Download to read offline








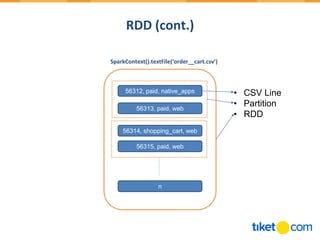
![RDD (cont.)
56312, paid, native_apps
56313, paid, web
56314, shopping_cart, web
56315, paid, web 56312, paid, native_apps
56313, paid, web
56315, paid, web
.filter(lambda line:line[1]==‘paid’)
.map(lambda line:(line[2],1))
(native_apps,1)
(web,2)
(native_apps,1)
(web,1)
(web,1)
.reduceByKey(lambda x,y:x+y)](https://image.slidesharecdn.com/sparkfromthesurface-180502071242/85/Spark-from-the-Surface-11-320.jpg)

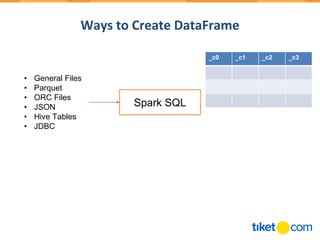

![Spark Dataset
• Introduced in Apache Spark 1.6, the goal of Spark Datasets was to provide an API
that allows users to easily express transformations on domain objects, while also
providing the performance and benefits of the robust Spark SQL execution engine.
As part of the Spark 2.0 release (and as noted in the diagram above), the
DataFrame APIs is merged into the Dataset API thus unifying data processing
capabilities across all libraries.
• Conceptually, the Spark DataFrame is an alias for a collection of generic objects
Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast,
is a collection of strongly-typed JVM objects, dictated by a case class, in Scala or
Java](https://image.slidesharecdn.com/sparkfromthesurface-180502071242/85/Spark-from-the-Surface-15-320.jpg)

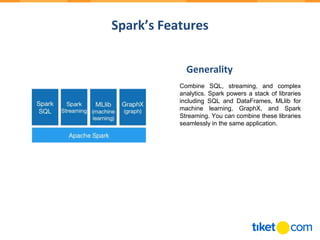
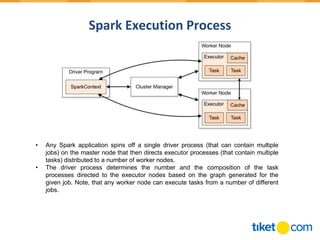
Apache Spark is an open-source distributed processing engine that is up to 100 times faster than Hadoop for processing data stored in memory and 10 times faster for data stored on disk. It provides high-level APIs in Java, Scala, Python and SQL and supports batch processing, streaming, and machine learning. Spark runs on Hadoop, Mesos, Kubernetes or standalone and can access diverse data sources using its core abstraction called resilient distributed datasets (RDDs).



































































