Download as PDF, PPTX







![The Core is the Cassandra Source
https://github.com/datastax/spark-cassandra-connector/tree/master/spark-cassandra-
connector/src/main/scala/org/apache/spark/sql/cassandra
/**
* Implements [[BaseRelation]]]], [[InsertableRelation]]]] and [[PrunedFilteredScan]]]]
* It inserts data to and scans Cassandra table. If filterPushdown is true, it pushs down
* some filters to CQL
*
*/
DataFrame
source
org.apache.spark.sql.cassandra](https://image.slidesharecdn.com/sparkcassandradataframes-150922055615-lva1-app6891/85/Spark-Cassandra-Connector-Dataframes-7-320.jpg)
![The Core is the Cassandra Source
https://github.com/datastax/spark-cassandra-connector/tree/master/spark-cassandra-
connector/src/main/scala/org/apache/spark/sql/cassandra
/**
* Implements [[BaseRelation]]]], [[InsertableRelation]]]] and [[PrunedFilteredScan]]]]
* It inserts data to and scans Cassandra table. If filterPushdown is true, it pushs down
* some filters to CQL
*
*/
DataFrame
CassandraSourceRelation
CassandraTableScanRDDConfiguration](https://image.slidesharecdn.com/sparkcassandradataframes-150922055615-lva1-app6891/85/Spark-Cassandra-Connector-Dataframes-8-320.jpg)



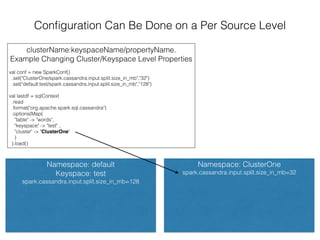
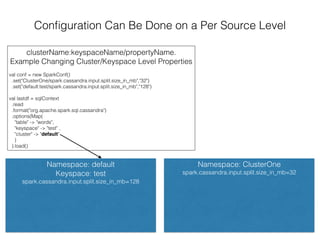
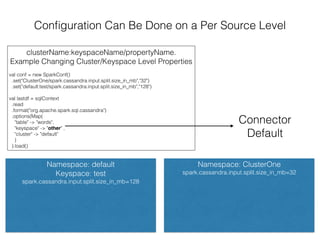

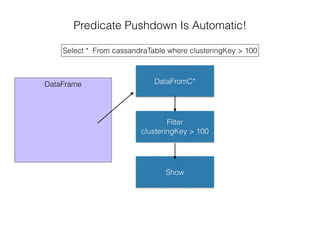
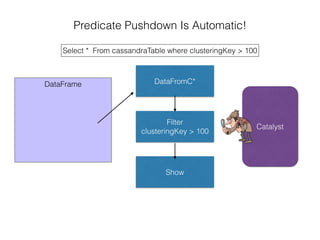
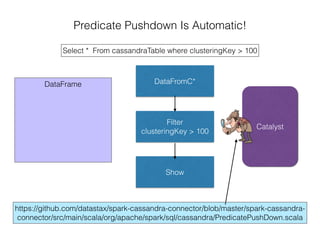
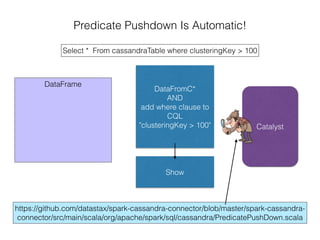





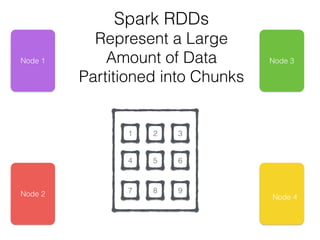
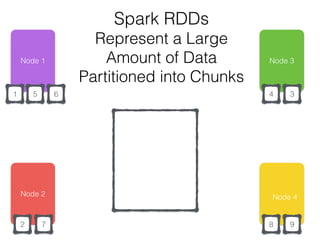
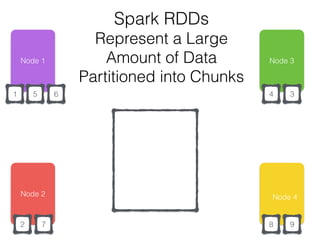

