Downloaded 71 times







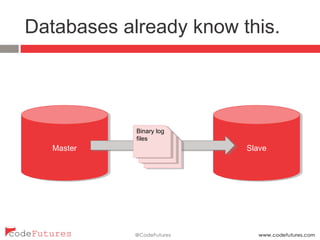


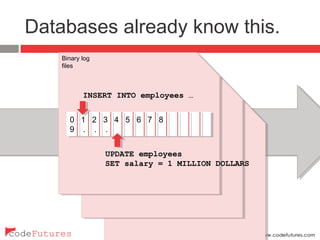
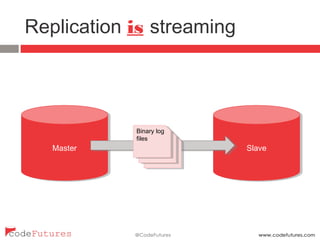
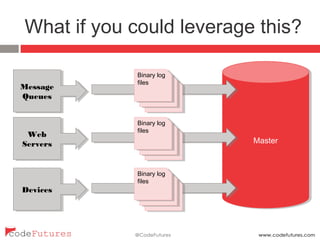
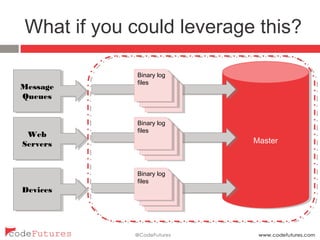
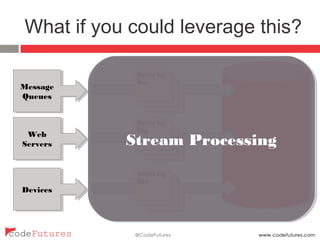

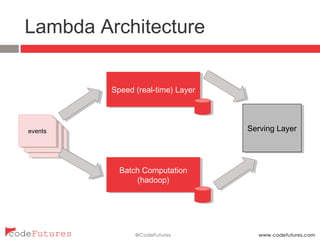
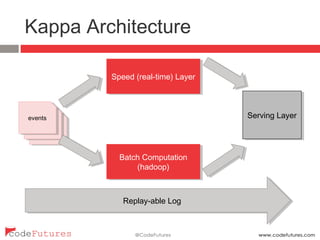












This document provides an overview of stream processing technologies. It defines stream processing as processing events in the order they occur. Common patterns like lambda architecture and kappa architecture are described. Specific stream processing technologies are then outlined, including Apache Storm, Apache Kafka, Apache Samza, Apache Spark Streaming, LinkedIn Databus, AgilData and Hailstorm. The document promotes stream processing by noting how databases already process transactions in order through replication logs.




















































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)













![Complex Er[jl]ang Processing with StreamBase](https://cdn.slidesharecdn.com/ss_thumbnails/complexerjlangprocessing-pptx-110611095407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























