Apache Drill with Oracle, Hive and HBase
•
3 likes•1,073 views

This document provides instructions on how to install and configure Apache Drill to connect to various data sources like Oracle, Hive, and HBase. It describes how to use Drill's storage plugins to query data from these sources and also combine data from multiple sources using Drill queries. Examples of queries on each data source and combining data sources are also provided.

Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to Apache Drill with Oracle, Hive and HBase
Similar to Apache Drill with Oracle, Hive and HBase (20)
More from Nag Arvind Gudiseva
More from Nag Arvind Gudiseva (13)
Recently uploaded
Recently uploaded (20)
Apache Drill with Oracle, Hive and HBase
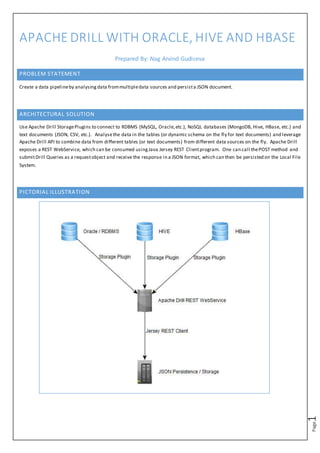
- 1. Page1 APACHE DRILL WITH ORACLE, HIVE AND HBASE Prepared By: Nag Arvind Gudiseva PROBLEM STATEMENT Create a data pipelineby analysing data frommultipledata sources and persista JSON document. ARCHITECTURAL SOLUTION Use Apache Drill StoragePlugins to connect to RDBMS (MySQL, Oracle,etc.), NoSQL databases (MongoDB, Hive, HBase, etc.) and text documents (JSON, CSV, etc.). Analysethe data in the tables (or dynamic schema on the fly for text documents) and leverage Apache Drill API to combine data from different tables (or text documents) from different data sources on the fly. Apache Drill exposes a REST WebService, which can be consumed usingJava Jersey REST Clientprogram. One can call thePOST method and submitDrill Queries as a requestobject and receive the response in a JSON format, which can then be persisted on the Local File System. PICTORIAL ILLUSTRATION
- 2. Page2 INSTALLATION STEPS ON UBUNTU 14.04 VM 1. Download Apache Drill usingwget command wget http://mirror.symnds.com/software/Apache/drill/drill-1.4.0/apache-drill-1.4.0.tar.gz 2. Untar and extract tar -xvzf apache-drill-1.4.0.tar.gz 3. Move the folder to a preferred location sudo mv apache-drill-1.4.0 /usr/local/apache-drill 4. Install Zookeeper: a. Download the stableversion (zookeeper-3.4.6.tar.gz) from http://hadoop.apache.org/zookeeper/releases.html b. Untar and move the folder to a preferred location c. Rename zoo_sample.cfg as zoo.cfg STARTING DRILL a. EMBEDDED MODE (with SqlLine) <DRILL_HOME>/bin/sqlline -u jdbc:drill:zk=local (OR) ./bin/drill-embedded b. DISTRIBUTED MODE (Start ZooKeeper and Drill Bit) <ZOOKEEPER_HOME>/bin/zkServer.sh start < ZOOKEEPER _HOME>/bin/zkServer.sh status (AND) <DRILL_HOME>/bin/drillbit.sh start <DRILL_HOME>/bin/drillbit.sh status STOPPING DRILL (AND ZOOKEEPER) a. EMBEDDED MODE (with SqlLine) 0: jdbc:drill:zk=local>!quit
- 3. Page3 b. DISTRIBUTED MODE (Stop Drill Bitand ZooKeeper) <DRILL_HOME>/bin/drillbit.sh stop <DRILL_HOME>/bin/drillbit.sh status (AND) < ZOOKEEPER _HOME>/bin/zkServer.sh stop < ZOOKEEPER _HOME>/bin/zkServer.sh status JAR DEFAULT QUERIES REFERENCE: <DRILL_HOME>/jars/3rdparty/foodmart-data-json-0.4.jar 0: jdbc:drill:zk=local>showdatabases; 0: jdbc:drill:zk=local>selectemployee_id, first_name,last_name,position_id,salary FROMcp.`employee.json` where salary > 30000; 0: jdbc:drill:zk=local>selectemployee_id, first_name,last_name,position_id,salary FROMcp.`employee.json` where salary > 30000 and position_id=2; 0: jdbc:drill:zk=local>selectemp.employee_id, emp.first_name,emp.salary,emp.department_id FROM cp.`employee.json` emp where emp.salary <40000 and emp.salary>21000; 0: jdbc:drill:zk=local>selectemp.employee_id, emp.first_name,emp.salary,emp.department_id,dept.department_description FROM cp.`employee.json` emp , cp.`department.json` dept where emp.salary <40000 and emp.salary>21000 and emp.department_id = dept.department_id; JSON SAMPLE QUERIES SELECT * from dfs.`/home/gudiseva/arvind/zips.json` LIMIT10; CSV SAMPLE QUERIES select * FROM dfs.