Download as PDF, PPTX




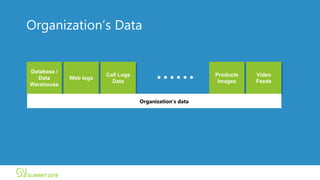
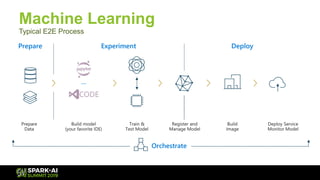




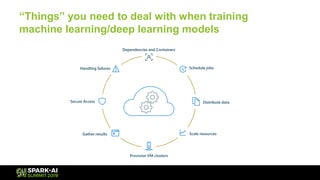
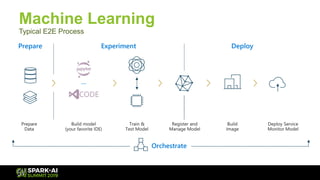
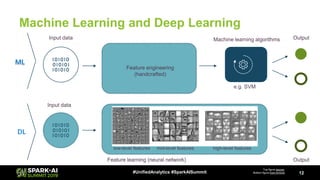

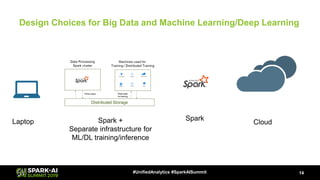
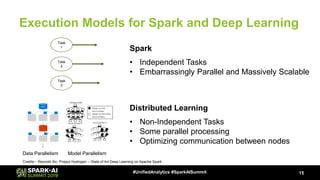
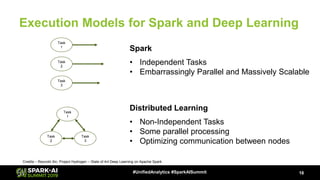
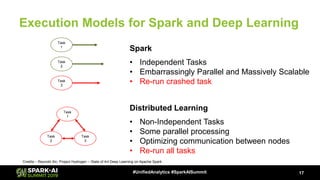


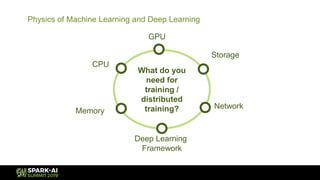
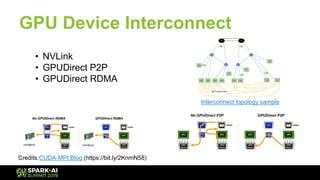
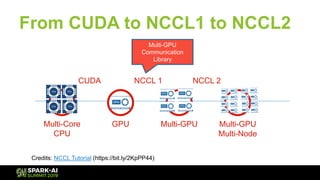
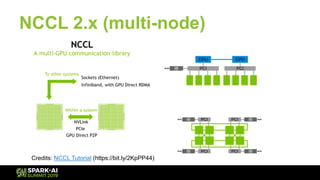
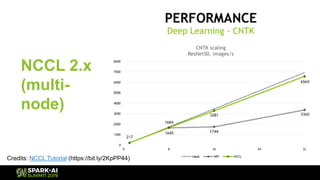


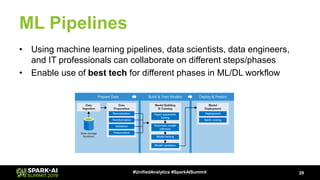

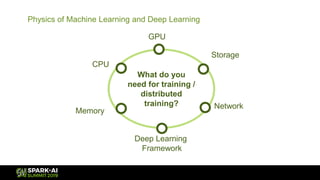



The document discusses Microsoft's infrastructure for deep learning using Apache Spark, covering topics such as data preparation, model training, and the challenges of distributed deep learning. It highlights performance improvements in model training times with advanced GPU setups and outlines design considerations for machine learning workflows at scale. The presentation also addresses job execution, resource management, and collaboration among data scientists and engineers in the context of machine learning pipelines.



































































