Download to read offline


![4
Progress Meeting 12-12-14
Which Scale-out Framework ?
[Picture Courtesy: Amir H. Payberah]](https://image.slidesharecdn.com/bdcloudpresentation-160205170024/85/Performance-Characterization-of-In-Memory-Data-Analytics-on-a-Modern-Cloud-Server-4-320.jpg)

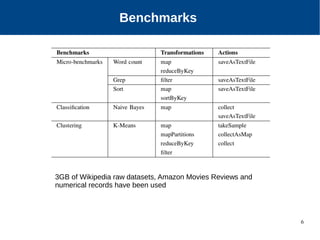
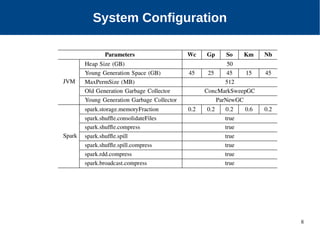
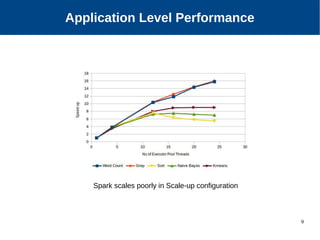
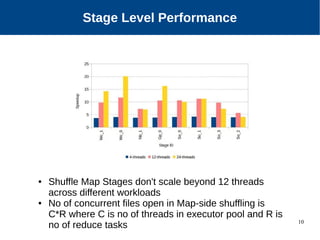
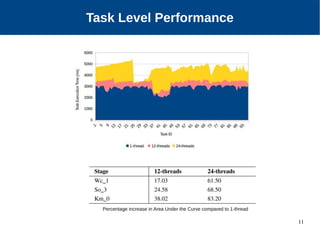
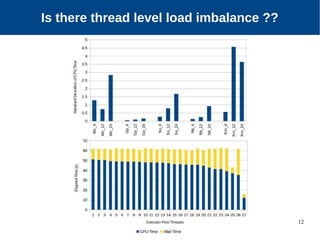
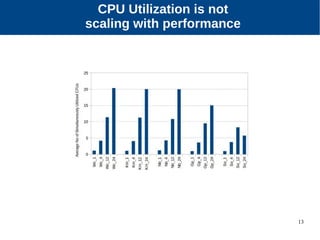
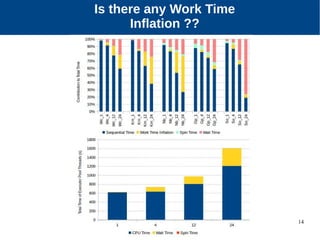
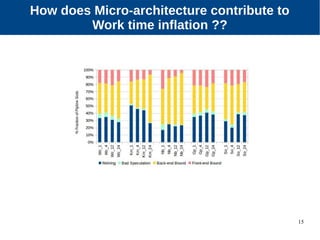
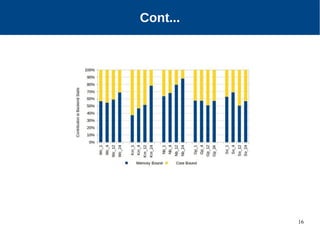

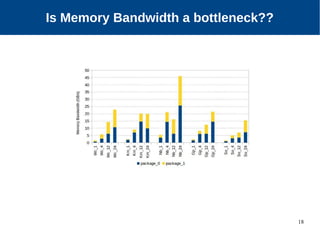



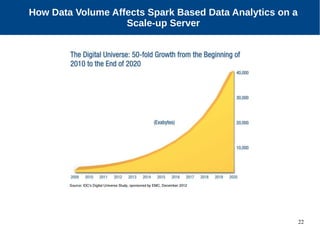
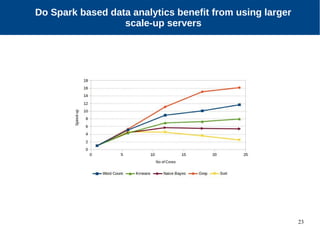
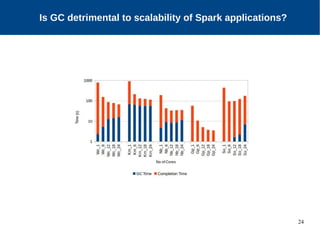
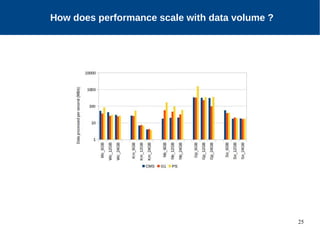
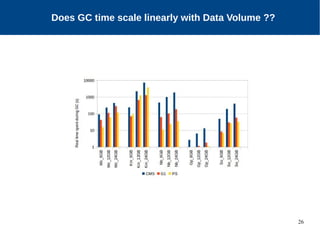
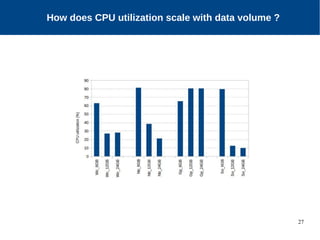
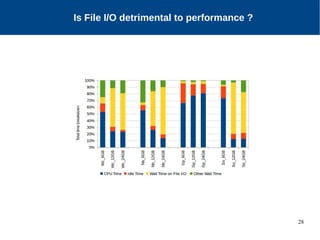
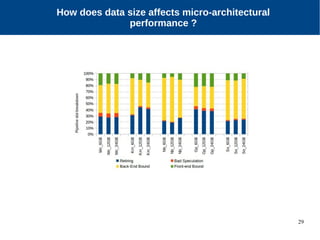
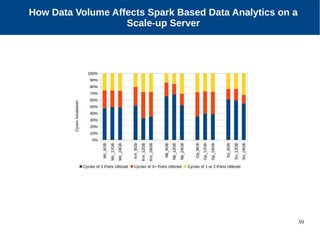
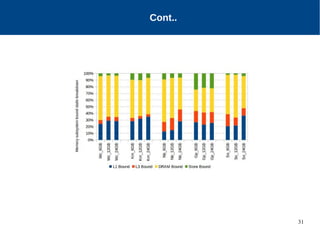
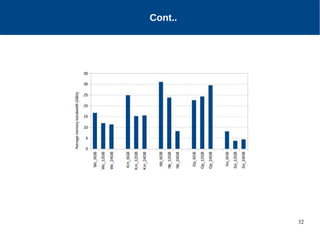




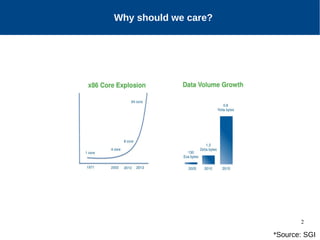
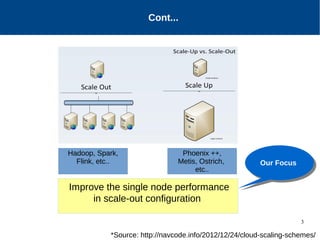
The document discusses the performance characterization of in-memory data analytics on cloud servers, focusing on improving single node performance in scale-out configurations. Key findings reveal that Spark's scalability is hindered by load imbalance and work time inflation, with optimal executor pool threads not exceeding 12 for significant performance gains. Future directions include enhancing task scheduling and optimizing memory architectures to address identified bottlenecks.





















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

