












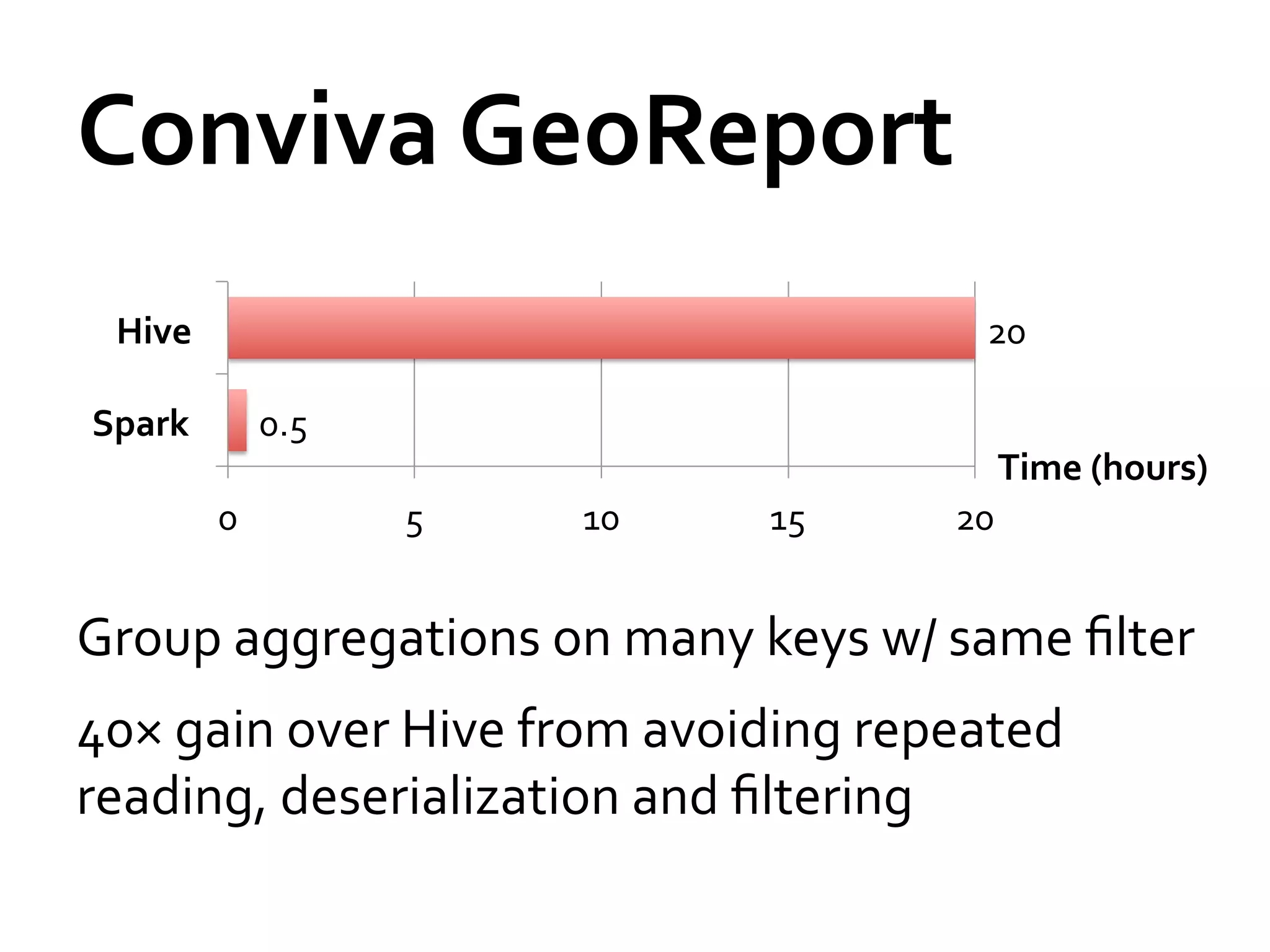