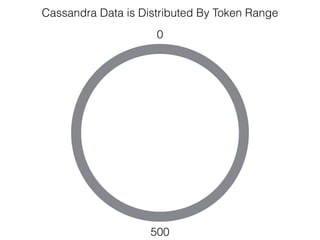
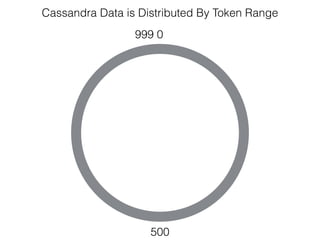
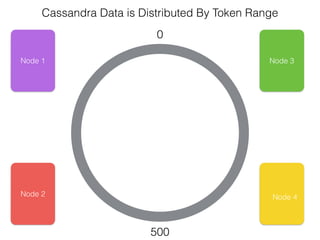
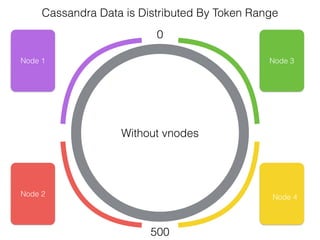
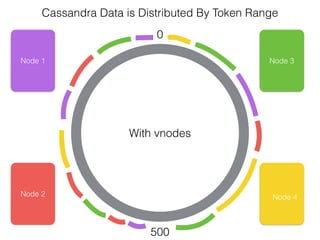
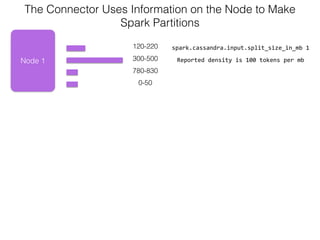
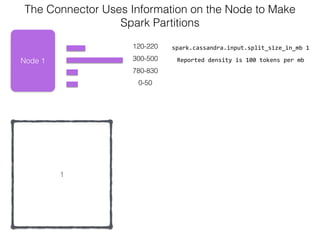
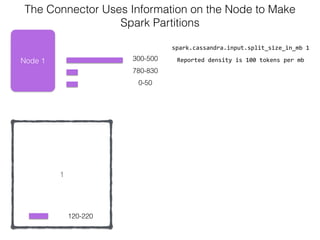
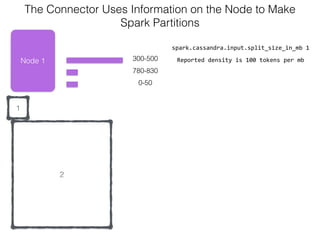
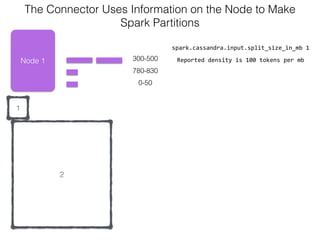
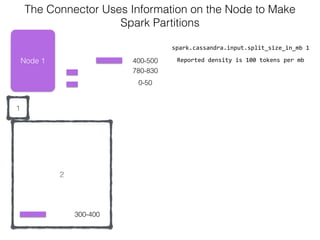
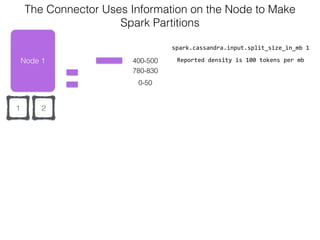
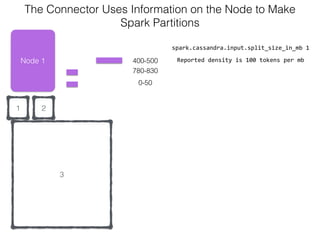
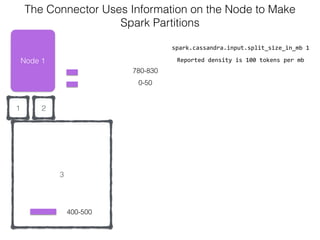
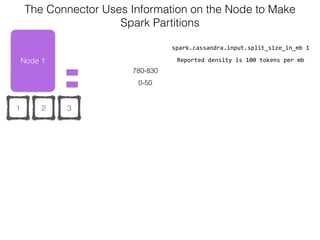
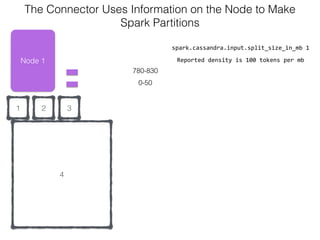
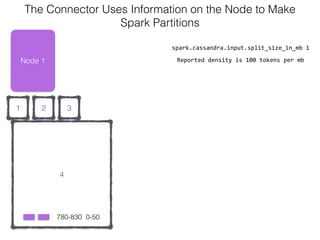
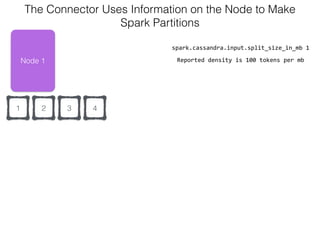
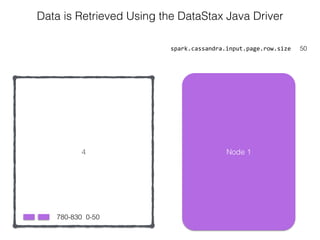


