Download as PDF, PPTX

![Flexibility versus Performance
4Christoforos Kachris, www.inaccel.com, 2017, #EUres8
CPU: High flexibility, lower efficiency Accelerators: High throughput, higher efficiency
GPUs and FPGAs can provide massive parallelism and higher efficiency
than CPUs for certain categories of applications
[Source: Amazon AWS f1]](https://image.slidesharecdn.com/l28christoforoskachris-171031223004/75/Hardware-Acceleration-of-Apache-Spark-on-Energy-Efficient-FPGAs-with-Christoforos-Kachris-4-2048.jpg)
![Hardware Acceleration
5Christoforos Kachris, www.inaccel.com, 2017, #EUres8
module fi lter1 ( clock, rst, st rm_in, out)
for (i =0; i<N UMUNITS ; i=i+1 )
always @(posed ge cloc k)
intege r i,j; //index for lo ops
tm p_kerne l[j] = k[i*OFF SETX];
FPGA handles compute-
intensive, deeply pipelined,
hardware-accelerated
operations
CPU handles the rest
application
[Source: Amazon AWS f1]](https://image.slidesharecdn.com/l28christoforoskachris-171031223004/75/Hardware-Acceleration-of-Apache-Spark-on-Energy-Efficient-FPGAs-with-Christoforos-Kachris-5-2048.jpg)
![Amazon Resources
7
Amazon
Machine
Image (AMI)
Amazon FPGA
Image (AFI)
EC2 F1
Instance
