Downloaded 147 times













![private final static IntWritable one = new IntWritable(1);!
private Text word = new Text();!
!
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) thro
IOException {!
String line = value.toString();!
StringTokenizer tokenizer = new StringTokenizer(line);!
while (tokenizer.hasMoreTokens()) {!
word.set(tokenizer.nextToken());!
output.collect(word, one);!
}!
}!
}!
!
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {!
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter
reporter) throws IOException {!
int sum = 0;!
while (values.hasNext()) {!
sum += values.next().get();!
}!
output.collect(key, new IntWritable(sum));!
}!
}!
!
public static void main(String[] args) throws Exception {!
JobConf conf = new JobConf(WordCount.class);!
conf.setJobName("wordcount");!
!
conf.setOutputKeyClass(Text.class);!
conf.setOutputValueClass(IntWritable.class);!
!
conf.setMapperClass(Map.class);!
conf.setCombinerClass(Reduce.class);!
conf.setReducerClass(Reduce.class);!
!
conf.setInputFormat(TextInputFormat.class);!
conf.setOutputFormat(TextOutputFormat.class);!
!
FileInputFormat.setInputPaths(conf, new Path(args[0]));!
FileOutputFormat.setOutputPath(conf, new Path(args[1]));!
!
JobClient.runJob(conf);!
}!
}!
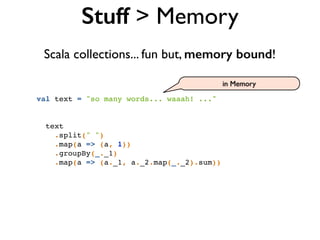
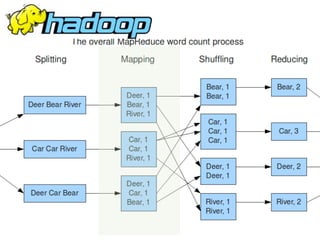
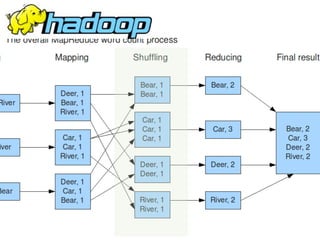
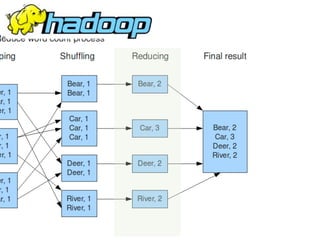
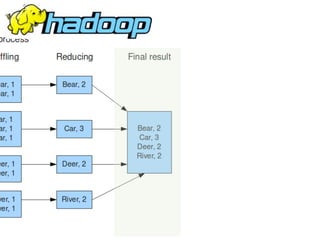
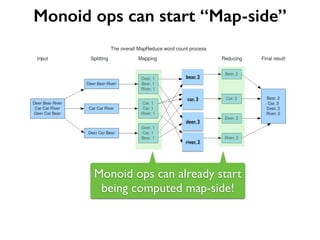
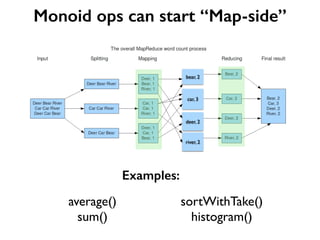
Why Scalding?
Word Count in Hadoop MR](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-26-320.jpg)







