


















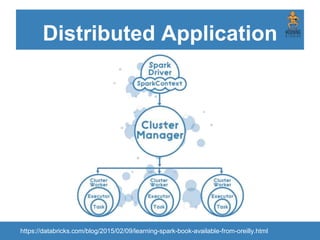
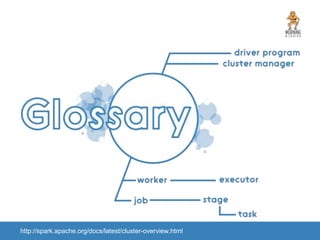

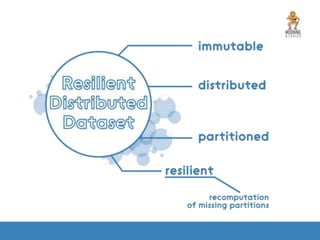



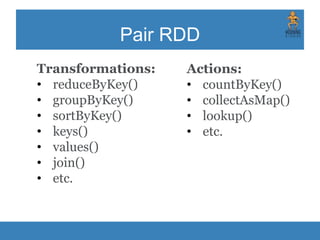










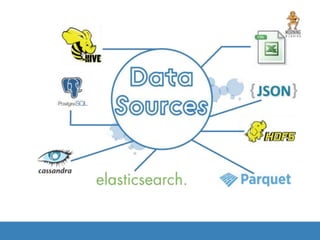


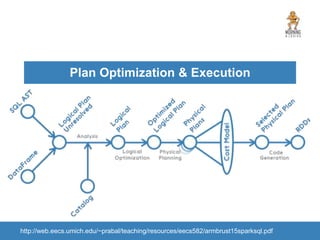



























The document provides an introduction to Apache Spark, focusing on its features, capabilities, and advantages over traditional big data solutions like Hadoop. It covers key concepts, core abstractions, applications, and integrations with various technologies, emphasizing Spark's efficiency and speed due to in-memory data processing. Additionally, it highlights the importance of proper memory management and monitoring while working with Spark for large-scale data analytics.






























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)