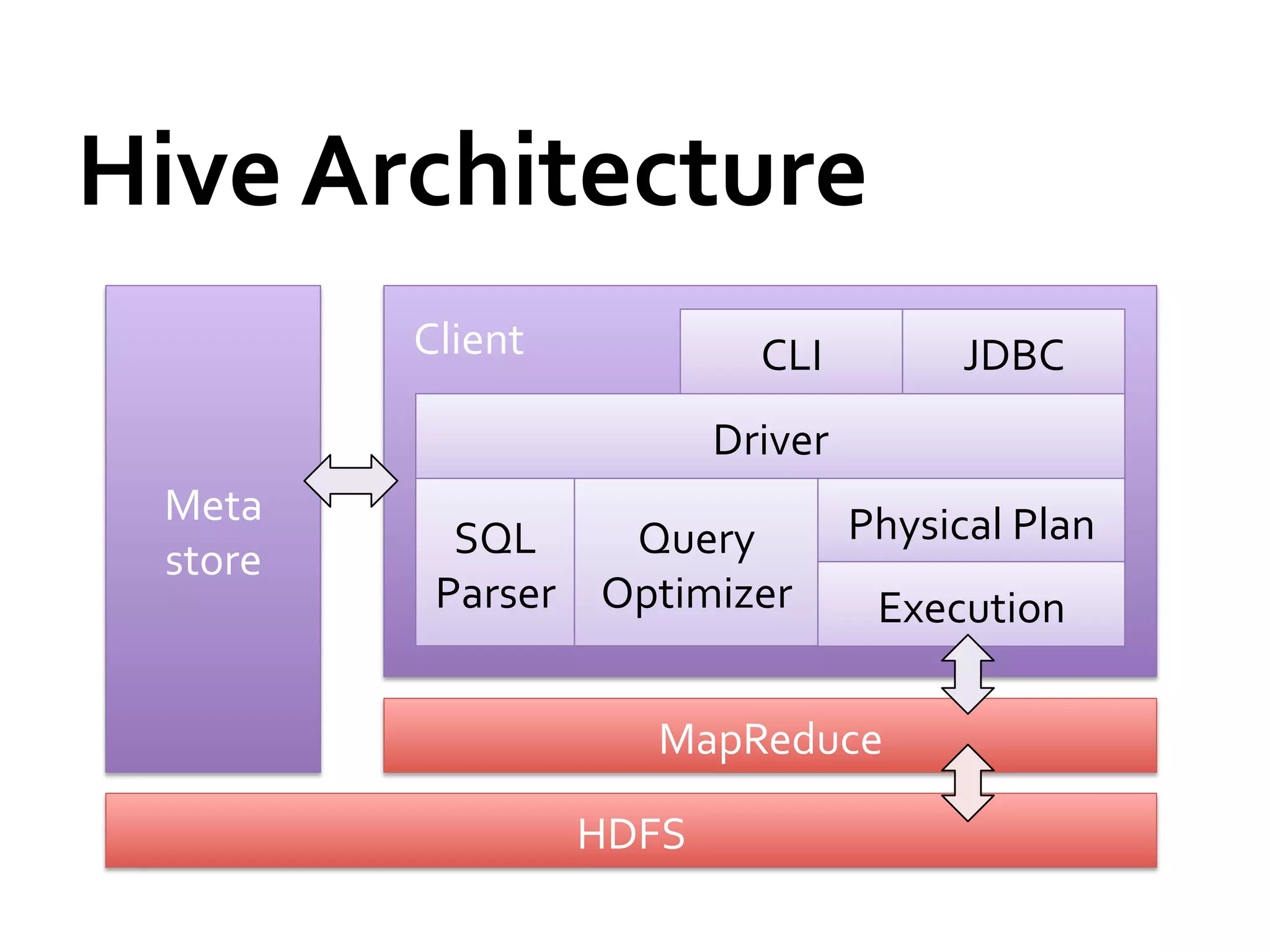
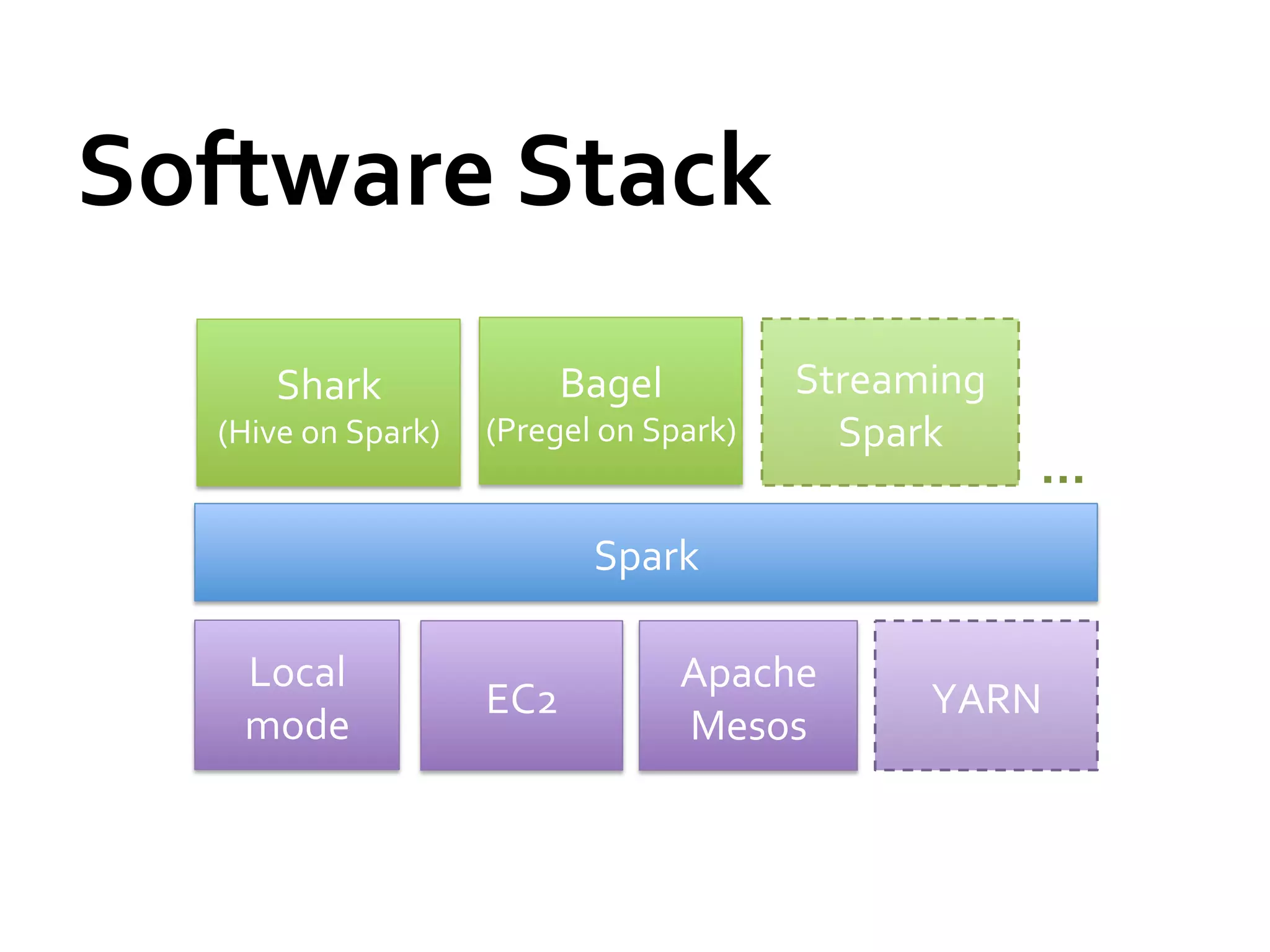
![Shark
Architecture
Client
CLI
JDBC
Driver
Cache
Mgr.