CPU
Application
on F1
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
DDR-4
Attached
Memory
FPGA Link
PCIe
DDR
Controllers
Launch Instance
and Load AFI
[Source: Amazon AWS f1]](https://image.slidesharecdn.com/l28christoforoskachris-171031223004/75/Hardware-Acceleration-of-Apache-Spark-on-Energy-Efficient-FPGAs-with-Christoforos-Kachris-7-2048.jpg)
![FPGAs in Amazon AWS
8
Amazon EC2 FPGA
Deployment via Marketplace
Amazon
Machine
Image (AMI)
Amazon FPGA Image
(AFI)
AFI is secured, encrypted,
dynamically loaded into the
FPGA - can’t be copied or
downloaded
Customers
AWS Marketplace
[Source: Amazon AWS f1]](https://image.slidesharecdn.com/l28christoforoskachris-171031223004/75/Hardware-Acceleration-of-Apache-Spark-on-Energy-Efficient-FPGAs-with-Christoforos-Kachris-8-2048.jpg)
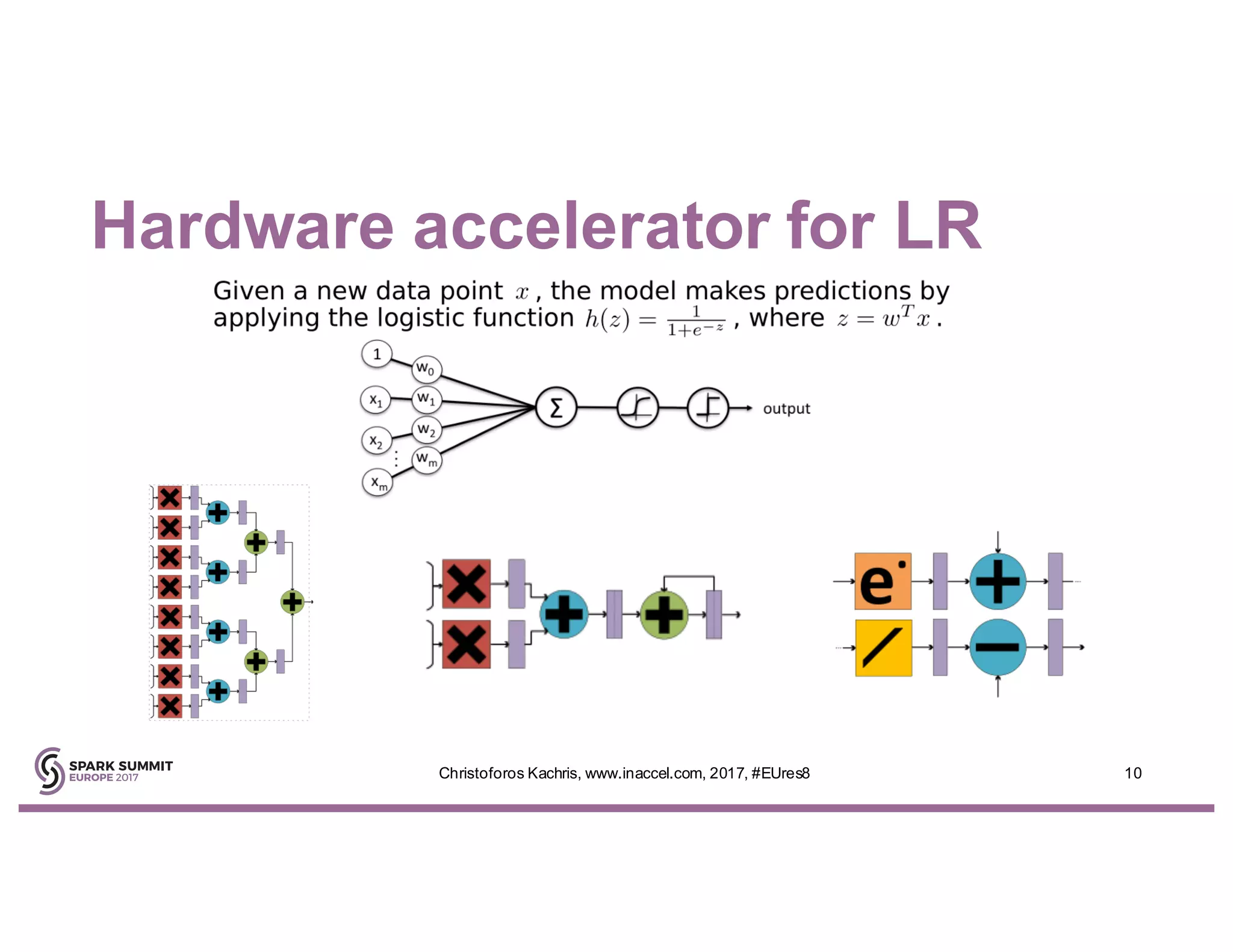
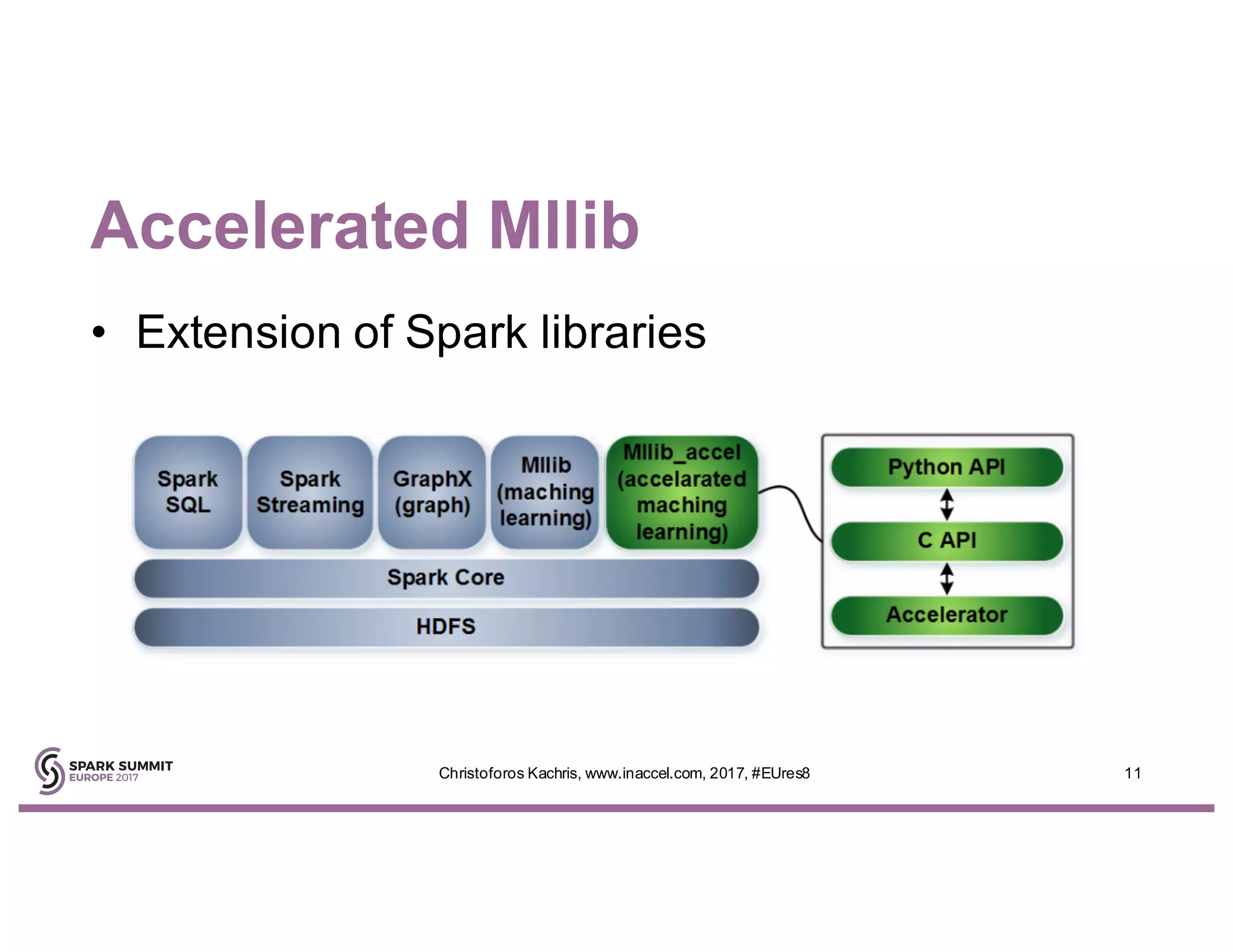
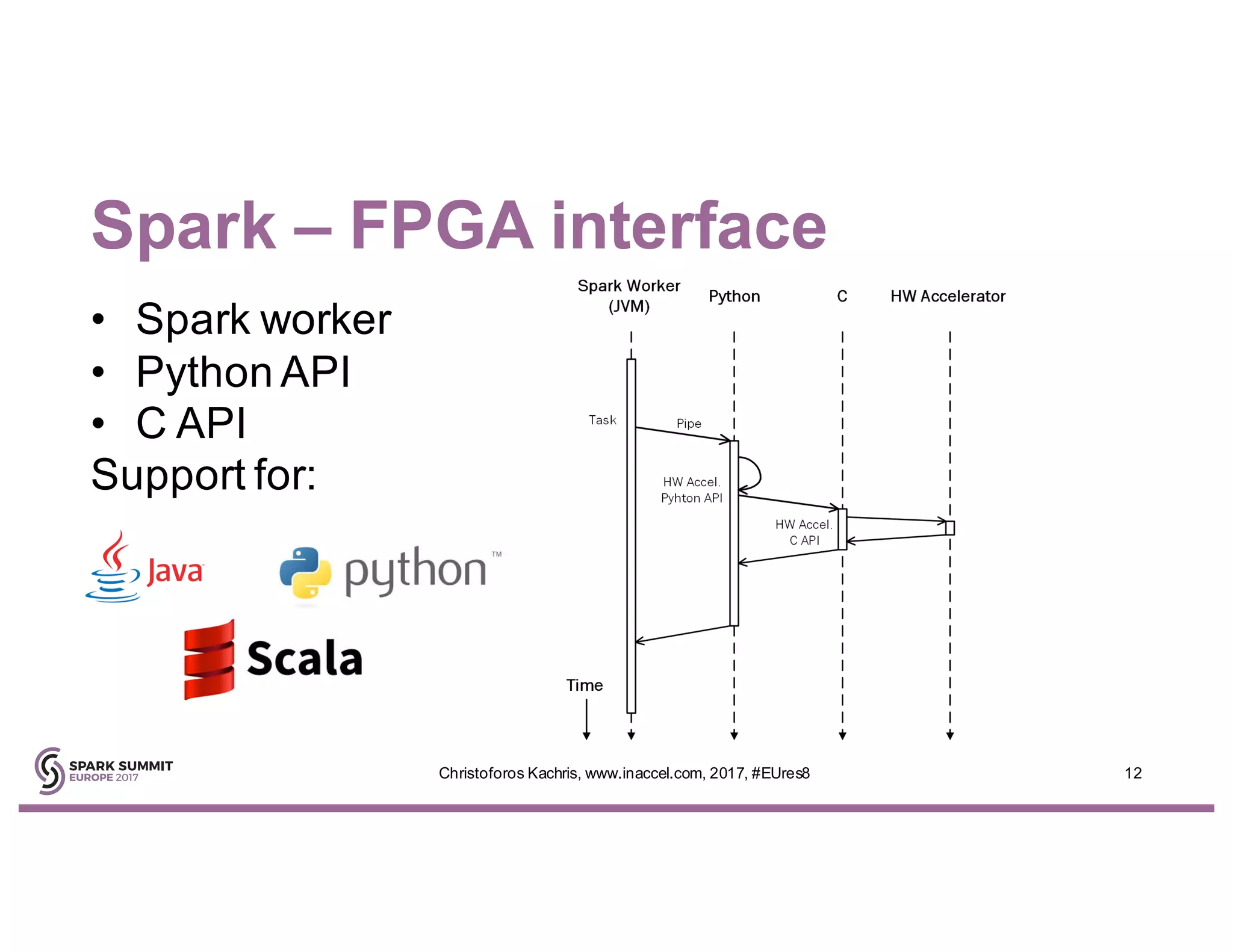



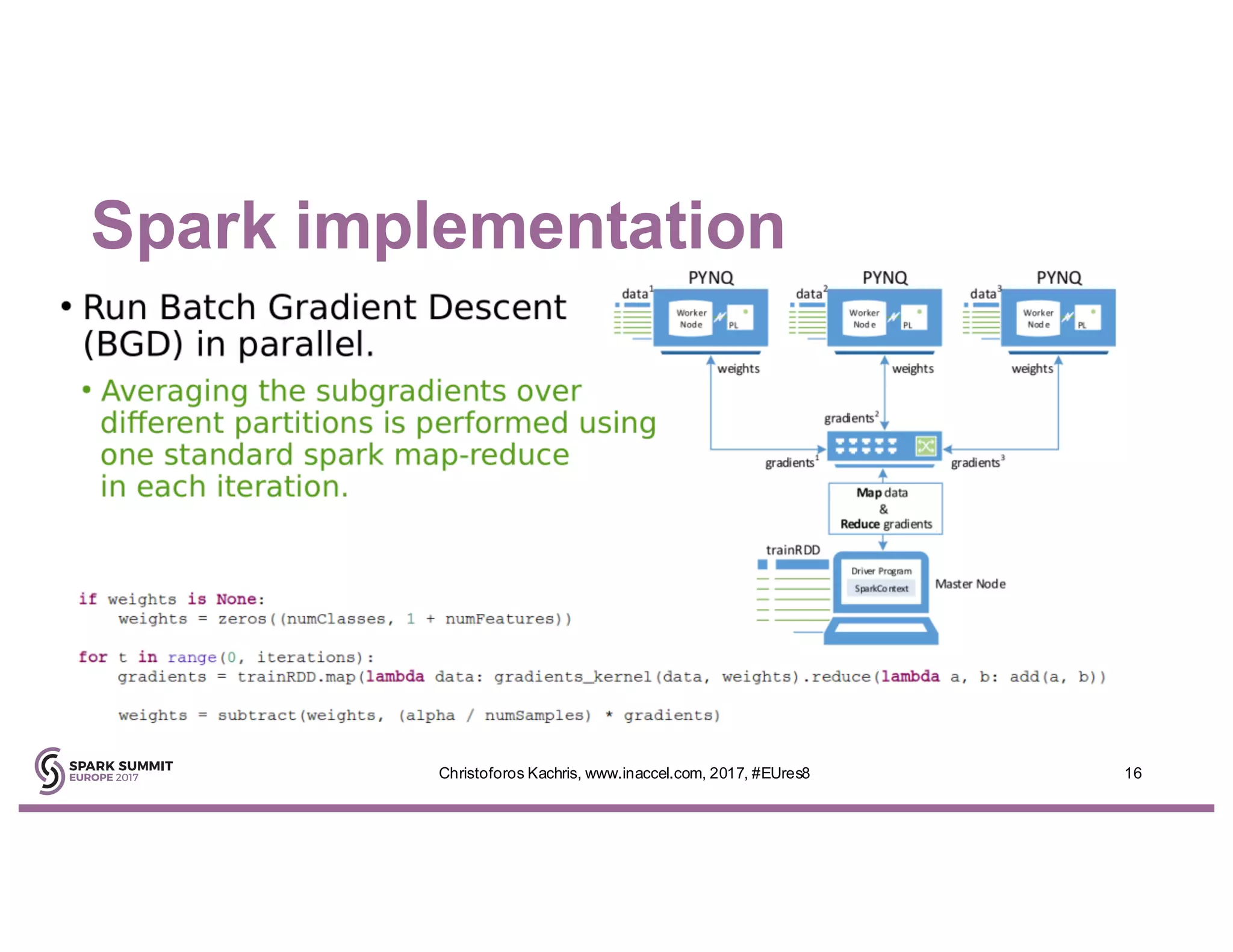

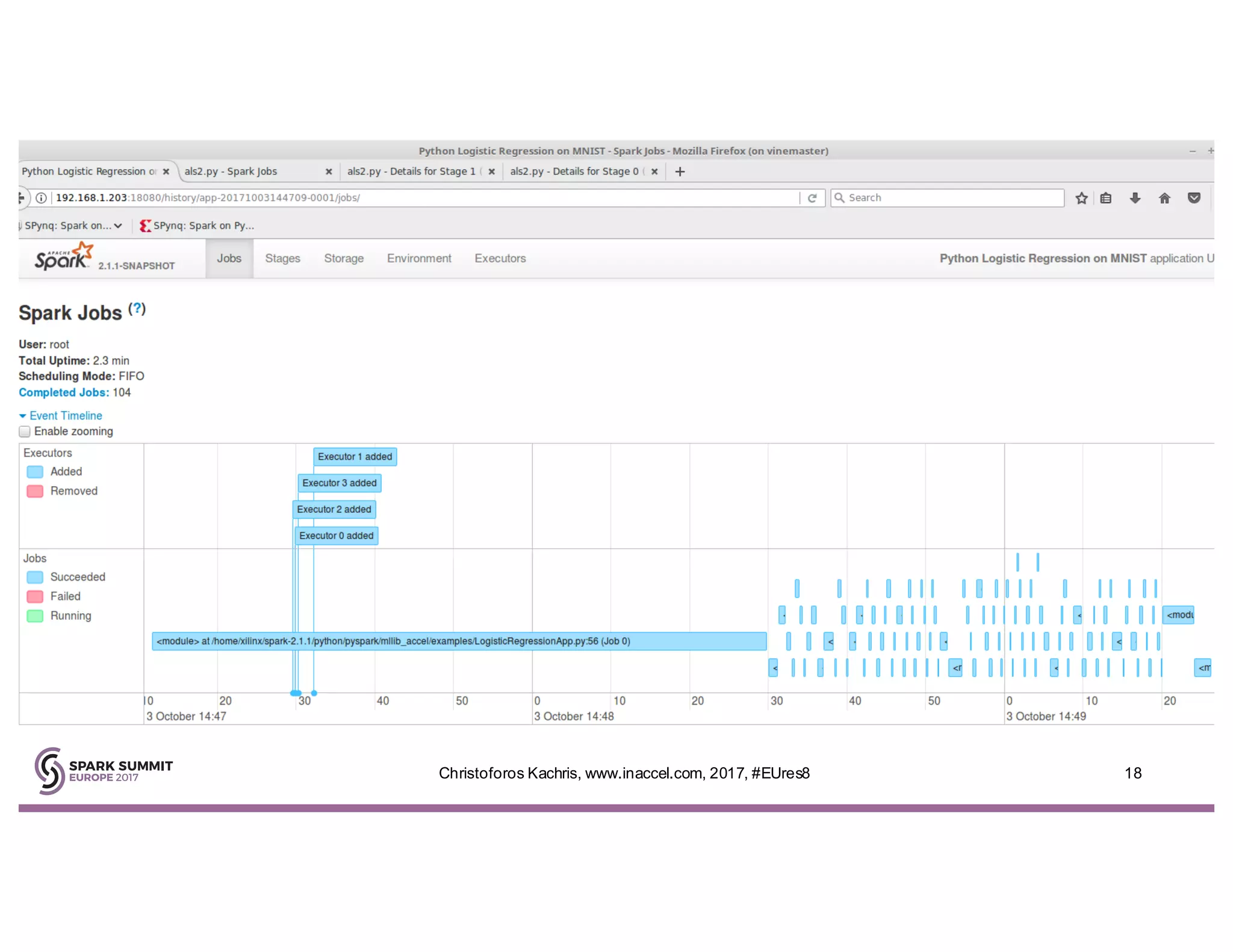
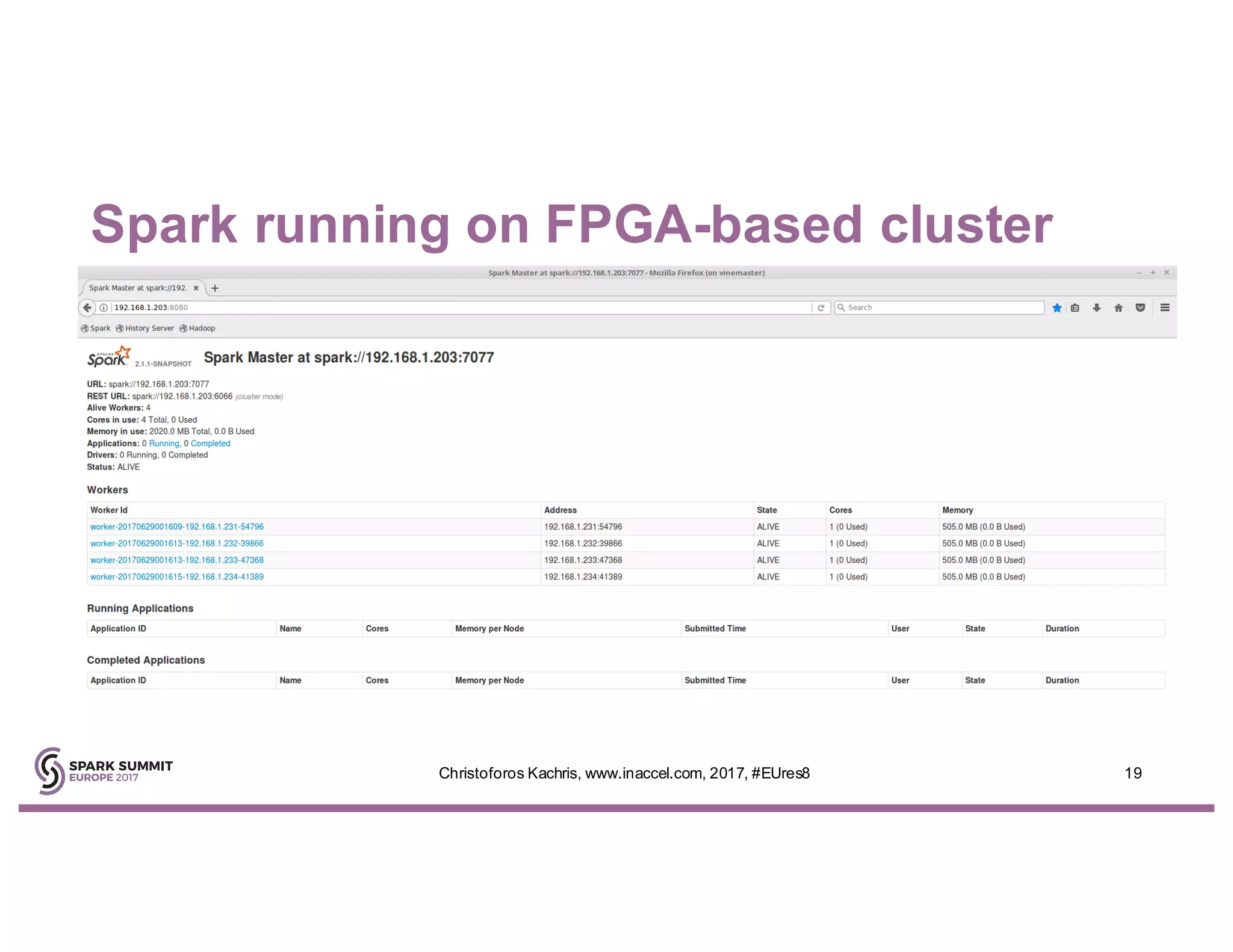
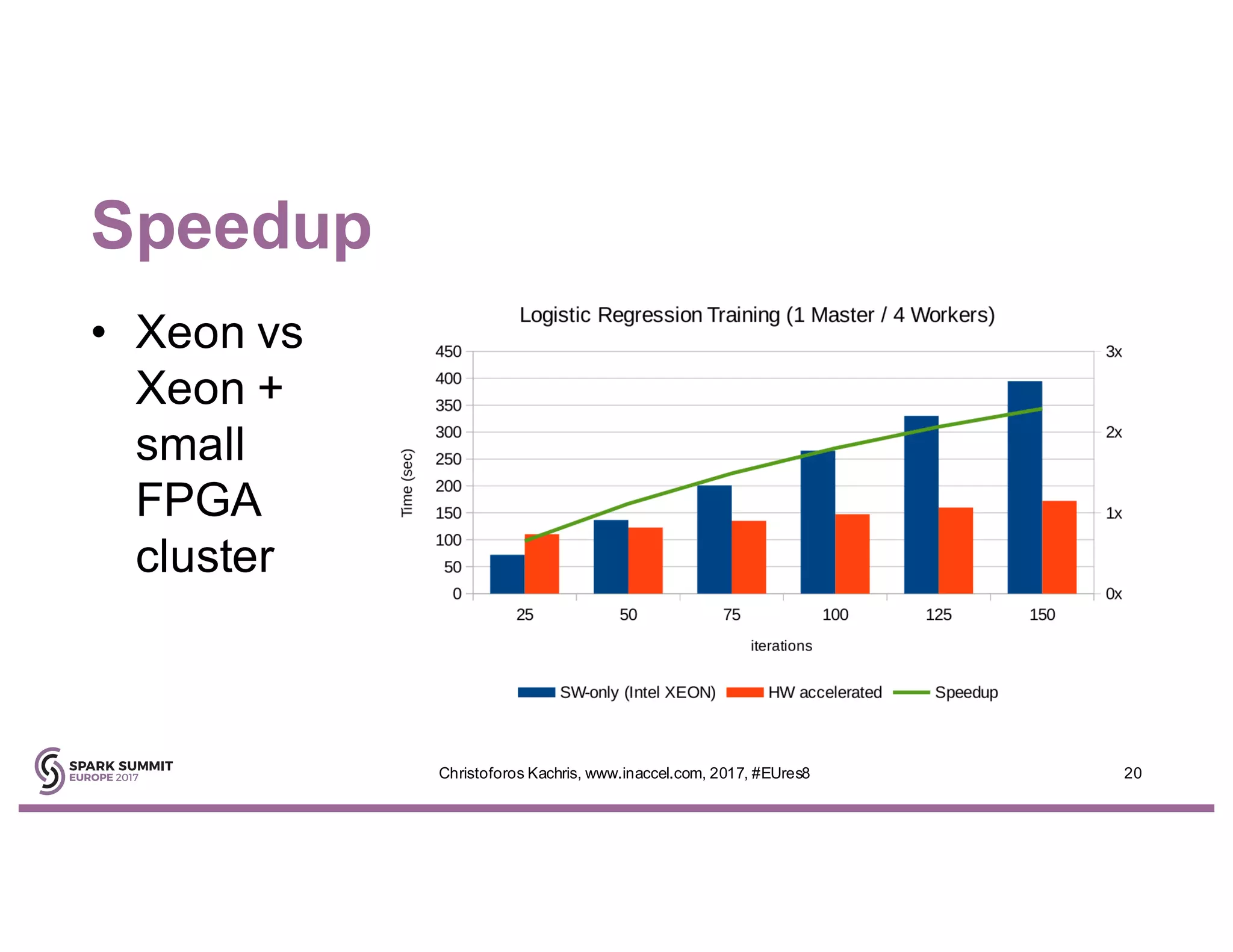

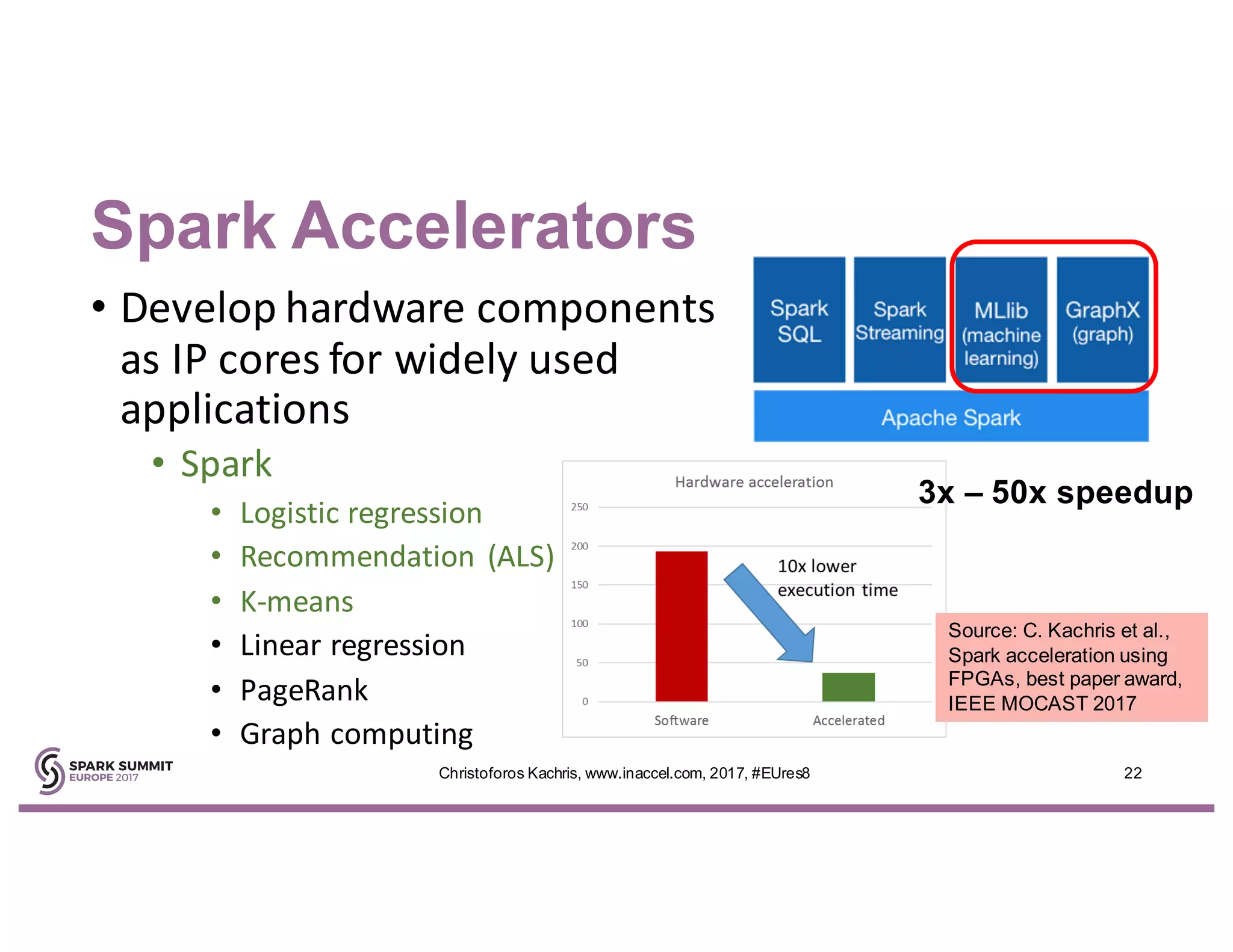


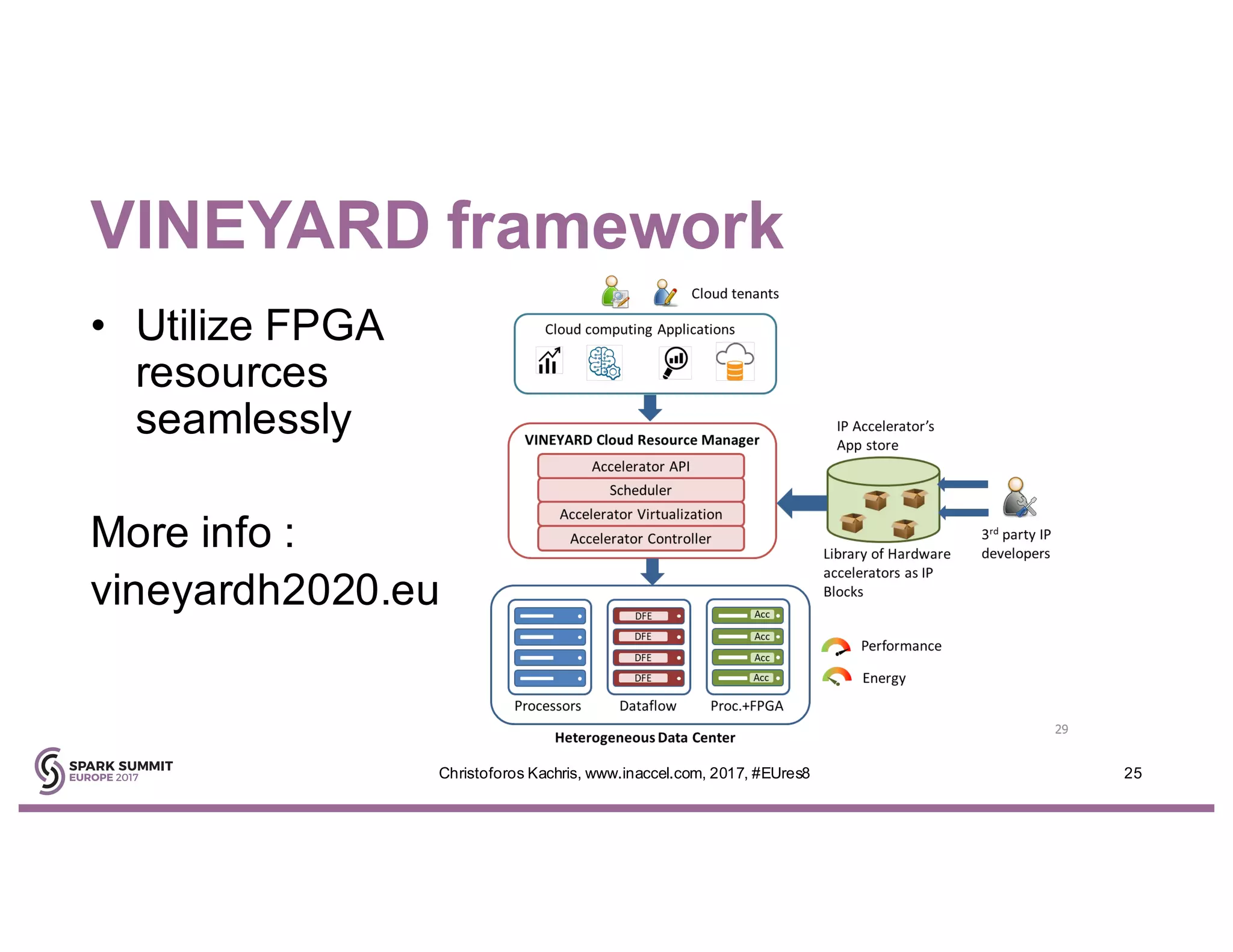