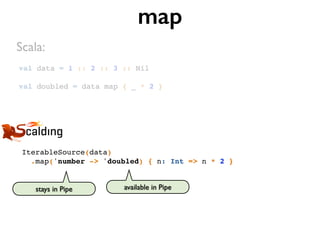






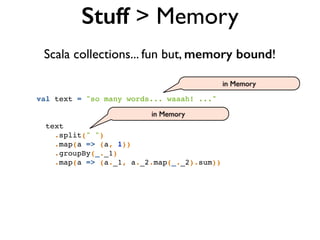
![val data = "1" :: "2,2" :: "3,3,3" :: Nil // List[String]
val numbers = data flatMap { line => // String
line.split(",") // Array[String]
} map { _.toInt } // List[Int]
flatMap
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-51-320.jpg)
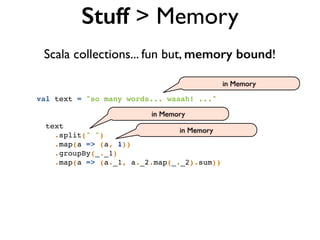
![val data = "1" :: "2,2" :: "3,3,3" :: Nil // List[String]
val numbers = data flatMap { line => // String
line.split(",") // Array[String]
} map { _.toInt } // List[Int]
flatMap
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-52-320.jpg)
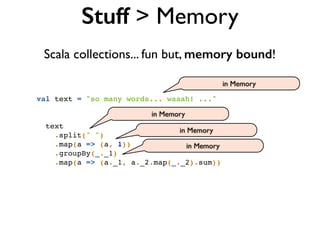
![val data = "1" :: "2,2" :: "3,3,3" :: Nil // List[String]
val numbers = data flatMap { line => // String
line.split(",") // Array[String]
} map { _.toInt } // List[Int]
flatMap
TextLine(data) // like List[String]
.flatMap('line -> 'word) { _.split(",") } // like List[String]
.map('word -> 'number) { _.toInt } // like List[Int]
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-53-320.jpg)

![val data = "1" :: "2,2" :: "3,3,3" :: Nil // List[String]
val numbers = data flatMap { line => // String
line.split(",").map(_.toInt) // Array[Int]
}
flatMap
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-55-320.jpg)
![val data = "1" :: "2,2" :: "3,3,3" :: Nil // List[String]
val numbers = data flatMap { line => // String
line.split(",").map(_.toInt) // Array[Int]
}
flatMap
TextLine(data) // like List[String]
.flatMap('line -> 'word) { _.split(",").map(_.toInt) }
// like List[Int]
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-56-320.jpg)

![val data = 1 :: 2 :: 30 :: 42 :: Nil // List[Int]
val groups = data groupBy { _ < 10 }
groups // Map[Boolean, Int]
groupBy
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-58-320.jpg)
![val data = 1 :: 2 :: 30 :: 42 :: Nil // List[Int]
val groups = data groupBy { _ < 10 }
groups // Map[Boolean, Int]
groupBy
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-59-320.jpg)
![val data = 1 :: 2 :: 30 :: 42 :: Nil // List[Int]
val groups = data groupBy { _ < 10 }
groups // Map[Boolean, Int]
groupBy
IterableSource(List(1, 2, 30, 42), 'num)
.map('num -> 'lessThanTen) { i: Int => i < 10 }
.groupBy('lessThanTen) { _.size }
Scala:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-60-320.jpg)
![val data = 1 :: 2 :: 30 :: 42 :: Nil // List[Int]
val groups = data groupBy { _ < 10 }
groups // Map[Boolean, Int]
groupBy
IterableSource(List(1, 2, 30, 42), 'num)
.map('num -> 'lessThanTen) { i: Int => i < 10 }
.groupBy('lessThanTen) { _.size }
Scala:
groups all with == value](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-61-320.jpg)
![val data = 1 :: 2 :: 30 :: 42 :: Nil // List[Int]
val groups = data groupBy { _ < 10 }
groups // Map[Boolean, Int]
groupBy
IterableSource(List(1, 2, 30, 42), 'num)
.map('num -> 'lessThanTen) { i: Int => i < 10 }
.groupBy('lessThanTen) { _.size }
Scala:
groups all with == value 'lessThanTenCounts](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-62-320.jpg)




![groupBy
IterableSource(List(1, 2, 30, 42), 'num)
.map('num -> 'lessThanTen) { i: Int => i < 10 }
.groupBy('lessThanTen) { _.sum('total) }
'total = [3, 74]](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-67-320.jpg)