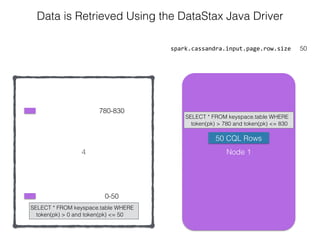

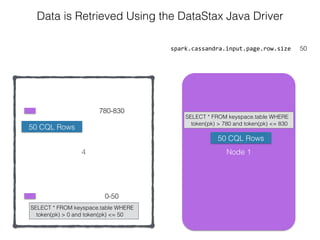

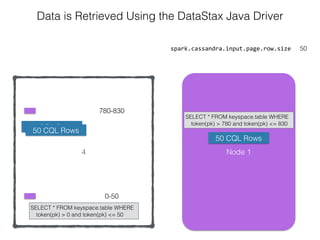
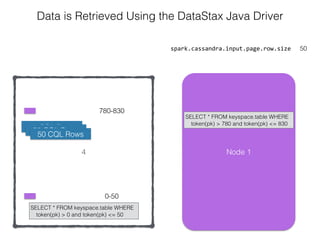
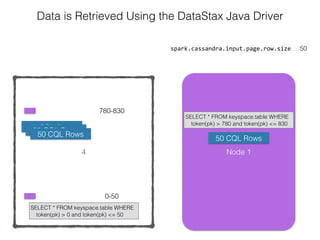
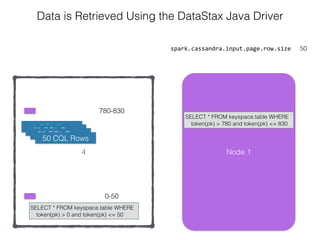
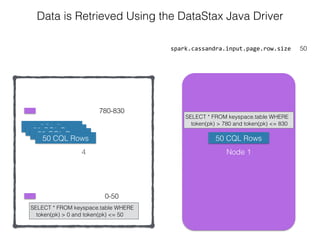
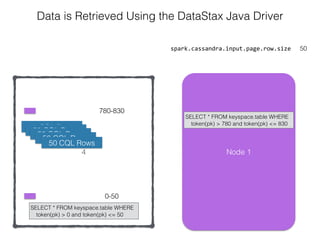
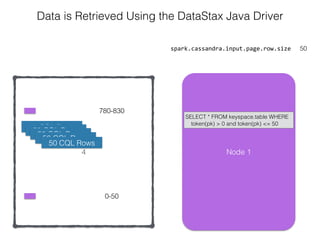
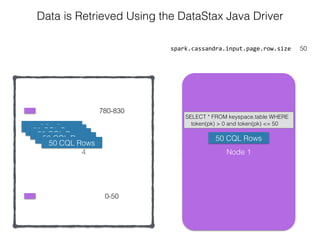
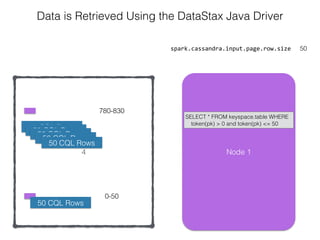
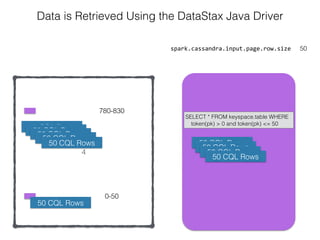
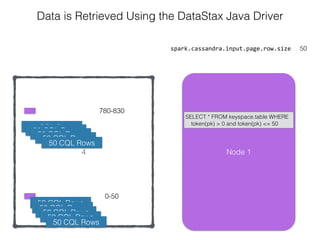