Meta
Physical
Plan
store
SQL
Query
Parser
Optimizer
Execution
Spark
HDFS
[Engle
et
al,
SIGMOD
2012]](https://image.slidesharecdn.com/sparkandshark-120620130508-phpapp01/75/Spark-and-shark-23-2048.jpg)
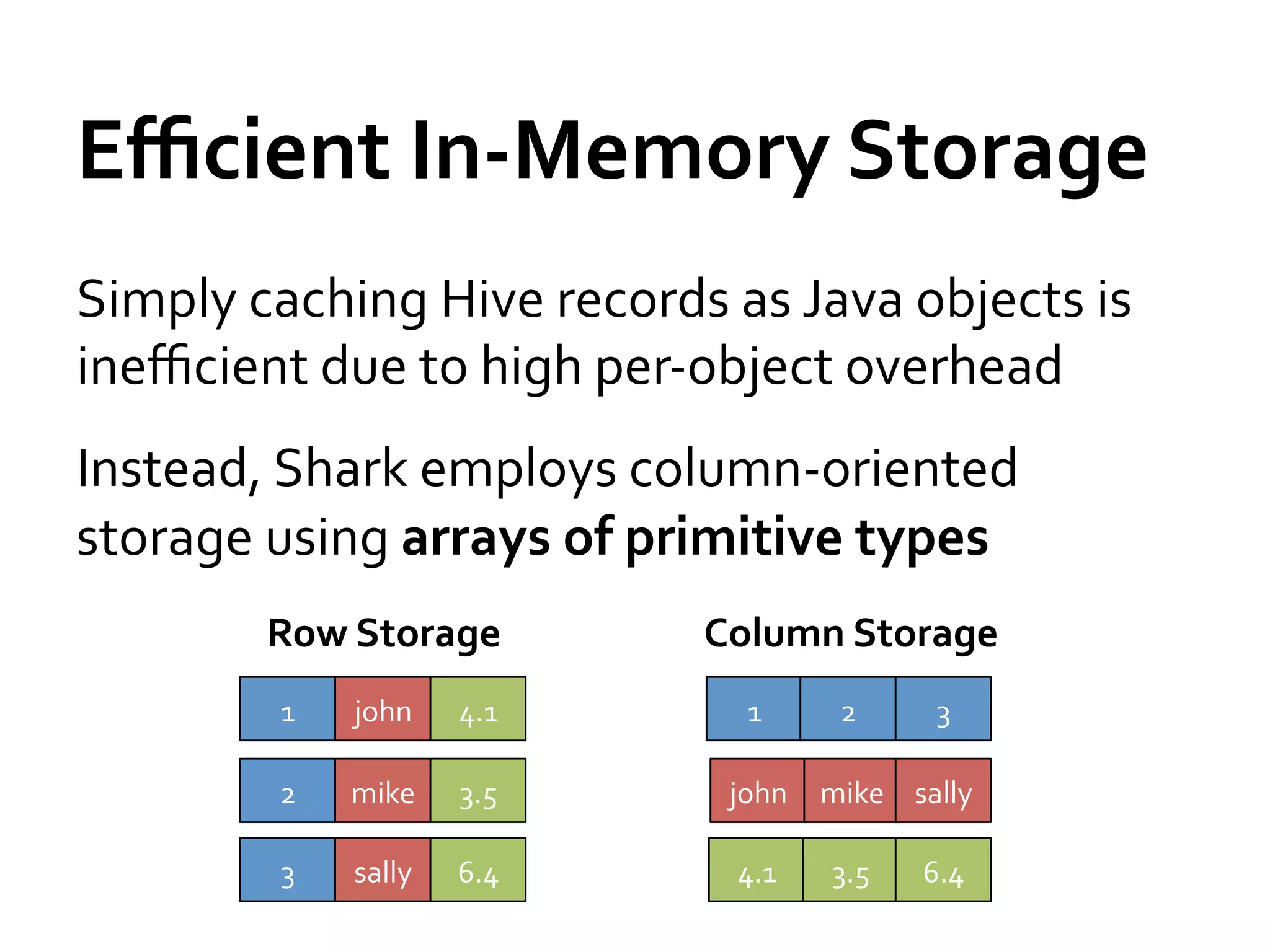




![Streaming
Spark
Extends
Spark
to
perform
streaming
computations
Runs
as
a
series
of
small
(~1
s)
batch
jobs,
keeping
state
in
memory
as
fault-‐tolerant
RDDs
Intermix
seamlessly
with
batch
and
ad-‐hoc
queries
map
reduceByWindow
tweetStream T=1