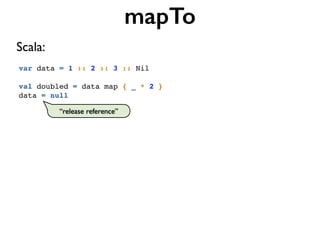
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
!
!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-73-320.jpg)
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
.groupBy('word) { group => group.size('count) }!
!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-74-320.jpg)
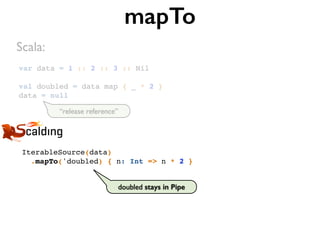
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
.groupBy('word) { group => group.size }!
!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-75-320.jpg)
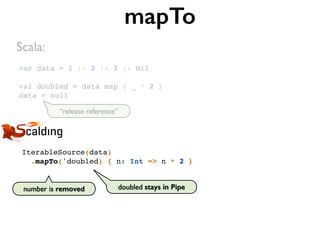
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
.groupBy('word) { _.size }!
!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-76-320.jpg)
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
.groupBy('word) { _.size }!
.write(Tsv(outputFile))!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-77-320.jpg)
![class WordCountJob(args: Args) extends Job(args) {!
!
val inputFile = args("input")!
val outputFile = args("output")!
!
TextLine(inputFile)!
.flatMap('line -> 'word) { line: String => tokenize(line) }!
.groupBy('word) { _.size }!
.write(Tsv(outputFile))!
!
def tokenize(text: String): Array[String] = implemented!
}
Word Count in Scalding
4{](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-78-320.jpg)

!
}!
.write(Tsv(output))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-80-320.jpg)
!
}!
.write(Tsv(output))
1!107!
2!144!
3!16!
… …](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-81-320.jpg)
!
}!
.write(Tsv(output, writeHeader = true))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-82-320.jpg)
!
}!
.write(Tsv(output, writeHeader = true))
shopId! totalSoldItems!
1!! ! ! 107!
2!! ! ! 144!
3!! ! ! 16!
…!! ! ! …](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-83-320.jpg)
!
}!
.groupAll { _.sortBy('totalSoldItems).reverse }!
.write(Tsv(output, writeHeader = true))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-84-320.jpg)
!
}!
.groupAll { _.sortBy('totalSoldItems).reverse }!
.write(Tsv(output, writeHeader = true))
shopId! totalSoldItems!
2!! ! ! 144 !
1!! ! ! 107!
3!! ! ! 16!
…!! ! ! …](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-85-320.jpg)
!
}!
.groupAll { _.sortBy(‘totalSoldItems).reverse.take(3) }!
.write(Tsv(output, writeHeader = true))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-86-320.jpg)
!
}!
.groupAll { _.sortBy(‘totalSoldItems).reverse.take(3) }!
.write(Tsv(output, writeHeader = true))
shopId! totalSoldItems!
2!! ! ! 144 !
1!! ! ! 107!
3!! ! ! 16](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-87-320.jpg)
!
}!
.groupAll { _.sortBy(‘totalSoldItems).reverse.take(3) }!
.write(Tsv(output, writeHeader = true))
shopId! totalSoldItems!
2!! ! ! 144 !
1!! ! ! 107!
3!! ! ! 16
SLOW! Instead do sortWithTake!SLOW! Instead do sortWithTake!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-88-320.jpg)
!
}!
.groupAll { !
_.sortedReverseTake[Long]('totalSold -> 'x, 3) !
}!
.write(Tsv(output, writeHeader = true))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-89-320.jpg)
!
}!
.groupAll { !
_.sortedReverseTake[Long]('totalSold -> 'x, 3) !
}!
.write(Tsv(output, writeHeader = true))
x!
List((5,146), (2,142), (3,32))!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-90-320.jpg)
!
}!
.groupAll { !
_.sortedReverseTake[Long]('totalSold -> 'x, 3) !
}!
.write(Tsv(output, writeHeader = true))
x!
List((5,146), (2,142), (3,32))!
WAT!?](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-91-320.jpg)
!
}!
.groupAll { !
_.sortedReverseTake[Long]('totalSold -> 'x, 3) !
}!
.write(Tsv(output, writeHeader = true))
x!
List((5,146), (2,142), (3,32))!
WAT!?
Emits scala.collection.List[_]](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-92-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-93-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))
Provide Ordering explicitly because implicit Ordering
is not enough for Tuple2 here](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-94-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))
“What’s the top 3 shops?”](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-95-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))
“What’s the top 3 shops?”
shopId! totalSoldItems!
2!! ! ! 144 !
1!! ! ! 107!
3!! ! ! 16](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-96-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))
“What’s the top 3 shops?”](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-97-320.jpg)
!
}!
.groupAll { !
_.sortWithTake(('shopId, 'totalSold) -> 'x, 3) { !
(l: (Long, Long), r: (Long, Long)) => !
l._2 < l._2 !
}!
}!
.flatMapTo('x -> ('shopId, 'totalSold)) { !
x: List[(Long, Long)] => x!
}!
.write(Tsv(output, writeHeader = true))
“What’s the top 3 shops?”
MUCH faster Job
=
Happier me.](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-98-320.jpg)


![trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
Reduce, these Monoids](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-101-320.jpg)
![Reduce, these Monoids
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-102-320.jpg)
![Reduce, these Monoids
+ 3 laws:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-103-320.jpg)
![Reduce, these Monoids
+ 3 laws:
Closure:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-104-320.jpg)
![Reduce, these Monoids
+ 3 laws:
(T, T) => TClosure:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
∀a,b∈T:a·b∈T
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-105-320.jpg)
![Reduce, these Monoids
+ 3 laws:
(T, T) => TClosure:
Associativity:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
∀a,b∈T:a·b∈T
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-106-320.jpg)
![Reduce, these Monoids
+ 3 laws:
(T, T) => TClosure:
Associativity:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
∀a,b∈T:a·b∈T
∀a,b,c∈T:(a·b)·c=a·(b·c)
(a + b) + c!
==!
a + (b + c)
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-107-320.jpg)
![Reduce, these Monoids
+ 3 laws:
(T, T) => TClosure:
Associativity:
Identity element:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
∀a,b∈T:a·b∈T
∀a,b,c∈T:(a·b)·c=a·(b·c)
(a + b) + c!
==!
a + (b + c)
interface:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-108-320.jpg)
![Reduce, these Monoids
+ 3 laws:
(T, T) => TClosure:
Associativity:
Identity element:
trait Monoid[T] {!
def zero: T!
def +(a: T, b: T): T!
}
∀a,b∈T:a·b∈T
∀a,b,c∈T:(a·b)·c=a·(b·c)
(a + b) + c!
==!
a + (b + c)
interface:
∃z∈T:∀a∈T:z·a=a·z=a z + a == a + z == a](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-109-320.jpg)
![Reduce, these Monoids
object IntSum extends Monoid[Int] {!
def zero = 0!
def +(a: Int, b: Int) = a + b!
}
Summing:](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-110-320.jpg)






![BloomFilterMonoid
Csv(input, separator, ('shopId, 'itemId, 'itemName, 'quantity))!
.groupBy('shopId) {!
_.foldLeft('itemName -> 'itemBloom)(bfMonoid.zero) { !
(bf: BF, itemId: String) => bf + itemId !
}!
}!
.map(‘itemBloom -> 'hasSoldBeer) { b: BF => b.contains(“beer").isTrue }!
.map('itemBloom -> 'hasSoldWurst) { b: BF => b.contains("wurst").isTrue }!
.discard('itemBloom)!
.write(Tsv(output, writeHeader = true))
shopId! hasSoldBeer!hasSoldWurst!
1!! ! ! false!! ! ! true!
2!! ! ! false!! ! ! true!
3!! ! ! false!! ! ! true!
4!! ! ! true! ! ! ! false!
5!! ! ! true! ! ! ! false!
Why not Set[String]? It would OutOfMemory.](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-119-320.jpg)
![BloomFilterMonoid
Csv(input, separator, ('shopId, 'itemId, 'itemName, 'quantity))!
.groupBy('shopId) {!
_.foldLeft('itemName -> 'itemBloom)(bfMonoid.zero) { !
(bf: BF, itemId: String) => bf + itemId !
}!
}!
.map(‘itemBloom -> 'hasSoldBeer) { b: BF => b.contains(“beer").isTrue }!
.map('itemBloom -> 'hasSoldWurst) { b: BF => b.contains("wurst").isTrue }!
.discard('itemBloom)!
.write(Tsv(output, writeHeader = true))
shopId! hasSoldBeer!hasSoldWurst!
1!! ! ! false!! ! ! true!
2!! ! ! false!! ! ! true!
3!! ! ! false!! ! ! true!
4!! ! ! true! ! ! ! false!
5!! ! ! true! ! ! ! false!
ApproximateBoolean(true,0.9999580954658956)
Why not Set[String]? It would OutOfMemory.](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-120-320.jpg)