`/home/gudiseva/arvind/sample.csv`; select columns[0] as id,columns[1] name, columns[2] as weight, columns[3] as height FROM dfs.`/home/gudiseva/arvind/sample.csv`; CREATING VIEW BY QUERYING MULTIPLE DATA SOURCES CREATE or REPLACE view dfs.tmp.MULTI_VIEW as selectemp.employee_id, phy.columns[1] as Name ,dept.department_description,phy.columns[2] as Weight, phy.columns[3] as Height FROM cp.`employee.json` emp , cp.`department.json` dept, dfs.`/home/gudiseva/arvind/sample.csv` phy where CAST(emp.employee_id AS INT) = CAST(phy.columns[0] AS INT) and emp.department_id = dept.department_id; SELECT * FROM dfs.tmp.MULTI_VIEW;
- 4. Page4 OPTIMIZATION CONFIGURATIONS <DRILL_HOME>/conf/drill-env.sh DRILL_MAX_DIRECT_MEMORY="1G" DRILL_HEAP="512M" STORAGE PLUGINS MYSQL { "type": "jdbc", "driver": "com.mysql.jdbc.Driver", "url": "jdbc:mysql://localhost", "username": "root", "password":"root", "enabled": true } select * from mysql.userdb.`employee`; ORACLE { "type": "jdbc", "driver": "oracle.jdbc.OracleDriver", "url": "jdbc:oracle:thin:MY_APPL/mayura_123@dbs-nprd2-vm-004.mayura.com:1523/N2S004I", "username": "MY_APPL", "password":"mayura_123", "enabled": true } select * from oracle.MY_APPL.`emp`; HIVE { "type": "hive", "enabled": false, "configProps":{ "hive.metastore.uris": "thrift://localhost:10000", "javax.jdo.option.ConnectionURL": "jdbc:derby://localhost:1527/metastore_db;create=true", "hive.metastore.warehouse.dir": "/user/hive/warehouse",
- 5. Page5 "fs.default.name": "file:///", "hive.metastore.sasl.enabled": "false" } } select * from hive.arvind.`employee`; NOTE: HIVE SERVER should be started $ hive --servicehiveserver --verbose [hive shell will not work when Hive Server is started] MONGODB { "type": "mongo", "connection": "mongodb://first_name:last_name@ds048537.mongolab.com:48537/m101", "enabled": true } select `_id`, `value` from mongo.m101.`storm`; HBASE { "type": "hbase", "config": { "hbase.zookeeper.quorum": "localhost", "hbase.zookeeper.property.clientPort": "2181" }, "size.calculator.enabled":false, "enabled": true } SELECT CONVERT_FROM(row_key, 'UTF8') AS empid, CONVERT_FROM(emp.personal_data.city, 'UTF8') AS city, CONVERT_FROM(emp.personal_data.name, 'UTF8') AS name, CONVERT_FROM(emp.professional_data.designation, 'UTF8') AS designation, CONVERT_FROM(emp.professional_data.salary,'UTF8') AS salary FROM hbase.`emp`;
- 6. Page6 RELOAD .BASHRC: source~/.bashrc (OR) . ~/.bashrc HBASE SAMPLE QUERIES select * from hbase.`emp`; SELECT CONVERT_FROM(row_key, 'UTF8') AS empid FROM hbase.`emp`; SELECT CONVERT_FROM(row_key, 'UTF8') AS empid, CONVERT_FROM(emp.personal_data.city, 'UTF8') AS city FROM hbase.`emp`; SELECT CONVERT_FROM(emp.personal_data.city, 'UTF8') AS city, CONVERT_FROM(emp.personal_data.name, 'UTF8') As name FROM hbase.`emp`; SELECT CONVERT_FROM(row_key, 'UTF8') AS empid, CONVERT_FROM(emp.p ersonal_data.city, 'UTF8') AS city, CONVERT_FROM(emp.personal_data.name, 'UTF8') As name, CONVERT_FROM(emp.professional_data.designation, 'UTF8') AS designation,CONVERT_FROM(emp.professional_data.salary,'UTF8') As salary FROMhbase.`emp`; ORACLE, HIVE AND HBASE (UNION ALL) QUERIES select id,name, salary frommysql.userdb.`employee` union all selectid,first,salary fromoracle.MY_APPL.`emp`; SELECT EID AS ID, NAME AS NAME, SALARY AS SALARY FROM hive.arvind.`employee` WHERE DESTINATION LIKE '%manager%' UNION ALL SELECT CONVERT_FROM(row_key, 'UTF8') AS ID, CONVERT_FROM(emp.personal_data.name, 'UTF8') AS NAME, CONVERT_TO(emp.professional_data.salary,'UTF8') AS SALARY FROM hbase.`emp` WHERE CONVERT_FROM(emp.professional_data.designation, 'UTF8') LIKE '%manager%'; SELECT EID AS ID, NAME AS NAME, TO_NUMBER(SALARY, '######') AS SALARY FROM hive.arvind.`employee` WHERE DESTINATION LIKE '%manager%' UNION ALL SELECT ID AS ID, FIRST AS NAME, SALARY AS SALARY FROM oracle.MY_APPL.`emp` UNION ALL SELECT CONVERT_FROM(row_key, 'UTF8') AS ID, CONVERT_FROM(emp.personal_data.name, 'UTF8') AS NAME, TO_NUMBER(emp.professional_data.salary,'######') AS SALARY FROM hbase.`emp` WHERE CONVERT_FROM(emp.professional_data.designation, 'UTF8') LIKE '%manager%';