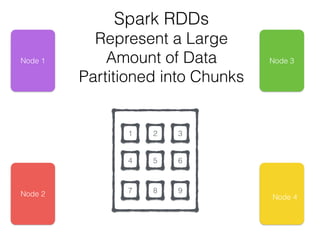
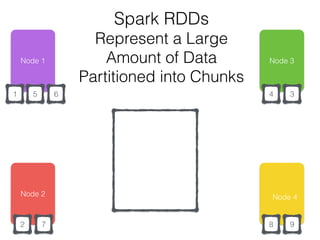
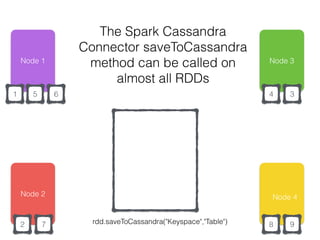
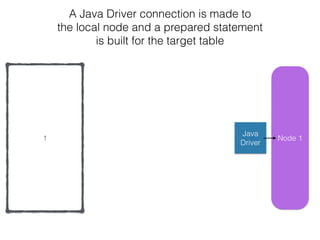
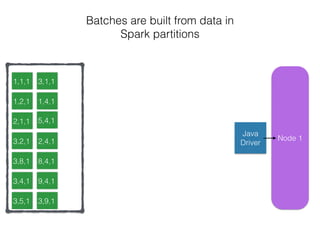
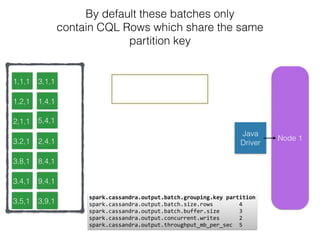
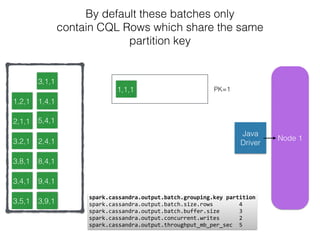
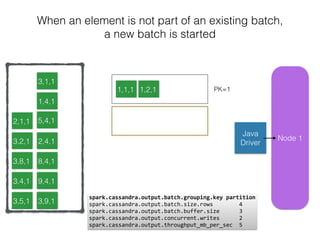
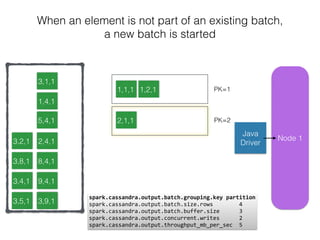
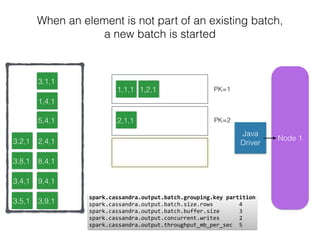
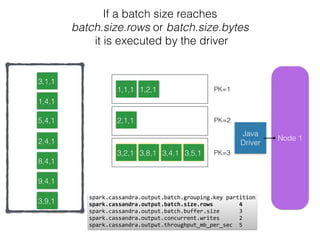
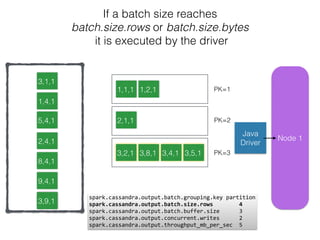
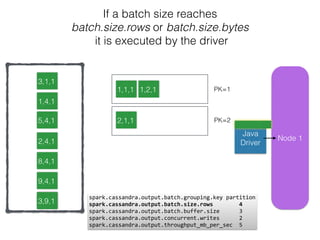
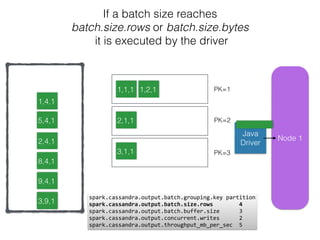
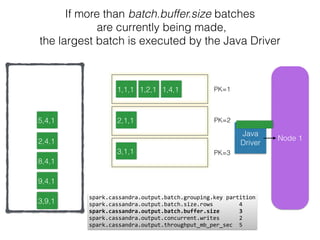
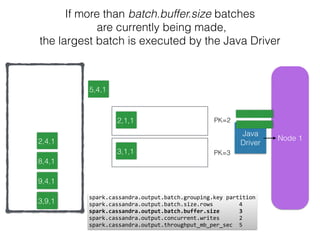
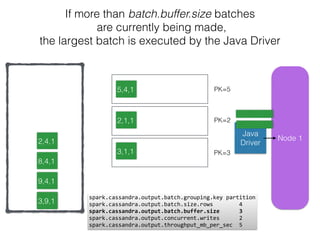
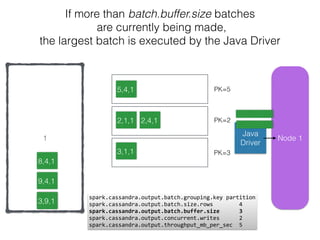
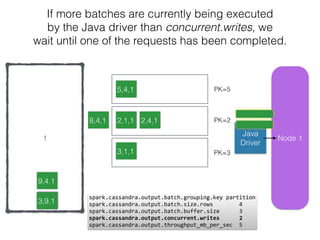
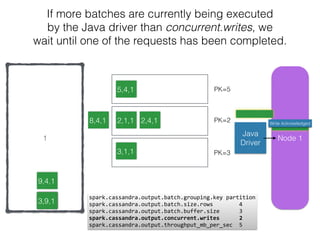
