Downloaded 316 times








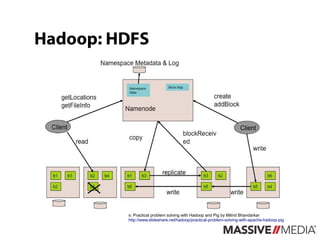

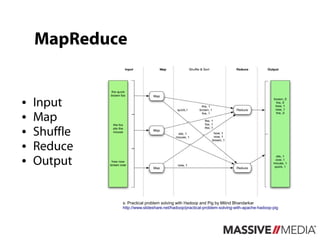













Hadoop Pig provides a high-level language called Pig Latin for analyzing large datasets in Hadoop. Pig Latin allows users to express data analysis jobs as sequences of operations like filtering, grouping, joining and ordering data. This simplifies programming with Hadoop by avoiding the need to write Java MapReduce code directly. Pig jobs are compiled into sequences of MapReduce jobs that operate in parallel on large datasets distributed across a Hadoop cluster.







![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































