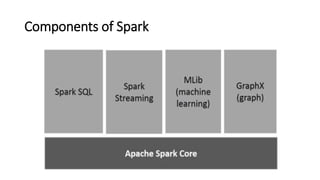
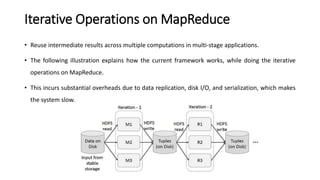
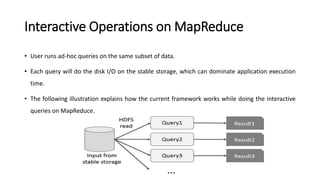
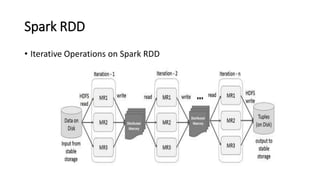
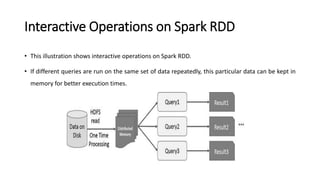
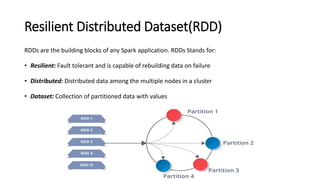
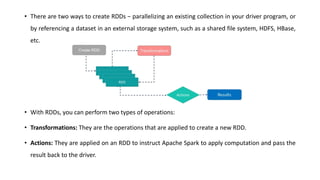
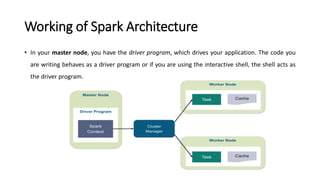
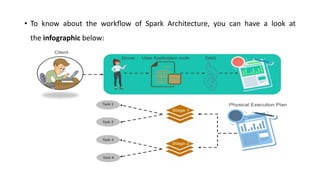
Spark is a fast, general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R for distributed tasks including SQL, streaming, and machine learning. Spark improves on MapReduce by keeping data in-memory, allowing iterative algorithms to run faster than disk-based approaches. Resilient Distributed Datasets (RDDs) are Spark's fundamental data structure, acting as a fault-tolerant collection of elements that can be operated on in parallel.