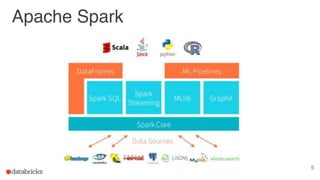
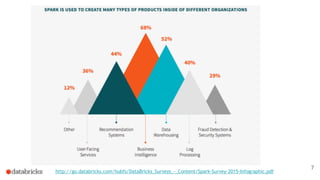
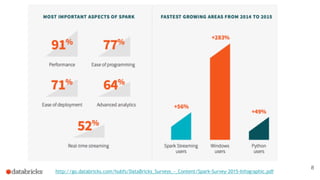
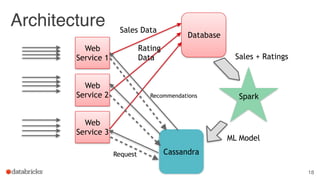
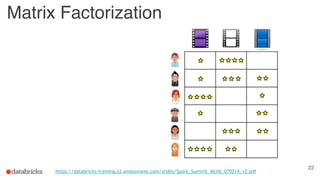
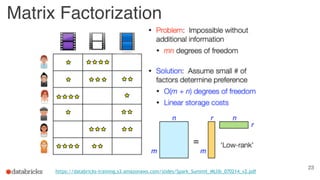
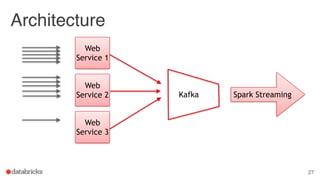
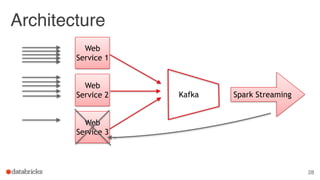
The document discusses building end-to-end data pipelines using Apache Spark, detailing the steps from understanding data to creating services and monitoring them. It highlights the Spark ecosystem, its contributions, and the tools available, including Spark SQL, MLlib, and Spark Streaming. The presentation also illustrates a scenario of implementing a recommendation engine for an e-commerce application using matrix factorization techniques.