Downloaded 76 times
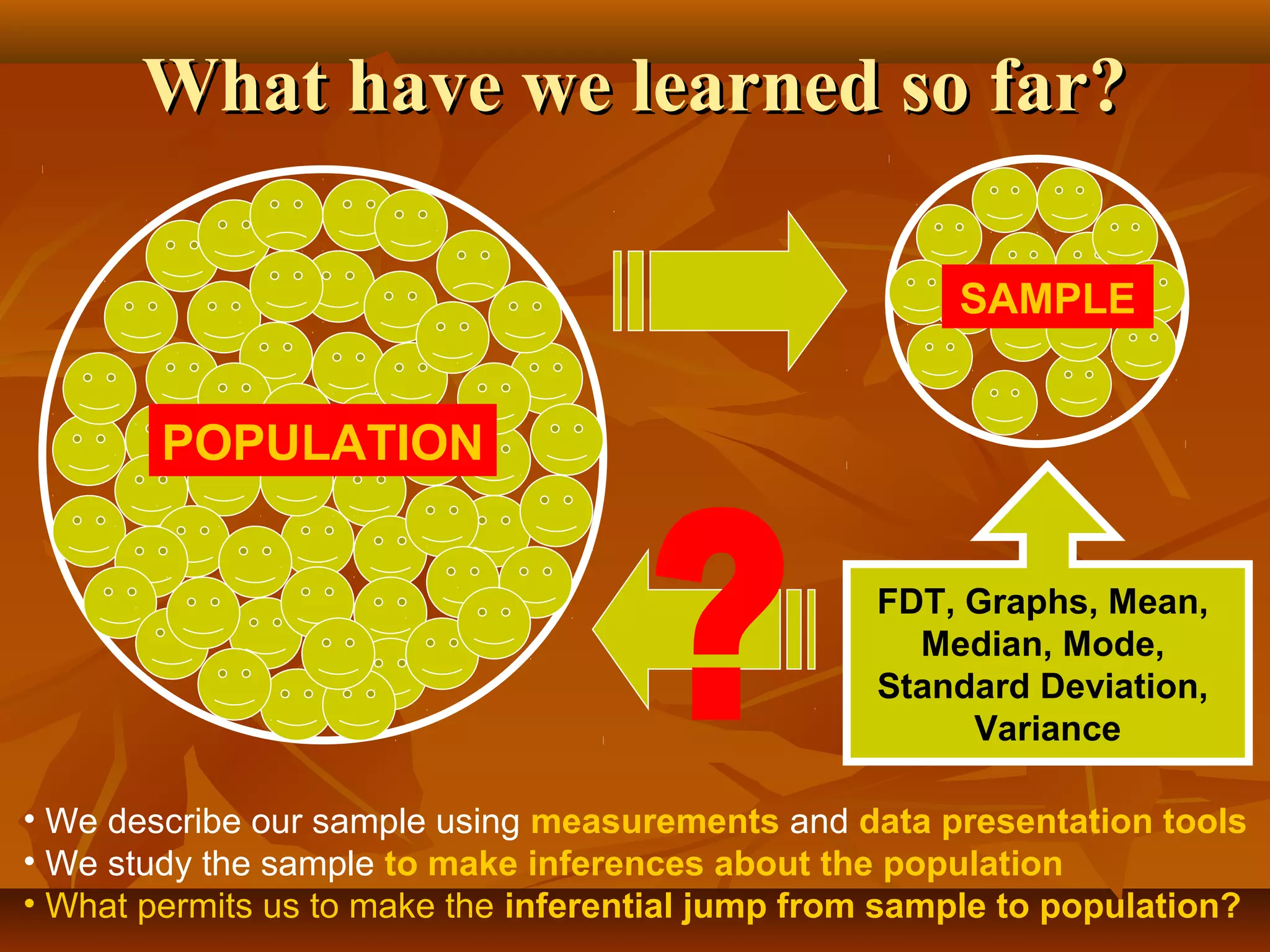
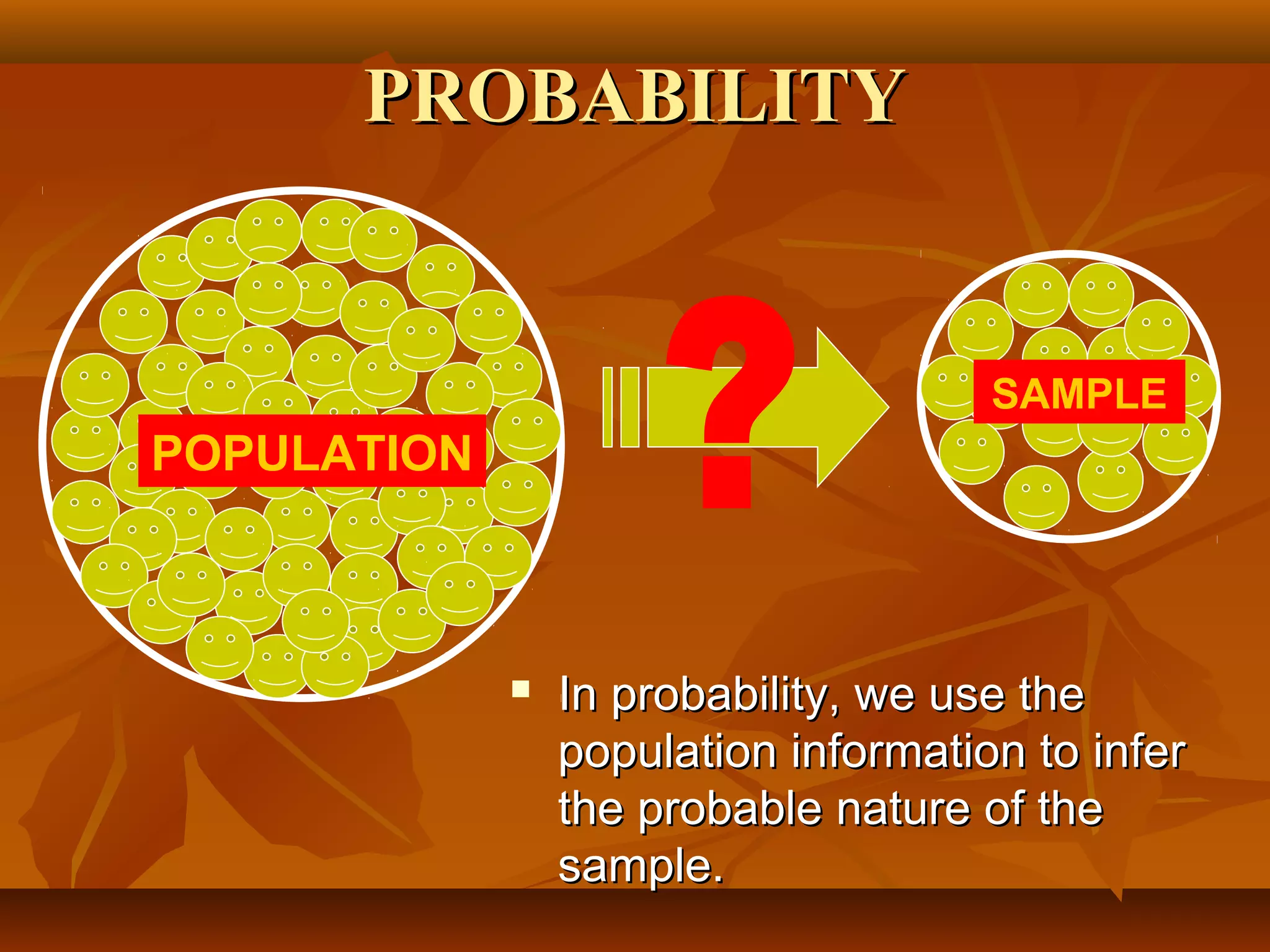






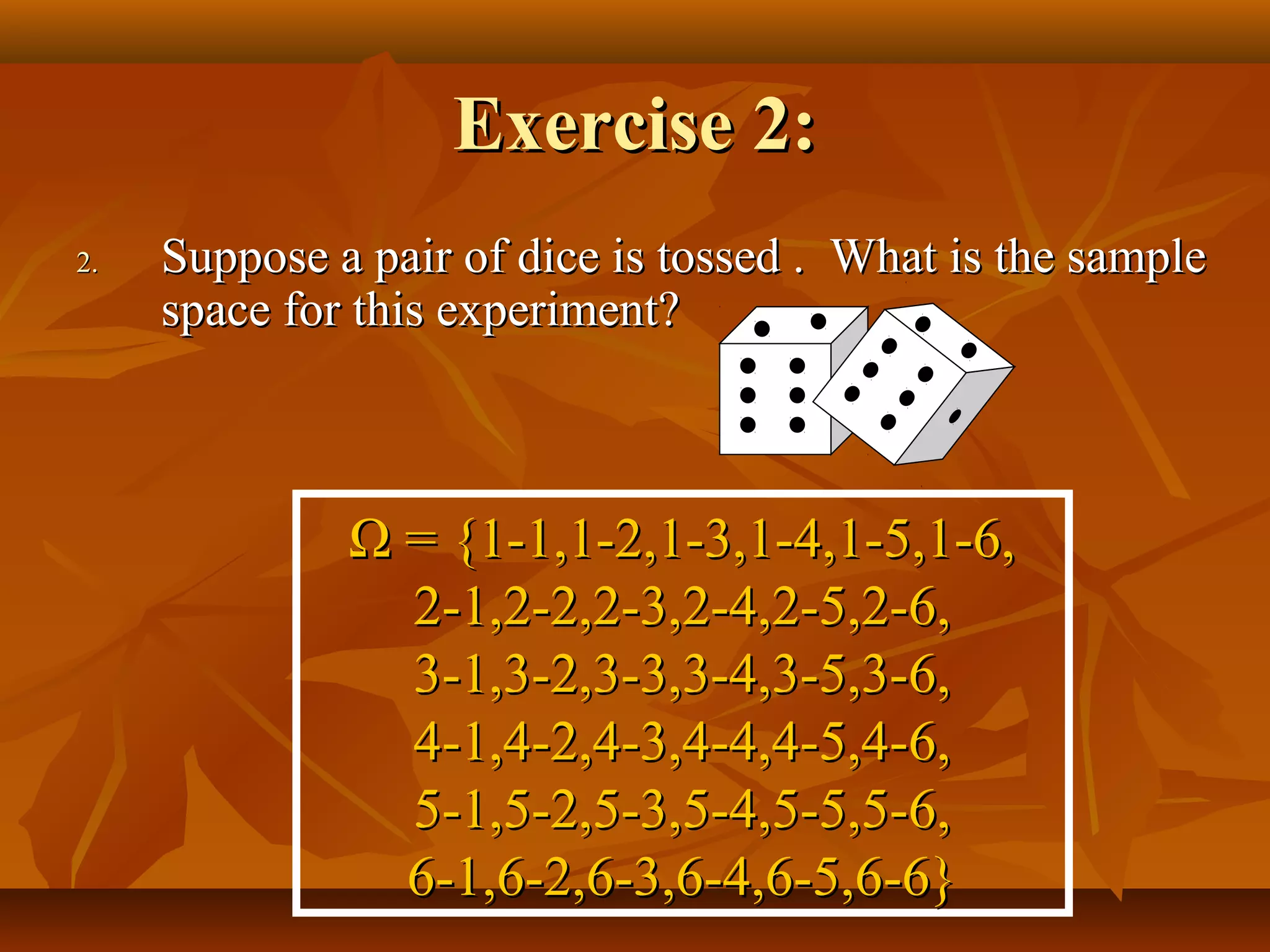



















This document discusses key concepts in probability and statistics such as population, sample, random experiments, sample space, events, and types of events. It provides examples and exercises to illustrate these concepts. Specifically, it defines a random experiment as a process that can be repeated under similar conditions leading to well-defined but unpredictable outcomes. The sample space represents all possible outcomes, while an event is a subset of outcomes of interest. Events can be elementary, impossible, or sure depending on whether they consist of one, no, or all possible outcomes.


















































![Probability[1]](https://cdn.slidesharecdn.com/ss_thumbnails/probability1-110816105858-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




