.flatMap(_.toLower.split)
.map(word => (word, 1))
.reduceByWindow(5, _ + _)
T=2
…
[Zaharia
et
al,
HotCloud
2012]](https://image.slidesharecdn.com/sparkandshark-120620130508-phpapp01/75/Spark-and-shark-31-2048.jpg)
![Streaming
Spark
Extends
Spark
to
perform
streaming
computations
Runs
as
a
series
of
small
(~1
s)
batch
jobs,
keeping
state
in
memory
as
fault-‐tolerant
RDDs
Intermix
seamlessly
with
batch
and
ad-‐hoc
queries
map
reduceByWindow
tweetStream T=1
.flatMap(_.toLower.split)
Result:
can
process
42
million
records/second
.map(word => (word, 1))
(4
GB/s)
on
100
nodes
at
sub-‐second
latency
.reduceByWindow(5, _ + _)
T=2
…
[Zaharia
et
al,
HotCloud
2012]](https://image.slidesharecdn.com/sparkandshark-120620130508-phpapp01/75/Spark-and-shark-32-2048.jpg)
![Streaming
Spark
Extends
Spark
to
perform
streaming
computations
Runs
as
a
series
of
small
(~1
s)
batch
jobs,
keeping
state
in
memory
as
fault-‐tolerant
RDDs
Intermix
seamlessly
with
batch
and
ad-‐hoc
queries
map
reduceByWindow
tweetStream T=1