- 7. Page7 DRILL REST WEBSERVICE INTERFACE 1. Install RESTClientExtension in Firefox 2. On Firefox Browser, open the REST Client: chrome://restclient/content/restclient.html 3. Set the Request object: Method: POST URL: http://localhost:8047/query.json Header: Content-Type: application/json Body: { "queryType" : "SQL", "query": "SELECT * from dfs.`/home/gudiseva/arvind/zips.json` LIMIT10" } 4. Response object received: Response Headers: Status Code: 200 OK Content-Length: 1377 Content-Type: application/json Server: Jetty(9.1.5.v20140505) Response Body: { "columns": [ "_id", "city", "loc", "pop", "state" ], "rows" : [ { "_id" : "01001", "state" : "MA", "loc" : "[-72.622739,42.070206]", "pop" : "15338", "city" : "AGAWAM" }, { "_id" : "01002", "state" : "MA", "loc" : "[-72.51565,42.377017]", "pop" : "36963", "city" : "CUSHMAN" } ] }
- 8. Page8 FIGURE ILLUSTRATION OF REST UI CLIENT JAVA SAMPLE PROGRAMS DRILL JDBC API (WITH DRILL JDBC DRIVER) package nag.arvind.gudiseva; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class DrillHiveOracleHBase { public staticvoid main(String[]args) { try {
- 9. Page9 Class.forName("org.apache.drill.jdbc.Driver"); Connection conn=DriverManager.getConnection("jdbc:drill:zk=localhost:2181","",""); Statementstmt =conn.createStatement(); String sql ="SELECTEID AS ID, NAMEAS NAME, TO_NUMBER(SALARY, '######') AS SALARY FROMhive.arvind.`employee` WHERE DESTINATION LIKE'%manager%'"+ "UNION ALL "+ "SELECTID AS ID, FIRSTAS NAME, SALARY AS SALARY FROM oracle.MY_APPL.`emp` "+ "UNION ALL "+ "SELECTCONVERT_FROM(row_key, 'UTF8') AS ID, CONVERT_FROM(emp.personal_data.name, 'UTF8') AS NAME, TO_NUMBER(emp.professional_data.salary, '######') AS SALARY FROM hbase.`emp` WHERE CONVERT_FROM(emp.professional_data.designation,'UTF8') LIKE'%manager%'"; ResultSet rs =stmt.executeQuery(sql); System.out.println("ID"+"t"+ "NAME " +"t" + "SALARY "); System.out.println("__"+"t" + "____ " + "t"+ "______ "); System.out.println("--"+"t" + "---- " +"t" + "------ "); while(rs.next()) { String id =rs.getString("ID"); String name=rs.getString("NAME"); int salary =rs.getInt("SALARY"); System.out.println(id+"t"+name +"t"+salary); } rs.close(); stmt.close(); conn.close(); } catch (ClassNotFoundExceptione) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } } DRILL JDBC JARS: drill-jdbc-all-1.4.0.jar DRILL REST WEBSERVICE (WITH JERSEY REST CLIENT) package web.service.rest; import java.io.FileWriter; import java.io.IOException;
- 10. Page10 import com.sun.jersey.api.client.Client; import com.sun.jersey.api.client.ClientResponse; import com.sun.jersey.api.client.WebResource; import com.sun.jersey.api.client.WebResource.Builder; public class JerseyClientPost{ public staticvoid main(String[]args) { try { Client client= Client.create(); WebResourcewebResource=client.resource("http://localhost:8047/query.json"); String input ="{" + ""queryType": "SQL"" + "," + ""query": "SELECT* from dfs.`/home/gudiseva/arvind/zips.json` LIMIT10"" + "}"; Builder builder =webResource.type("application/json"); ClientResponse response =builder.post(ClientResponse.class, input); if(response.getStatus() !=200) { throw new RuntimeException("Failed: HTTP error code: "+response.getStatus()); } System.out.println("Outputfrom Server .... n"); String output=response.getEntity(String.class); System.out.println(output); try { FileWriterfile=new FileWriter("/tmp/JSON/aix_input.json"); file.write(output); file.flush(); file.close(); } catch (IOException e) { e.printStackTrace(); } } catch (Exception e) { e.printStackTrace(); } }