Download as PDF, PPTX













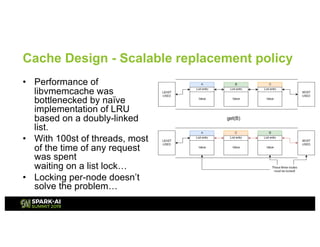
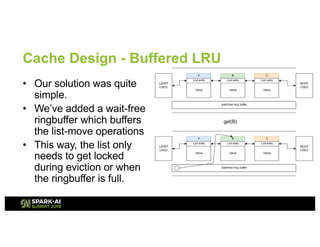
![Cache Design - Lightweight, embeddable,
in-memory caching
https://github.com/pmem/vmemcache
VMEMcache *cache = vmemcache_new("/tmp", VMEMCACHE_MIN_POOL,
VMEMCACHE_MIN_EXTENT, VMEMCACHE_REPLACEMENT_LRU);
const char *key = "foo";
vmemcache_put(cache, key, strlen(key), "bar", sizeof("bar"));
char buf[128];
ssize_t len = vmemcache_get(cache, key, strlen(key),
buf, sizeof(buf), 0, NULL);
vmemcache_delete(cache);
libvmemcache has normal get/put APIs, optional replacement policy, and configurable extent size
Works with terabyte-sized in-memory workloads without a sweat, with very high space utilization.
Also works on regular DRAM.](https://image.slidesharecdn.com/012020chengxubalcerpiotr-190508180824/85/Accelerate-Your-Apache-Spark-with-Intel-Optane-DC-Persistent-Memory-23-320.jpg)
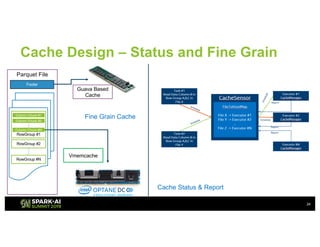
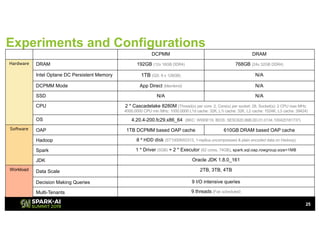
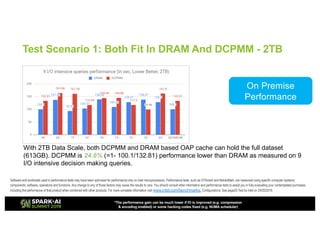
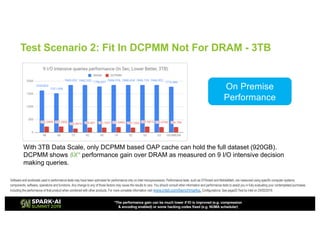
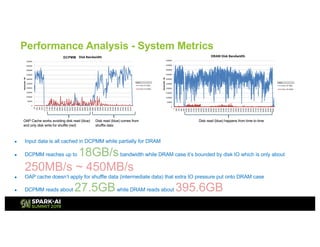
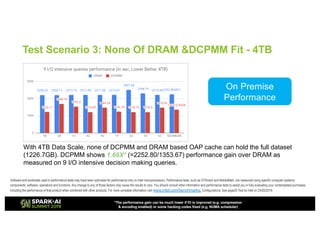


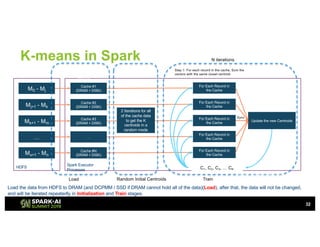
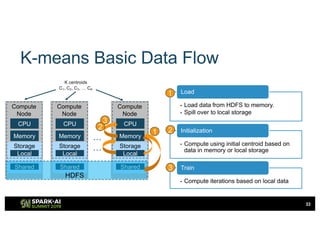
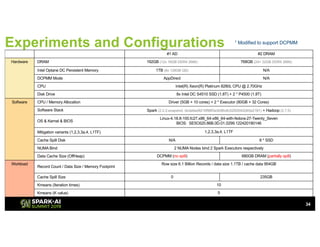
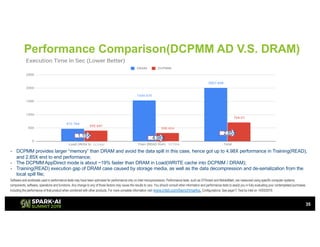
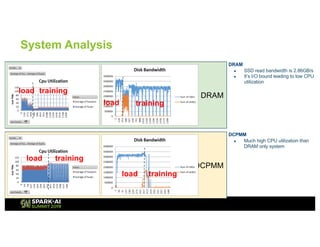




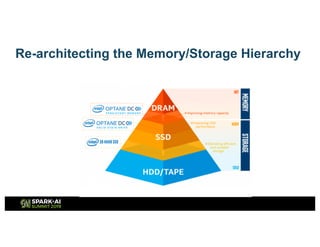
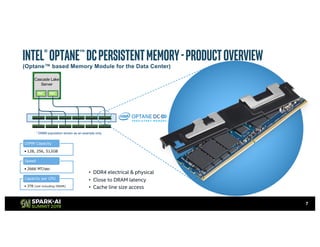
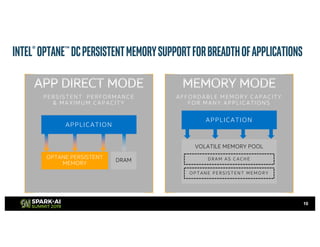
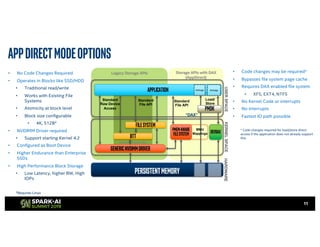
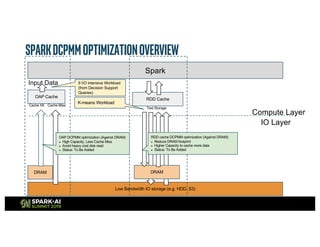
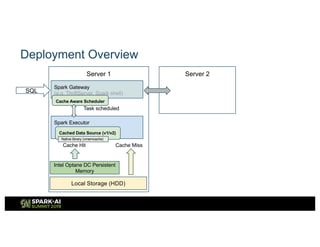
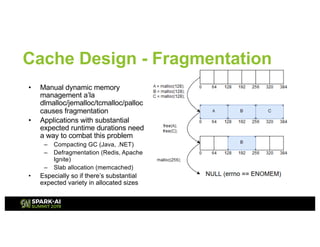
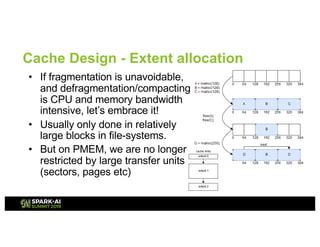
The document outlines Intel's offerings related to analytics solutions and persistent memory technologies, highlighting features like Intel Optane DC persistent memory and its compatibility with big data frameworks such as Spark. It discusses the performance of different memory configurations, emphasizing benchmarks and scenarios where persistent memory can significantly enhance workloads in data-intensive environments. Furthermore, it provides a technical overview of cache design, optimization strategies for Spark, and operational modes to improve data handling efficiency in various applications.























































