.flatMap(_.toLower.split)
.map(word => (word, 1))Alpha
coming
this
summer
.reduceByWindow(5, _ + _)
T=2
…
[Zaharia
et
al,
HotCloud
2012]](https://image.slidesharecdn.com/sparkandshark-120620130508-phpapp01/75/Spark-and-shark-33-2048.jpg)



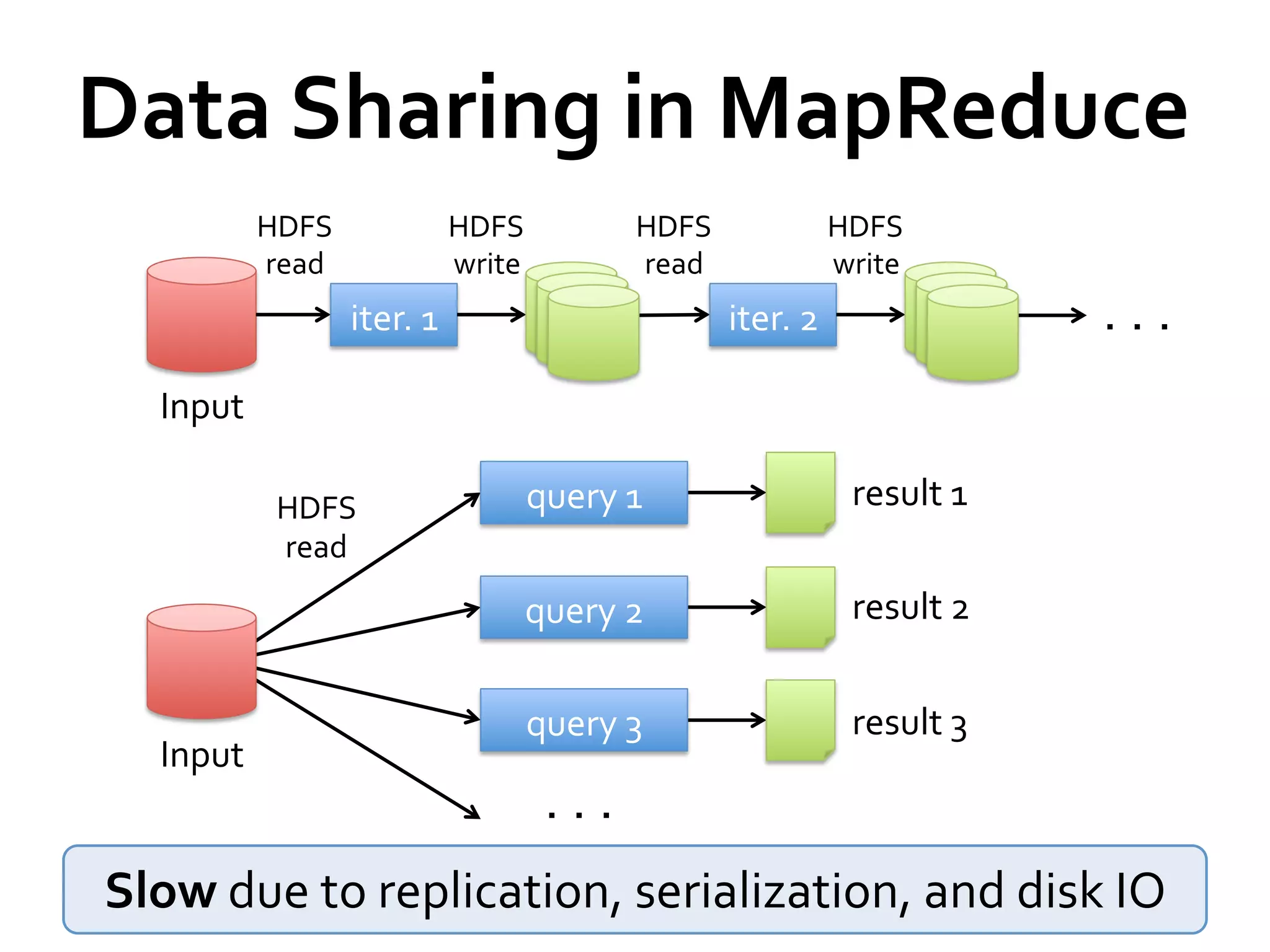
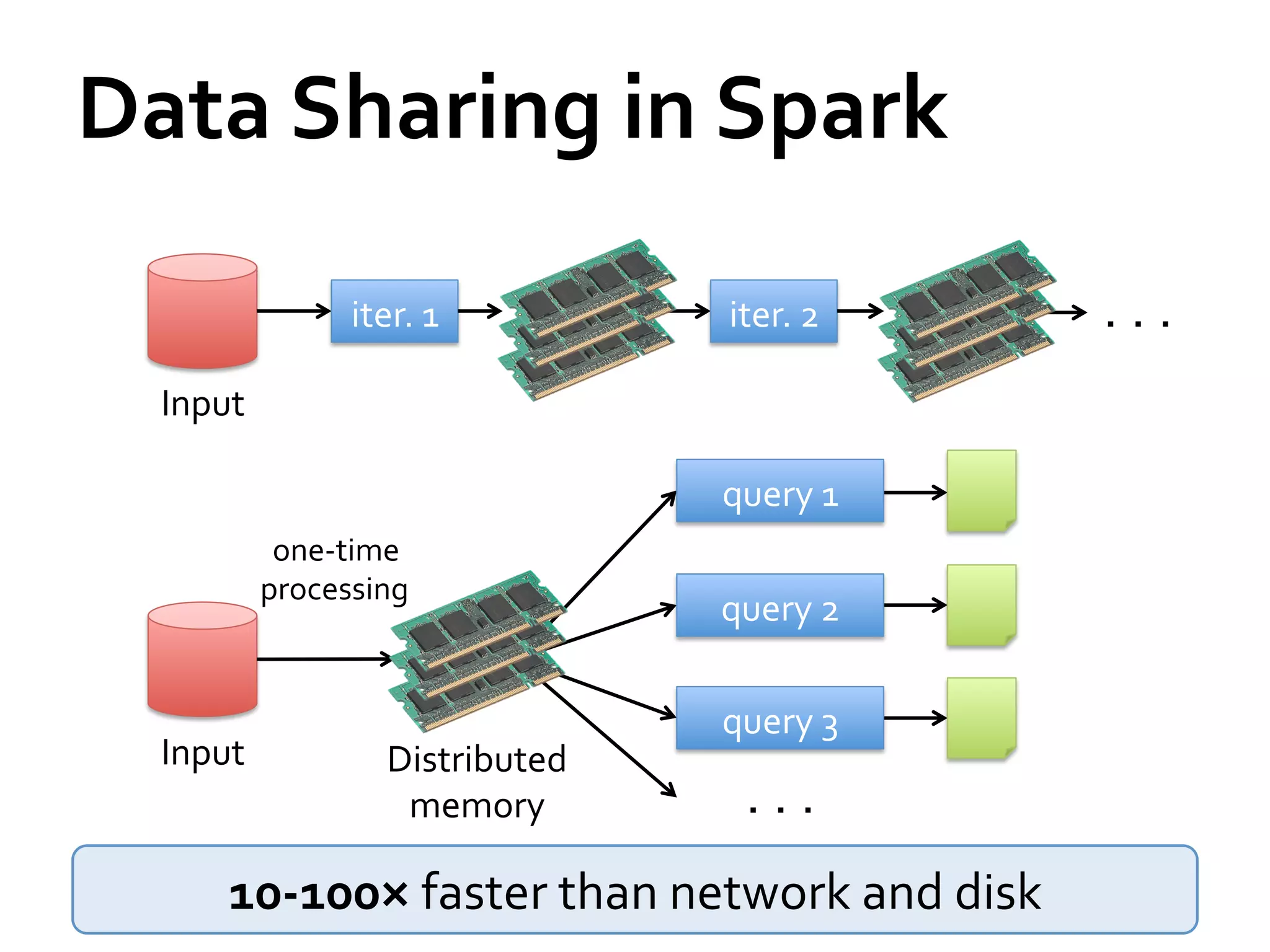
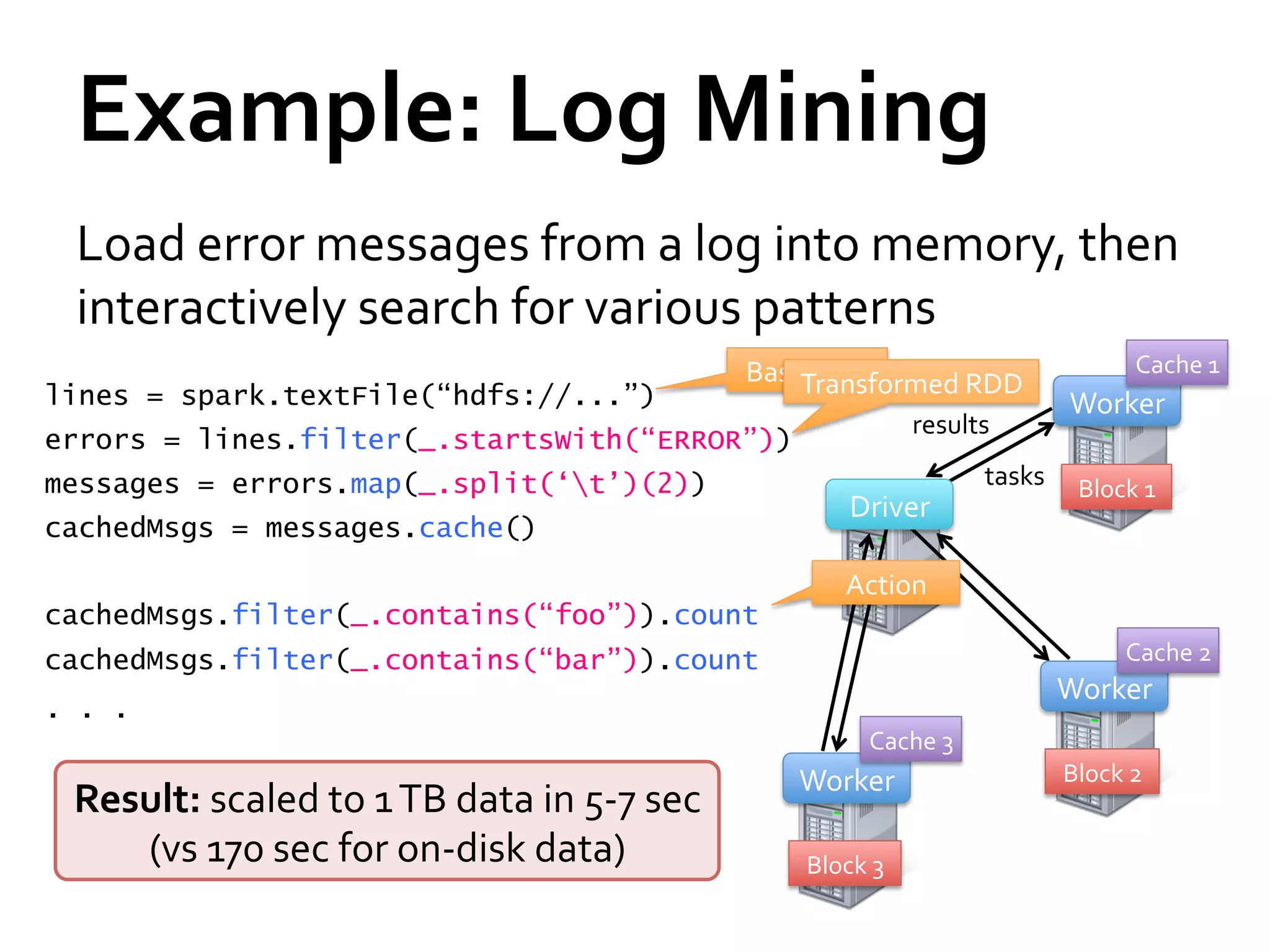
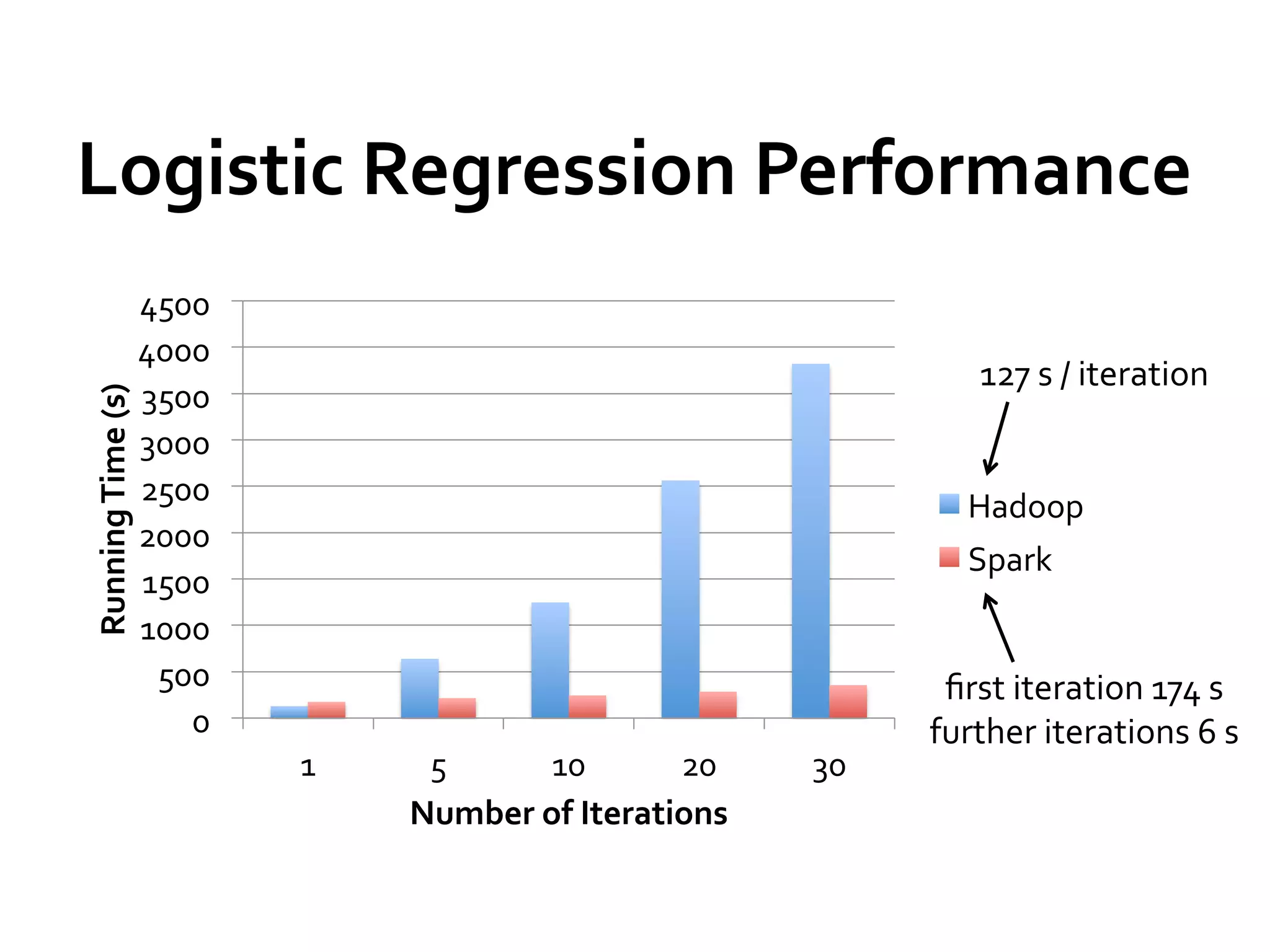
Spark is a fast and general engine for large-scale data processing. It provides an interface called resilient distributed datasets (RDDs) that allow data to be distributed in memory across clusters and manipulated using parallel operations. Shark is a system built on Spark that allows running SQL queries over large datasets using Spark's speed and generality. The document discusses Spark and Shark's performance advantages over Hadoop for iterative and interactive applications.









































































