![Where did my type-safety go?!
Tsv(in, ('userId1, 'userId2, 'rel))!
.filter('userId1) { uid1: Long => uid1 == 1337 }!
.write(Tsv(out))!
Caused by: cascading.flow.FlowException: local step failed
at cascading.flow.planner.FlowStepJob.blockOnJob(FlowStepJob.java:219)
at cascading.flow.planner.FlowStepJob.start(FlowStepJob.java:149)
at cascading.flow.planner.FlowStepJob.call(FlowStepJob.java:124)
at cascading.flow.planner.FlowStepJob.call(FlowStepJob.java:43)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:744)
Caused by: cascading.pipe.OperatorException: [com.twitter.scalding.C...][com.twitter.scalding.RichPipe.filter(RichPipe.scala:325)] operator Each failed executing operation
at cascading.flow.stream.FilterEachStage.receive(FilterEachStage.java:81)
at cascading.flow.stream.FilterEachStage.receive(FilterEachStage.java:34)
at cascading.flow.stream.SourceStage.map(SourceStage.java:102)
at cascading.flow.stream.SourceStage.call(SourceStage.java:53)
at cascading.flow.stream.SourceStage.call(SourceStage.java:38)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.lang.NumberFormatException: For input string: "bob"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.parseLong(Long.java:631)
at cascading.tuple.coerce.LongCoerce.coerce(LongCoerce.java:50)
at cascading.tuple.coerce.LongCoerce.coerce(LongCoerce.java:29)](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-135-320.jpg)
![Where did my type-safety go?!
Tsv(in, ('userId1, 'userId2, 'rel))!
.filter('userId1) { uid1: Long => uid1 == 1337 }!
.write(Tsv(out))!
Caused by: cascading.flow.FlowException: local step failed
at cascading.flow.planner.FlowStepJob.blockOnJob(FlowStepJob.java:219)
at cascading.flow.planner.FlowStepJob.start(FlowStepJob.java:149)
at cascading.flow.planner.FlowStepJob.call(FlowStepJob.java:124)
at cascading.flow.planner.FlowStepJob.call(FlowStepJob.java:43)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:744)
Caused by: cascading.pipe.OperatorException: [com.twitter.scalding.C...][com.twitter.scalding.RichPipe.filter(RichPipe.scala:325)] operator Each failed executing operation
at cascading.flow.stream.FilterEachStage.receive(FilterEachStage.java:81)
at cascading.flow.stream.FilterEachStage.receive(FilterEachStage.java:34)
at cascading.flow.stream.SourceStage.map(SourceStage.java:102)
at cascading.flow.stream.SourceStage.call(SourceStage.java:53)
at cascading.flow.stream.SourceStage.call(SourceStage.java:38)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.lang.NumberFormatException: For input string: "bob"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.parseLong(Long.java:631)
at cascading.tuple.coerce.LongCoerce.coerce(LongCoerce.java:50)
at cascading.tuple.coerce.LongCoerce.coerce(LongCoerce.java:29)
“oh, right… We
changed that file to be
user names, not ids…”](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-136-320.jpg)




