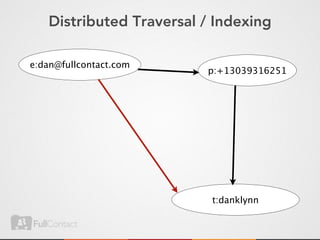
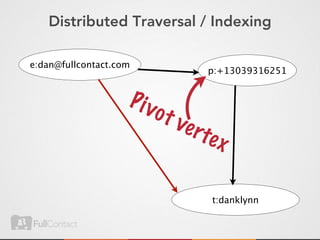
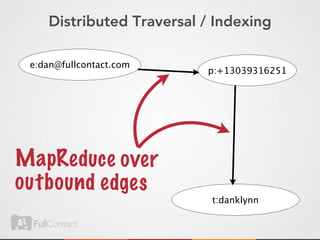
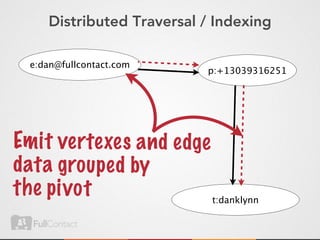
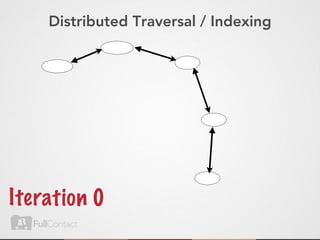
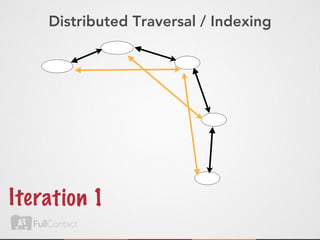
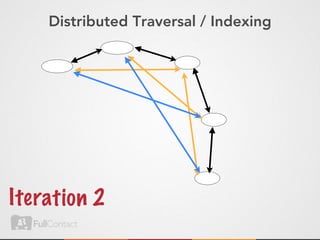
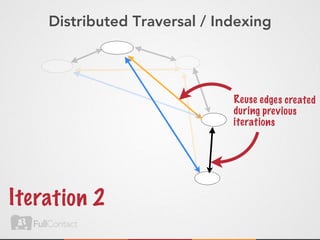
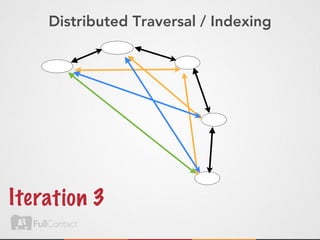
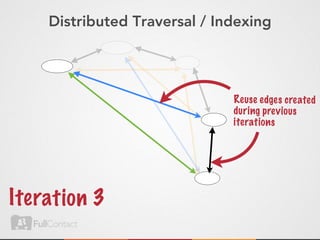
This document discusses storing and manipulating graphs in HBase. It provides an overview of graph theory concepts and different modeling techniques for storing graphs in HBase, including the adjacency matrix and adjacency list approaches. It also covers techniques for distributed traversal and querying of graphs stored in HBase using MapReduce jobs. Key tips discussed include implementing custom comparators and using utilities like MultiScanTableInputFormat and TableMapReduceUtil.
















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