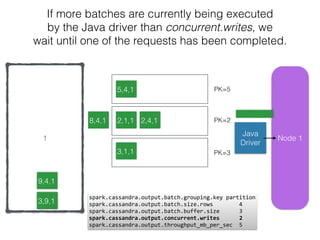
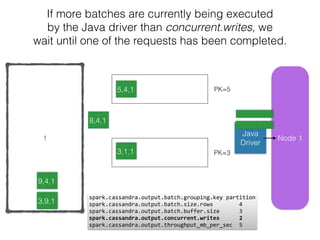
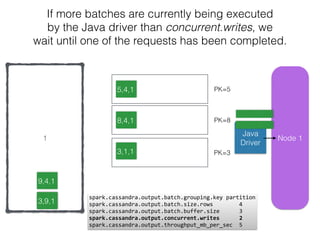
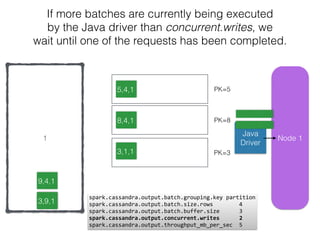
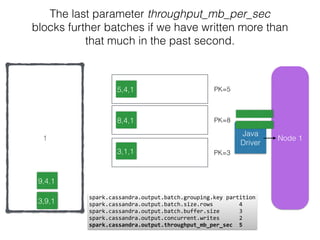
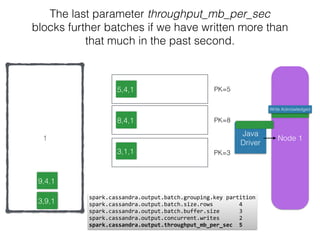

The document discusses how the Spark Cassandra Connector works. It explains that the connector uses information about how data is partitioned in Cassandra nodes to generate Spark partitions that correspond to the token ranges in Cassandra. This allows data to be read from Cassandra in parallel across the Spark partitions. The connector also supports automatically pushing down filter predicates to the Cassandra database to reduce the amount of data read.




























































