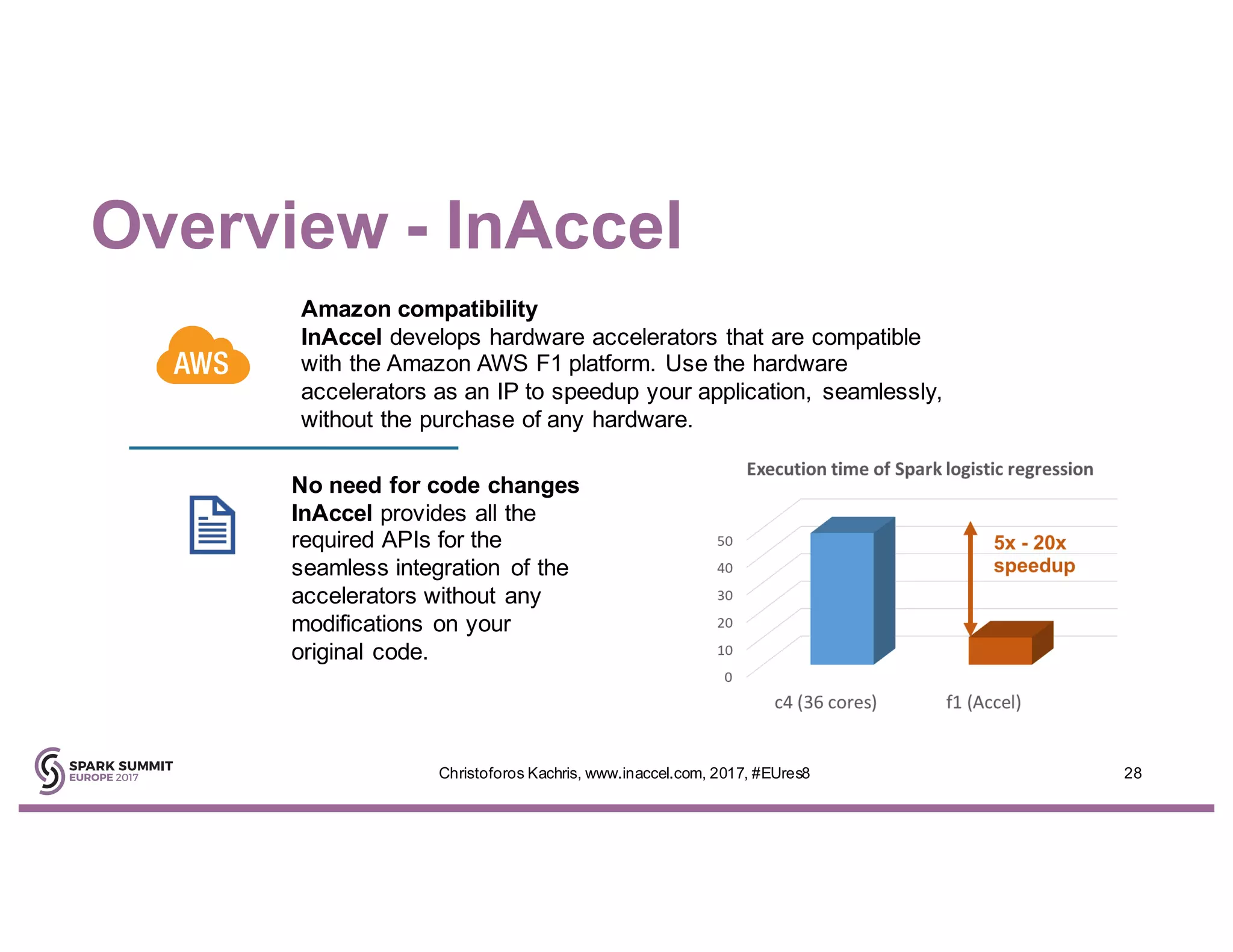
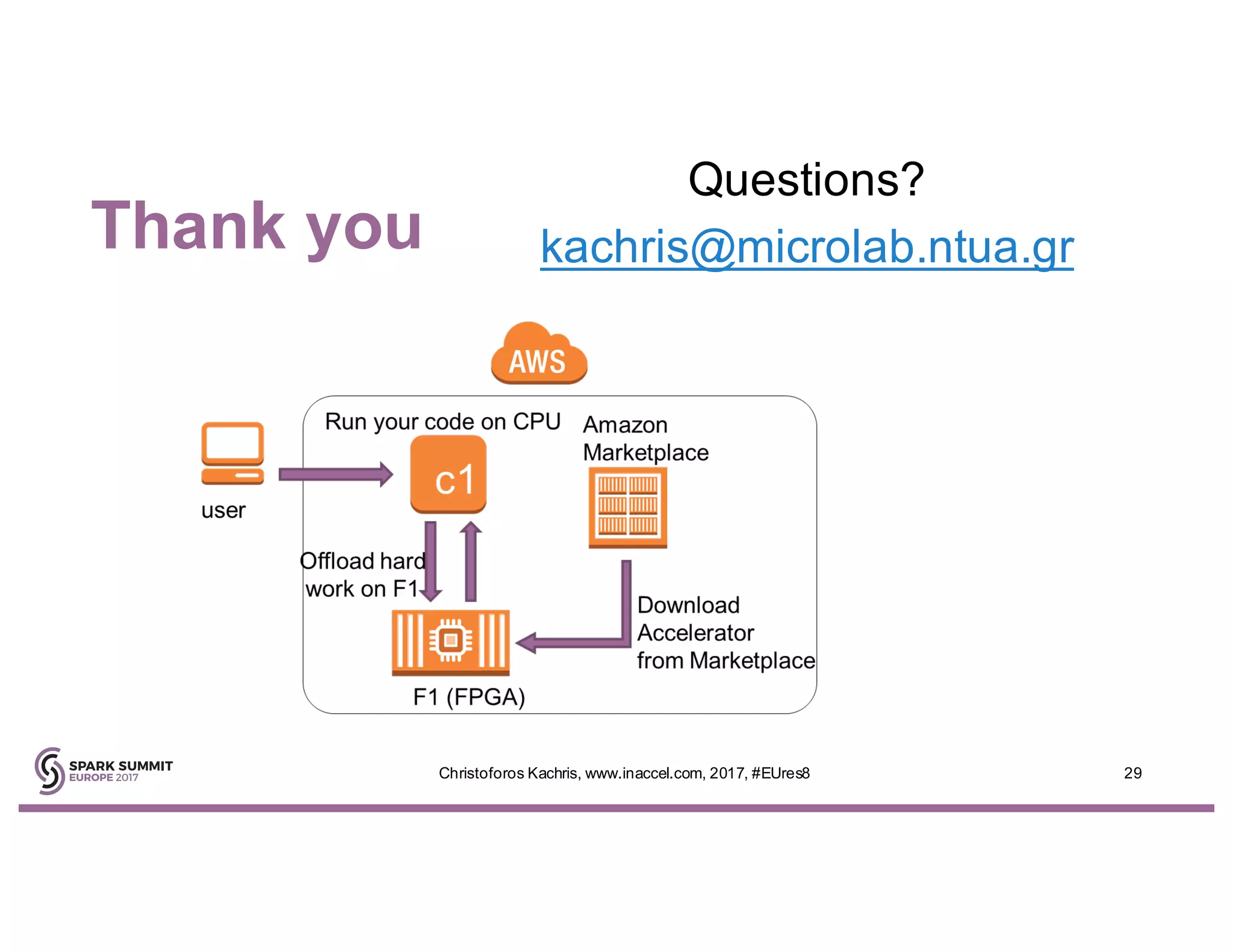

The document discusses the use of FPGA accelerators to enhance the performance of Spark applications on the cloud, particularly in machine learning tasks such as logistic regression and digit recognition. It highlights the advantages of combining CPUs with FPGAs for improved efficiency and speedup compared to traditional setups, showcasing significant performance gains. Inaccel's hardware accelerators facilitate seamless integration with Apache Spark and Amazon AWS, allowing users to enhance their applications without the need for extensive code modifications.






































































![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