)!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-141-320.jpg)
)!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!
Must give Type to
each Field](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-142-320.jpg)
)!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!
import TDsl._!
!
TypedCsv[(String, String, Int)](in, ('user1, 'user2, 'rel))!
.filter { _._1 == "bob" }!
.write(TypedTsv(out))!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-143-320.jpg)
)!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!
import TDsl._!
!
TypedCsv[(String, String, Int)](in, ('user1, 'user2, 'rel))!
.filter { _._1 == "bob" }!
.write(TypedTsv(out))!
Tuple arity: 2 Tuple arity: 3](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-144-320.jpg)
![TypedAPI’s
Tsv(in, ('userId1, 'userId2, 'rel))!
.filter('userId1) { rel: Long => rel == 1337 }!
.write(Tsv(out))!
Caused by: java.lang.IllegalArgumentException:
num of types must equal number of fields: [{3}:'user1', 'user2', 'rel'], found: 2
at cascading.scheme.util.DelimitedParser.reset(DelimitedParser.java:176)
TypedCsv[(String, String)](in, ('user1, 'user2, 'rel))!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!
import TDsl._!
!
TypedCsv[(String, String, Int)](in, ('user1, 'user2, 'rel))!
.filter { _._1 == "bob" }!
.write(TypedTsv(out))!
Tuple arity: 2 Tuple arity: 3](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-145-320.jpg)
![TypedAPI’s
Tsv(in, ('userId1, 'userId2, 'rel))!
.filter('userId1) { rel: Long => rel == 1337 }!
.write(Tsv(out))!
Caused by: java.lang.IllegalArgumentException:
num of types must equal number of fields: [{3}:'user1', 'user2', 'rel'], found: 2
at cascading.scheme.util.DelimitedParser.reset(DelimitedParser.java:176)
TypedCsv[(String, String)](in, ('user1, 'user2, 'rel))!
.filter { _._1 === "bob" }!
.write(TypedTsv(out))!
import TDsl._!
!
TypedCsv[(String, String, Int)](in, ('user1, 'user2, 'rel))!
.filter { _._1 == "bob" }!
.write(TypedTsv(out))!
Tuple arity: 2 Tuple arity: 3
“planing-time” exception](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-146-320.jpg)




![TypedAPI’s
Tsv(in, ('userId1, 'userId2, 'rel))!
.filter('userId1) { rel: Long => rel == 1337 }!
.write(Tsv(out))!
// … with Relationships {!
import TDsl._!
!
userRelationships(date) !
.filter { p: Person => p.name == ”bob" }!
.write(TypedTsv(out))!
!
}
TypedPipe[Person]](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-151-320.jpg)
![Typed Joins
case class UserName(id: Long, handle: String)!
case class UserFavs(byUser: Long, favs: List[Long])!
case class UserTweets(byUser: Long, tweets: List[Long])!
!
def users: TypedSource[UserName]!
def favs: TypedSource[UserFavs]!
def tweets: TypedSource[UserTweets]!
!
def output: TypedSink[(UserName, UserFavs, UserTweets)]!
!
users.groupBy(_.id)!
.join(favs.groupBy(_.byUser))!
.join(tweets.groupBy(_.byUser))!
.map { case (uid, ((user, favs), tweets)) =>!
(user, favs, tweets)!
} !
.write(output)!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-152-320.jpg)
![Typed Joins
case class UserName(id: Long, handle: String)!
case class UserFavs(byUser: Long, favs: List[Long])!
case class UserTweets(byUser: Long, tweets: List[Long])!
!
def users: TypedSource[UserName]!
def favs: TypedSource[UserFavs]!
def tweets: TypedSource[UserTweets]!
!
def output: TypedSink[(UserName, UserFavs, UserTweets)]!
!
users.groupBy(_.id)!
.join(favs.groupBy(_.byUser))!
.join(tweets.groupBy(_.byUser))!
.map { case (uid, ((user, favs), tweets)) =>!
(user, favs, tweets)!
} !
.write(output)!](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-153-320.jpg)
![Typed Joins
case class UserName(id: Long, handle: String)!
case class UserFavs(byUser: Long, favs: List[Long])!
case class UserTweets(byUser: Long, tweets: List[Long])!
!
def users: TypedSource[UserName]!
def favs: TypedSource[UserFavs]!
def tweets: TypedSource[UserTweets]!
!
def output: TypedSink[(UserName, UserFavs, UserTweets)]!
!
users.groupBy(_.id)!
.join(favs.groupBy(_.byUser))!
.join(tweets.groupBy(_.byUser))!
.map { case (uid, ((user, favs), tweets)) =>!
(user, favs, tweets)!
} !
.write(output)!
3-way-merge
in 1 MR step](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-154-320.jpg)






) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-162-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-163-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-164-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-165-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-166-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-167-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.run!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-168-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.runHadoop!
.finish!
}!
!
}!
<3 Testing](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-169-320.jpg)
) { out =>!
out.toList should contain ("kapi" -> 3)!
}!
.runHadoop!
.finish!
}!
!
}!
<3 Testing
run || runHadoop](https://image.slidesharecdn.com/scalding-notsobasics-scaladays-2014-140619051932-phpapp02/85/Scalding-the-not-so-basics-ScalaDays-2014-170-320.jpg)

















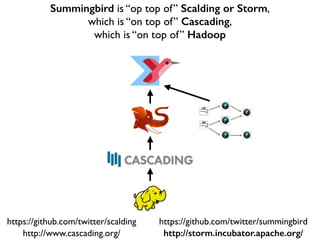
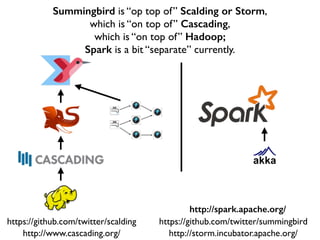
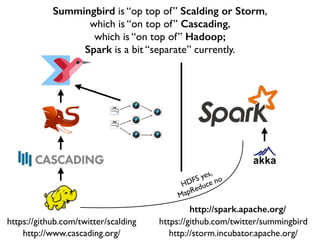
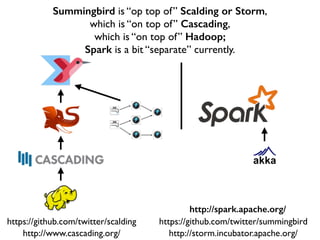
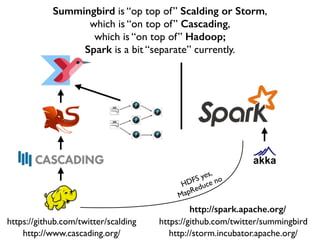
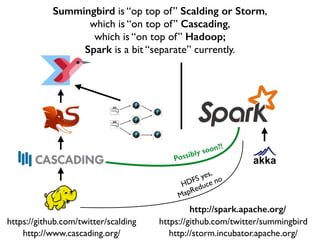
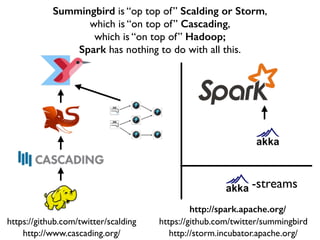
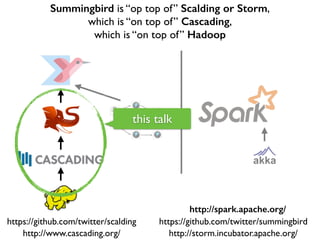
This document discusses various big data technologies and how they relate to each other. It explains that Summingbird is built on top of Scalding and Storm, which are built on top of Cascading, which is built on top of Hadoop. It also discusses how Spark relates and compares to these other technologies.









































![[Tokyo Scala User Group] Akka Streams & Reactive Streams (0.7)](https://cdn.slidesharecdn.com/ss_thumbnails/2014-akka-streams-tokyo-140914201812-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[Japanese] How Reactive Streams and Akka Streams change the JVM Ecosystem @ R...](https://cdn.slidesharecdn.com/ss_thumbnails/2016-tokyo-akka-streams-reactive-streams-160208101926-thumbnail.jpg?width=640&height=640&fit=bounds)

























