Download as PDF, PPTX






![{
"_id" : ObjectId("4dcd3ebc9278000000005158"),
"timestamp" : ISODate("2011-05-13T14:22:46.777Z"),
"binary" : BinData(0,""),
"string" : "abc",
"number" : 3,
"subobj" : {"subA": 1, "subB": 2 },
"array" : [1, 2, 3],
"dbref" : [_id1, _id2, _id3]
padding
}](https://image.slidesharecdn.com/mongohadoopstory-110713045304-phpapp01/85/MongoDB-Hadoop-Flexible-Hourly-Batch-Processing-Model-6-320.jpg)
![{ db.coll.find({"string": "abc"});
db.coll.find({ "string" : /^a.*$/i });
"_id" : ObjectId("4dcd3ebc9278000000005158"),
"timestamp" : ISODate("2011-05-13T14:22:46.777Z"),
db.coll.find({"subobj.subA": 1});
db.coll.find({"subobj.subB": {$exists: true} });
"binary" : BinData(0,""),
"string" : "abc", db.coll.find({"number": 3});
db.coll.find({"number": {$gt: 1}});
"number" : 3,
"subobj" : {"subA": 1, "subB": 2 },
"array" : [1, 2, 3],
db.coll.find({"array": {$all:[1, 2]} });
"dbref" : [_id1, _id2, _id3]
db.coll.find({"array": {$in:[2, 4, 6]} });
padding
}](https://image.slidesharecdn.com/mongohadoopstory-110713045304-phpapp01/85/MongoDB-Hadoop-Flexible-Hourly-Batch-Processing-Model-7-320.jpg)
![{
"_id" : ObjectId("4dcd3ebc9278000000005158"),
"timestamp" : ISODate("2011-05-13T14:22:46.777Z"),
{ $set : {"string": "def"} }
"binary" : BinData(0,""), { $inc : {"number": 1} }
"string" : "def",
{ $pull : {"subobj": {"subB": 2 } } }
"number" : 4,
"subobj" : {"subA": 1, "subB": 2 },
"array" : [1, 2, 3, 4, 5, 6],
"dbref"$addToSet : { "array" : { $each : [ 4 , 5 , 6 ] } } }
{ : [_id1, _id2, _id3]
"newkey" : "In-place"
} { $set : {"newkey": "In-place"} }](https://image.slidesharecdn.com/mongohadoopstory-110713045304-phpapp01/85/MongoDB-Hadoop-Flexible-Hourly-Batch-Processing-Model-8-320.jpg)















![[2011-07-01 12:01:48,447]](https://image.slidesharecdn.com/mongohadoopstory-110713045304-phpapp01/85/MongoDB-Hadoop-Flexible-Hourly-Batch-Processing-Model-35-320.jpg)


![m = function(){
this.tags.forEach{
function(z) {
emit(z, {count: 1});
}
};
};
r = function(key, values) {
var total=0;
for (i=0, i<values.length, i++)
total += values[i].count;
return { count : total };
}
res=db.things.mapReduce(m,!r);
# finalize](https://image.slidesharecdn.com/mongohadoopstory-110713045304-phpapp01/85/MongoDB-Hadoop-Flexible-Hourly-Batch-Processing-Model-42-320.jpg)
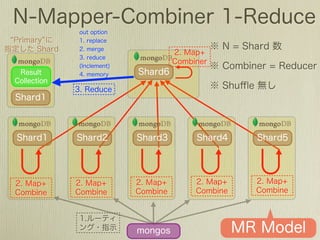






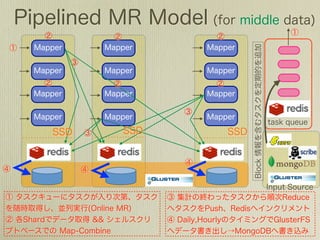





The document describes how to use Gawk to perform data aggregation from log files on Hadoop by having Gawk act as both the mapper and reducer to incrementally count user actions and output the results. Specific user actions are matched and counted using operations like incrby and hincrby and the results are grouped by user ID and output to be consumed by another system. Gawk is able to perform the entire MapReduce job internally without requiring Hadoop.






























![[H3 2012] 내컴에선 잘되던데? - vagrant로 서버와 동일한 개발환경 꾸미기](https://cdn.slidesharecdn.com/ss_thumbnails/c6-vagrantshare-121107074434-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































































